面向弱监督指向性视觉理解的图像描述预测方法
本发明属于图像处理,涉及弱监督指向性视觉理解,特别是涉及一种面向弱监督指向性视觉理解的图像描述预测方法。
背景技术:
1、参考表达理解(rec)旨在基于参考表达在图像中定位目标实例。作为跨模态识别任务,rec不限于一组固定的对象,理论上能够进行任何开放式检测。这些吸引人的特性使其越来越受到工业界和学术界的关注。然而,昂贵的实例级别标注长期限制着它的发展。
2、在目前的方法和文献中,大多将两阶段目标检测器如fasterrcnn扩展到弱监督rec任务,他们将rec任务视为区域文本排序问题,其中图像的显着区域首先由faster-rcnn提取,然后通过跨模态匹配对区域进行排序。为了实现弱监督训练,他们仅使用表达式作为监督信息,并通过语义重建或跨模态对比学习来优化排序匹配模块。然而,由于fasterrcnn的内在特性,这些方法在推理速度上往往较差,类似于现有的两阶段rec模型。
技术实现思路
1、本发明的目的在于针对现有技术存在的上述问题,提供一种面向弱监督指向性视觉理解的图像描述预测方法。
2、为了达成上述目的,本发明的技术方案是:
3、一种面向弱监督指向性视觉理解的图像描述预测方法,用于根据rgb图像和描述语言,在没有真实标记框标注的情况下训练出一个模型,实现在rgb图像中定位描述语言指代的对象;包括如下步骤:
4、步骤1,设置输入的rgb图像的大小为416×416×3,描述语言的最长文本输入设置为15;
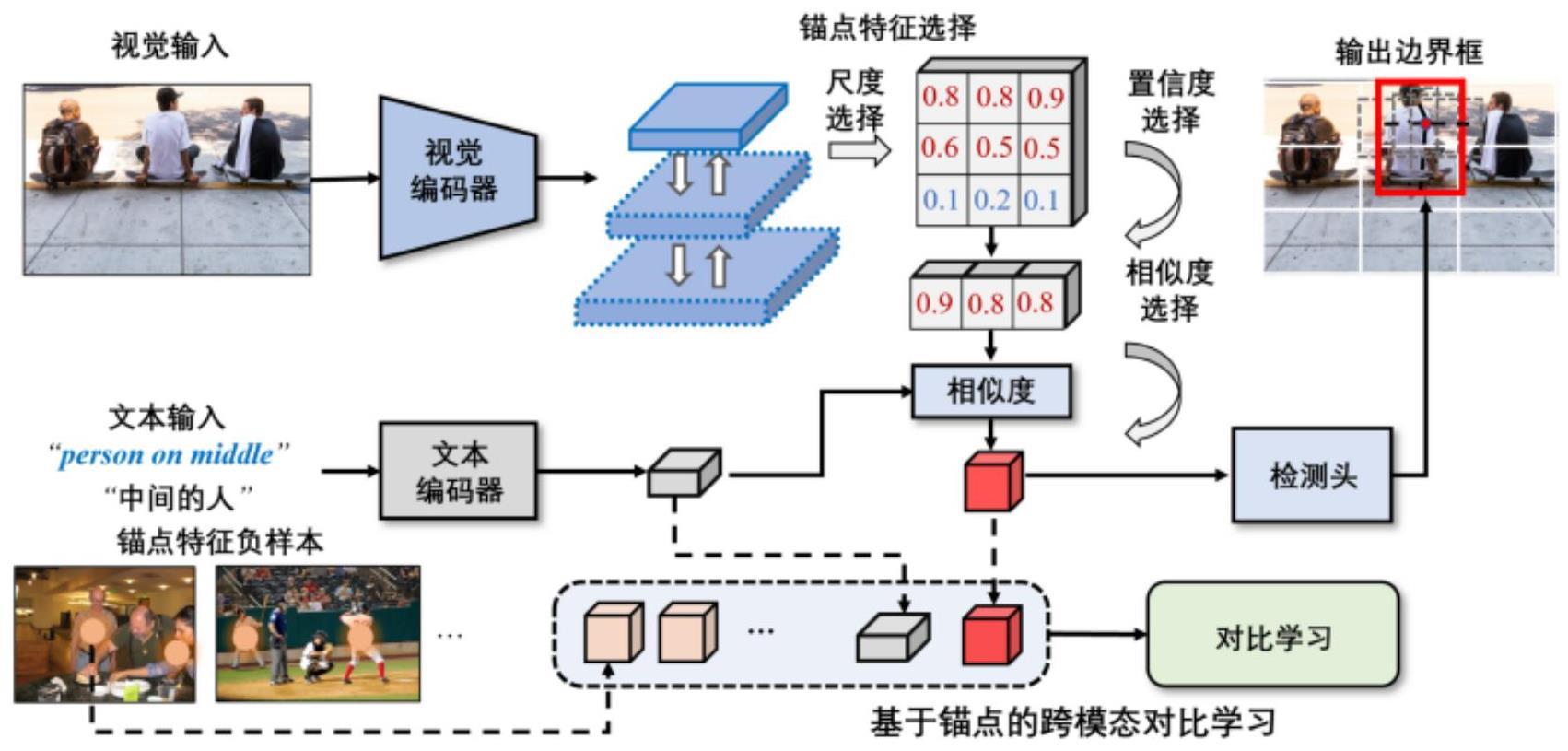
5、步骤2,分别获取rgb图像在三个尺度的视觉特征;
6、步骤3,将三个尺度的视觉特征通过多尺度的融合,将视觉特征先后通过尺度选择和置信度选择,选择13×13尺度的特征,根据box置信度过滤掉90%的低置信度特征,得到候选锚点特征
7、步骤4,利用全连接层将候选锚点特征和文本特征投影到相同的维度,得到和
8、步骤5,在训练过程中,对于一个batch的图文对数据,给定文本,分别计算不同图片中候选锚点和文本对应的相似度,对于匹配的图文对,选择其中相似度最高的锚点文本对作为正样本,对于不匹配的图文对,按相似度取相似度排名前2的锚点文本对作为负样本,通过锚点文本之间的对比学习实现语义和文本之间的对齐;
9、步骤6,在预测过程中,给定图片文本对,计算文本和图片中候选锚点之间对应的相似度,选择最高的锚点,根据其索引得到对应的预测box,将其中置信度最高的box作为目标box输出。
10、在步骤2中,所述分别获取rgb图像在三个尺度的视觉特征,是利用在coco目标检测数据集上训练好的yolov3作为视觉编码器,得到rgb图像在三个尺度的视觉特征:和对应的box,分别记为其中,na代表每个锚点预定义box的数量,c中记录box的预测结果,包括置信度信息和box偏移,以及描述语言的语言特征:
11、在步骤3中,所述将视觉特征先后通过尺度选择和置信度选择,锚点特征置信度的计算公式为:
12、
13、其中,i∈[0,13],j∈[0,13],na代表每个位置预定义box的数量。
14、在步骤5中,所述通过锚点文本之间的对比学习实现语义和文本之间的对齐,使用锚点和文本之间进行对比学习,同时通过基于相似度的采样实现负样本的扩充,所用的损失函数的计算方法是:
15、
16、其中,是从batch中采样的锚点,是对于图像文本对i的正样本;n和m分别表示每个图像的负锚点数和batch大小;τ是温度系数。
17、在神经网络的训练过程中,使用adam优化器,设置初始学习率和batchsize分别为0.0001和64。
