基于自适应对手集成建模的网络安全对抗自学习仿真方法
本发明属于多智能体仿真,具体涉及一种基于自适应对手集成建模的网络安全对抗自学习仿真方法。
背景技术:
1、在网络对抗场景中,管理员(防御方智能体)可以观察到普通用户(中立智能体)以及恶意攻击者(攻击智能体)发送的信号,但不能确定所观测到智能体的类型;而恶意攻击者对于管理员的身份与意图是已知的,从而导致管理员与恶意攻击者在非确定信息下进行对抗博弈。在此类网络对抗环境下,恶意攻击者不能直接操控管理员观测,但可以使用对抗性策略在对抗环境中进行伪装及欺诈行为。网络管理员在做出是否屏蔽信号的决定之前,需要推断信号发送者的身份,这大大增加了网络管理员决策过程的复杂性。
2、对手建模是非确定性网络对抗行为智能决策的重要方法,对手建模方法通过观察对手的状态和动作,进而直接建模对手的策略或估计中间统计量(如自我方智能体对对手的策略的预期值),然而,对手建模对建模误差的高度敏感,可能导致在面对之前未见的对手时性能显著下降。为此传统的对手集成建模方法,需要维护一个足够多样化的对手策略集合,因此计算复杂性较高。
技术实现思路
1、(一)要解决的技术问题
2、本发明要解决的技术问题是:如何提供一种基于自适应对手集成建模的网络多智能体对抗自学习方法。
3、(二)技术方案
4、为解决上述技术问题,本发明提供一种基于自适应对手集成建模的网络安全对抗自学习仿真方法,所述方法包括如下步骤:
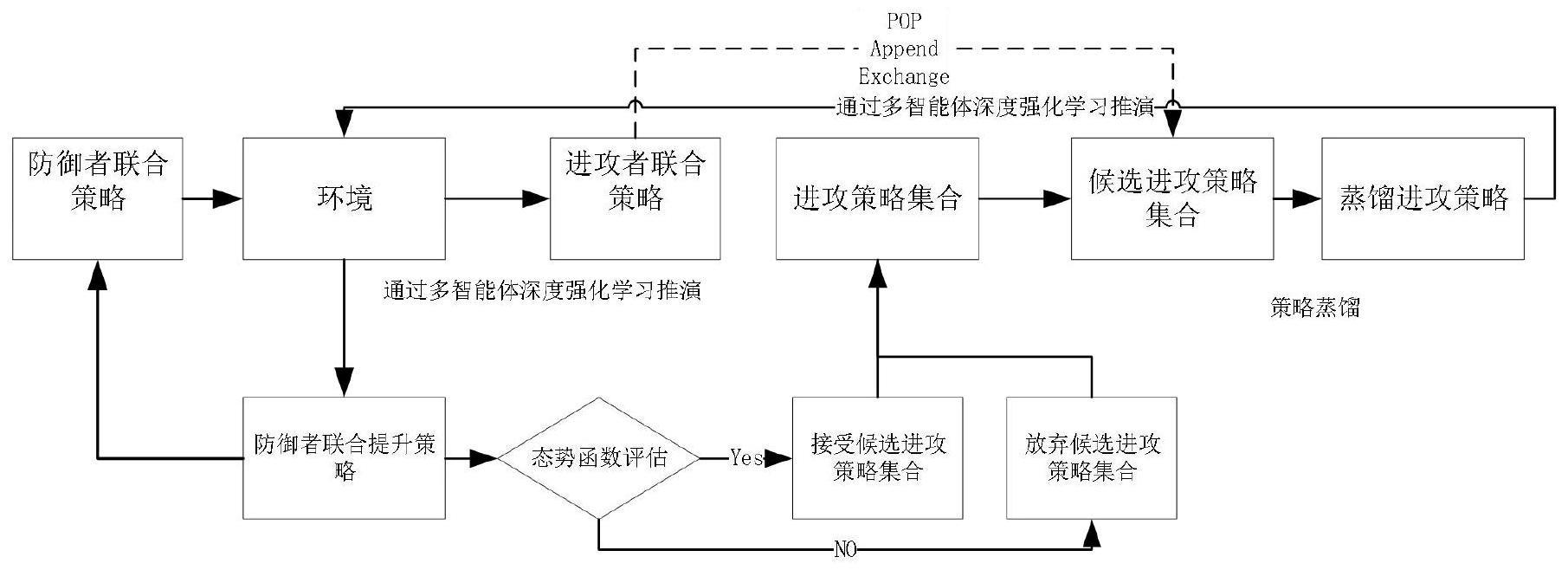
5、步骤1:搭建网络攻防仿真环境;使用微软开源人工智能攻防对抗模拟工具即cyberbattlesim工具搭建网络攻防仿真环境;
6、步骤2:确定团队奖励函数;
7、步骤3:训练攻击方联合策略;以给定防御方联合策略为对手环境,使用合作型多智能体强化学习构建攻击方候选联合策略;
8、步骤4:生成攻击方联合策略候选集合;
9、步骤5:蒸馏攻击方联合策略候选集合;
10、步骤6:自博弈提升防御方联合策略;
11、步骤7:自适应维护攻击方联合策略集合;利用哈密顿蒙特卡洛方法自适应接受或拒绝候攻击方联合策略候选集合;
12、步骤8:判断终止条件;如果满足终止条件迭代停止。
13、其中,所述步骤1中,搭建网络攻防仿真环境,具体包括:
14、步骤11:网络攻防仿真环境是由k个网络节点组成的固定网络拓扑网络,每个网络节点都可以挂载三种属性信息,包括不挂载信息、挂载有害信息、挂载无害信息;初始时,网络攻防仿真环境的所有网络节点都不挂载信息;
15、步骤12:攻防仿真开始首回合,扮演攻击者的n个攻击智能体在固定的攻击者出发节点出现;每回合开始时,n个攻击智能体根据自身策略在网络上沿着一条边移动或执行两种动作:{发布有害信息、发布正常信息};
16、步骤13:攻防开始首回合,扮演防御者的m个防御智能体在固定防御者出发节点出现,每回合时m个防御智能体根据自身策略在网络上沿着一条边移动或执行一种动作:{删除该节点上信息};
17、步骤14:攻防开始首回合,扮演中立者的h个中立智能体在网络节点上随机出现,每回合以给定概率p1在网络上沿着边自由移动或以概率1-p1执行一种动作:{发布正常信息};
18、步骤15:当防御智能体与攻击智能体位于同一网络节点时,防御智能体以概率p2自动捕获攻击智能体,被捕捉攻击智能体立即消失;
19、步骤16:每个智能体仅能观测到相邻网络节点的状态;当该网络节点发布有正常信息时,攻击智能体如发布有害消息则覆盖当前节点正常消息。
20、其中,所述步骤2中,确定团队奖励函数;具体包括:
