一种人体姿态估计行为分析方法
本发明涉及姿态估计,具体而言,尤其涉及一种人体姿态估计行为分析方法。
背景技术:
1、人体姿态估计是计算机视觉中的一个重要分支,应用范围宽广,通过将图片中已检测到的人体关键点正确的联系起来,从而估计人体姿态。人体关键点通常对应人体上有一定自由度的关节,比如颈、肩、肘、腕、腰、膝、踝等,比如在自动驾驶行业进行街景中行人的姿态检测、动作预测;在安防领域的行人再识别问题,特殊场景的特定动作监控;影视产业的电影特效等。
2、公开号为cn114999002a的中国专利申请公开了一种融合人体姿态信息的行为识别方法,该发明虽然稳定性强,克服了图卷积神经网络的识别能力很受骨骼点坐标点平移的影响,另外融合了图像前后帧的信息与人体关键点信息,信息的融合帮助提升动作识别的性能,但是需要人工设置参数,以降低神经网络寻找参数的效率以及精确性,需要具有一定经验的技术人员操作,不方便普通人员使用。
技术实现思路
1、本发明提供一种人体姿态估计行为分析方法。本发明基于上传的多组姿态数据自动获取最优参数设置估计网络,进而进行姿态预测,无需人工设置参数,同时提高了神经网络寻找参数的效率以及精确性,操作简单,方便工作人员使用。
2、本发明采用的技术手段如下:
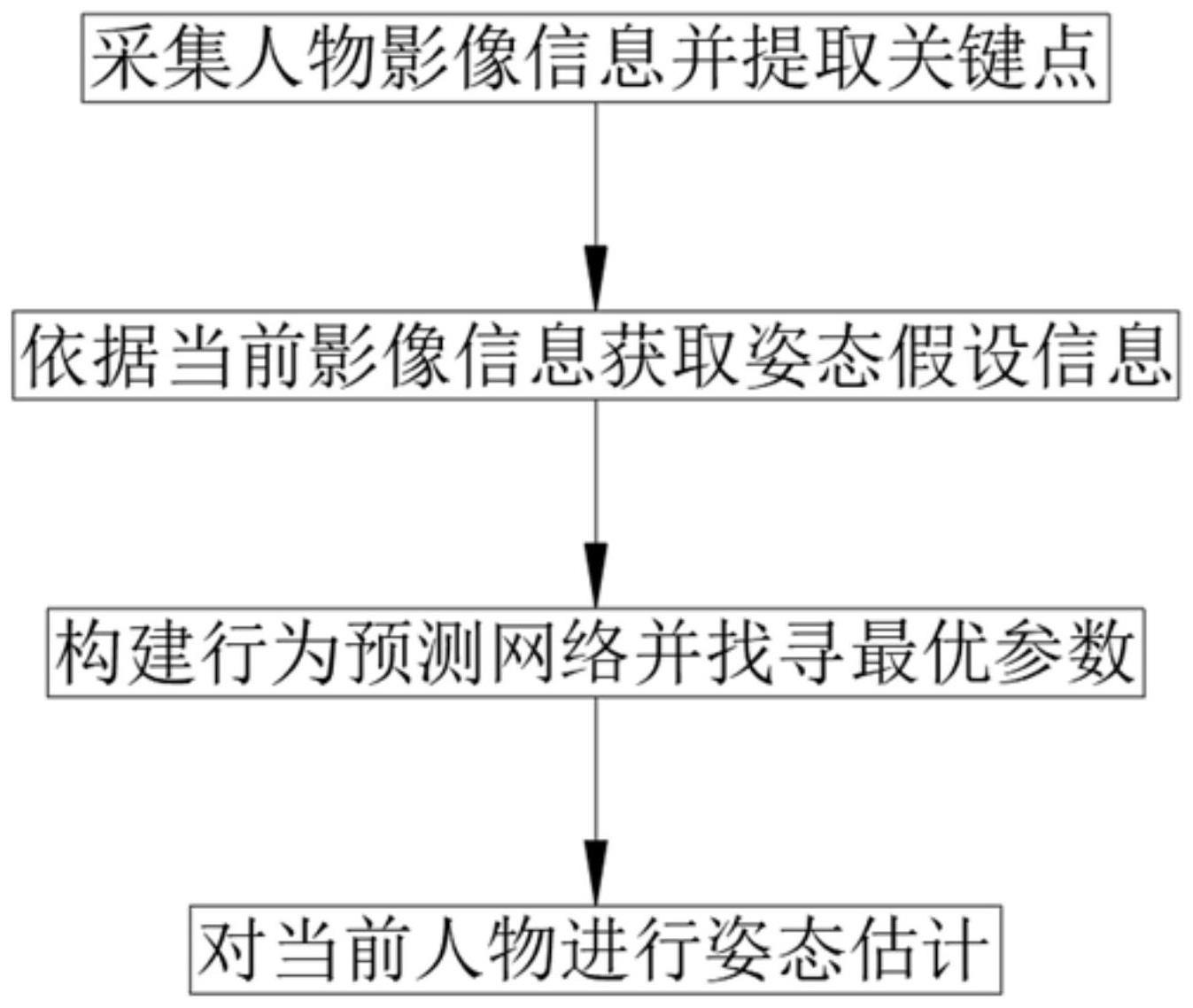
3、一种人体姿态估计行为分析方法,包括:
4、s1、将人物影像信息处理为图片数据,对所述图片数据进行预处理后,获取各组图片的全局姿态特征,基于所述全局姿态特征获取具有人体二维关键点信息的图像帧序列;
5、s2、离线处理固定帧率的单相机视频或图像序列帧,建立运动模型,对图像帧序列中的任务运动状态进行估计以获取2d姿态数据,构建transformer模型并基于transformer模型的多假设生成器对所述2d姿态数据进行处理生成姿态假设,对各组姿态假设进行回归生成姿态假设信息;
6、s3、构建行为预测网络,并基于预收集的多组姿态数据进行学习,获取网络的最优参数;
7、s4、将最优参数应用于行为预测网络,并基于行为预测网络对姿态假设信息进行预测,最终输出预测的姿态估计数据。
8、进一步地,对所述图片数据进行预处理,包括:
9、通过傅里叶正变换将各组图片数据从图像空间转换至频率空间,并对其高频成分进行滤波处理以降低噪音干扰;
10、然后通过傅里叶反变换将滤波后的各组图片数据由频率空间转换至图像空间。
11、进一步地,获取各组图片的全局姿态特征,基于所述全局姿态特征获取人体二维关键点,包括:
12、经过采集网络多次shuffleblock以得到各组图片数据的全局姿态特征;
13、通过反卷积操作使全局姿态特征回归至关键点特征图上;
14、对关键点特征图进行解码处理,并收集解码后生成的人体二维关键点。
15、进一步地,根据图像帧序列建立运动模型,对图像帧序列中的任务运动状态进行估计以获取2d姿态数据,构建transformer模型并基于transformer模型的多假设生成器对所述2d姿态数据进行处理生成姿态假设,对各组姿态假设进行回归生成姿态假设信息,包括:
16、s201、离线处理当前人物影像视频信息或图像序列帧,并对实际视频帧的间隔时间进行计算并记录,再依据卡尔曼滤波理论建立运动模型;
17、s202、对影像信息中所有人物分配一个的id,分配完成后,同时通过运动模型依据对人物的线性运动假设,对其在视频帧中的运动状态进行定义,收集各人物在当前视频帧中的运动状态,并构建预测方程对各跟踪目标在下一视频帧中的运动状态进行估计以获取2d姿态数据;
18、s203、构建transformer模型,并将2d姿态数据输入transformer模型中,在所述transformer模型中多假设生成器接收各组2d姿态数据,并在模型的不同层生成姿态假设的不同表示,然后通过多个并行的自注意力块对单假设依赖进行建模,以形成自我假设通信;
19、s204、混合假设mlp提取拼接起来的各个假设特征,并对其进行切块来得到修正后的每个假设,交叉假设交互器对不同假设的信息进行交互建模,最后通过transformer模型回归模块对各组姿态假设进行回归以得到最终3d姿态数据。
20、进一步地,构建行为预测网络,并基于预收集的多组姿态数据进行学习,获取网络的最优参数,包括:
21、s301、行为预测网络收集预上传的多组姿态数据,并从中选取一组作为验证数据,之后将剩余数据拟合成一组测试模型,在通过验证数据对该测试模型检测精度进行验证,之后更换验证数据重新进行验证,直至所有姿态数据都验证完成;
22、s302、初始化参数范围,并依据预先设置的学习率以及步长,同时列出所有可能的数据结果,对于每一组数据,选取任意一个子集作为测试集,其余子集作为训练集对测试模型进行训练,训练完成后对测试集进行预测,统计测试结果的均方根误差;
23、s303、同时将测试集更换为另一子集,再取剩余子集作为训练集,再次统计均方根误差,直至对所有数据都进行一次预测,通过选取均方根误差最小时对应的组合参数作为为数据区间内最优参数。