18、本发明利用锚点和文本之间的对比学习进行弱监督指向性视觉理解任务。利用单阶段目标检测进行任务建模会出现预测框过于密集,噪声过大的问题;同时,传统对比学习中负样本的选择往往受到batchsize大小的限制,这些都影响检测的精度。
19、本发明rgb图像通过预训练的yolov3主干网络得到三个尺度的视觉特征即锚点特征及其对应的预测框,三个尺度的视觉特征首先进行多尺度的融合,随后通过尺度过滤,置信度过滤,得到候选锚点特征,最后将候选锚点特征和对应文本特征进行相似度计算。在训练时,优化目标是最大化匹配图文对中锚点特征和对应文本之间的最高相似度得分,最小化不匹配图文对中锚点特征和文本之间的相似度得分,从而实现缺乏真实边界框标注条件下图片与语义的对齐。在预测时,选择和文本相似度最高的锚点特征,根据其索引找到对应的预测框,选择置信度最高的预测框作为目标边界框输出。
20、与现有技术相比,本发明的创新点体现在:
21、(1)本发明提出一种新颖的单阶段对比模型实现弱监督rec。通过单阶段建模,我们不需要背景技术中较为耗时的感兴趣区域池化和非极大值抑制处理操作,从而将推理速度大幅提升5倍。
22、(2)本发明采用单阶段目标检测器进行建模,将弱监督rec任务重新定义为锚点选择问题。本发明采用尺度选择和置信度过滤方法,有效减少候选锚点的数量,减少其中的噪声;并基于相似度采样多个锚点进行负样本扩充,使其不受batchsize大小的限制,从而有效提高了模型的检测性能,达到了最先进的水平。
技术特征:
1.面向弱监督指向性视觉理解的图像描述预测方法,其特征在于包括如下步骤:
2.如权利要求1所述面向弱监督指向性视觉理解的图像描述预测方法,其特征在于在步骤2中,所述分别获取rgb图像在三个尺度的视觉特征,是利用在coco目标检测数据集上训练好的yolov3作为视觉编码器,得到rgb图像在三个尺度的视觉特征:和对应的box,分别记为其中,na代表每个锚点预定义box的数量,c中记录box的预测结果,包括置信度信息和box偏移,以及描述语言的语言特征:
3.如权利要求1所述面向弱监督指向性视觉理解的图像描述预测方法,其特征在于在步骤3中,所述将视觉特征先后通过尺度选择和置信度选择,锚点特征置信度的计算公式为:
4.如权利要求1所述面向弱监督指向性视觉理解的图像描述预测方法,其特征在于在步骤5中,所述通过锚点文本之间的对比学习实现语义和文本之间的对齐,使用锚点和文本之间进行对比学习,同时通过基于相似度的采样实现负样本的扩充,所用的损失函数的计算方法是:
5.如权利要求1所述面向弱监督指向性视觉理解的图像描述预测方法,其特征在于在步骤5中,所述训练过程中,使用adam优化器,设置初始学习率和batchsize分别为0.0001和64。
技术总结
面向弱监督指向性视觉理解的图像描述预测方法,涉及图像处理。RGB图像通过预训练的YoloV3主干网络得三个尺度视觉特征即锚点特征及其对应的预测框,多尺度融合,尺度过滤、置信度过滤得到候选锚点特征,候选锚点特征和对应文本特征相似度计算。训练时,优化目标是最大化匹配图文对中锚点特征和对应文本之间最高相似度得分,最小化不匹配图文对中锚点特征和文本之间相似度得分,实现缺乏真实边界框标注条件下图片与语义对齐。预测时,选择和文本相似度最高的锚点特征,根据索引找到对应预测框,选择置信度最高的预测框作目标边界框输出。减少候选锚点数量,减少噪声,不受batchsize大小限制,采用单阶段建模,有效提升推理速度。
技术研发人员:纪荣嵘,孙晓帅,周奕毅,金磊
受保护的技术使用者:厦门大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!