24、进一步地,将最优参数应用于行为预测网络,并基于行为预测网络对姿态假设信息进行预测,最终输出预测的姿态估计数据,包括:
25、s401、行为预测网络接收transformer模型生成的3d姿态数据,并将原始参数更换为最优参数,之后将当前影像信息中各人物的关键点信息导入行为预测网络中;
26、s402、将当前影像信息中各人物的关键点信息划分为训练集和测试集,并对训练集进行标准化处理,再将标准化处理生成的训练样本导入行为预测网络,同时采用长期迭代法训练该行为预测网络,并将测试集输入到训练好的模型中,输出3d姿态数据的预测百分比,并将最高的3d姿态数据作为预测结果输出。
27、较现有技术相比,本发明具有以下优点:
28、1、本发明提供的人体姿态估计行为分析方法相较于以往行为分析方法,通过行为预测网络收集工作人员上传的多组姿态数据,并从中选取一组作为验证数据,之后将剩余数据拟合成一组测试模型并对其检测精度进行验证,之后依据人工设定或系统默认设置学习率以及步长列出所有可能的数据结果,并对各组数据结果进行预测并记录各组数据均方根误差,同时选取均方根误差最小的组合参数作为最优参数,之后将将当前影像信息中各人物的关键点信息导入行为预测网络中以及transformer模型生成的3d姿态数据导入行为预测网络中进行姿态预测,并输出3d姿态数据的预测百分比,并将最高的3d姿态数据作为预测结果输出,无需人工设置参数,同时提高了神经网络寻找参数的效率以及精确性,操作简单,方便工作人员使用。
29、2、本发明提供的人体姿态估计行为分析方法通过对实际视频帧的间隔时间进行计算并记录,再依据卡尔曼滤波理论建立运动模型对人物在视频帧中的运动状态进行定义,并构建预测方程对各跟踪目标在下一视频帧中的运动状态进行估计以获取2d姿态数据,并将2d姿态数据输入transformer模型中,之后该模型中多假设生成器接收各组2d姿态数据,并在不同层生成姿态假设的不同表示,然后通过多个并行的自注意力块对单假设依赖进行建模,提取各个假设特征进行切块来得到修正后的每个假设,对不同假设的信息进行交互建模,最后通过transformer模型回归模块对各组姿态假设进行回归以得到最终3d姿态数据,通过transformer模型获取各人物的3d姿态预测数据,能够使工作人员更加直观的查看估计结果,提高工作人员使用体验,同时有利于后续人物姿态的预测,有效的提高了估计准确性。
- 还没有人留言评论。精彩留言会获得点赞!