21、步骤21:如果攻击智能体的总数量小于给定阈值n1,(其中,n1<n,则防御方胜利,防御方奖励r1=1,攻击方奖励r2=0;
22、步骤22:如果网络节点上有害信息总数大于给定阈值k1,k1<k,则攻击方胜利,防御方奖励r1=0,攻击方奖励r2=1。
23、其中,所述步骤3中,训练攻击方联合策略;以给定防御方联合策略为对手环境,使用合作型多智能体强化学习构建攻击方候选联合策略;具体包括:
24、步骤31:随机初始化1种防御方联合策略其中表示第j个防御智能体的个体策略;
25、步骤32:随时初始化s种攻击方联合策略集合其中表示第j种攻击方联合策略,且表示第j种攻击方联合策略中第i个攻击智能体的个体策略;
26、步骤33:将作为对手环境,利用pytorch软件包marl-code采用mappo,maddpg,matd3,qmix以及vdn方法中的其中之一学习攻击方候选联合策略
27、步骤34:对抗结束时记录对应奖励其中表示使用攻击方联合策略时防御方总奖励,表示对应攻击方总奖励;
28、步骤35:计算双方态势评估函数;以如下公式计算双方态势评估函数:
29、
30、其中,λ=0.2为给定超参数。
31、其中,所述步骤4中,生成攻击方候选联合策略集合;具体包括:
32、步骤41:针对步骤33中生成的攻击方候选联合策略,在攻击方联合策略集合上以相同概率随机执行如下三种操作之一:弹出(pop)、追加(append)以及交换(exchange),从而生成攻击方候选联合策略集合。
33、步骤42:如果选中弹出操作(pop),则从攻击方联合策略集合中随机删除第j条策略
34、步骤43:如果追加操作(append),则将攻击方候选联合策略加入攻击方联合策略集合
35、步骤44:如果选中交换操作(exchange),将攻击方候选联合策略与攻击方联合策略集合中随机选取的第j条策略互换;
36、步骤45:依据步骤42或步骤43或步骤44产生更新后的攻击方候选联合策略集合,如图2所示;
37、
38、其中,s'为攻击方候选联合策略集合中联合策略总数量。
39、其中,所述步骤5中,具体包括:
40、步骤51:对于第j个攻击智能体,其候选攻击策略集合为
41、通过极小化蒸馏损失:
42、其中,表示参数为θj的深度策略网络,训练策略网络参数θj;其中所述策略网络具体结构如表1,即参数为θj的神经网络,为:网络由2组卷积/池化层与两个全连接层构成,2组卷积层为:第一层16个卷积滤波器,第二层32个卷积滤波器;其中卷积层的卷积核大小固定为3×3,填充列数(padding)为1,步长为1;池化层固定为窗口2×2,步长为2的单元;信号通过卷积/池化层后通过两个全连接层调节输出维度。
43、表1.策略网络具体结构
44、
45、训练过程如下:各层都按概率20%使用了隐正则化处理方法如:随机失活(dropout算法);迭代100次,训练过程中一次取32批次样本训练,学习率取0.01;得到策略网络参数θj;
46、步骤52:获得n个智能体的蒸馏攻击方联合策略
47、
48、其中,所述步骤6具体包括:
49、通过以n个攻击智能体的蒸馏攻击方联合策略作为对手环境,利用利用pytorch软件包marl-code采用mappo,maddpg,matd3,qmix以及vdn方法其中之一学习提升防御方联合策略π'd,对抗结束时记录对应奖励{r'1,r'2},r'1表示使用蒸馏攻击方联合策略π'a时防御方总奖励,r'2表示对应攻击方总奖励。
50、其中,所述步骤7具体包括:
51、步骤71:计算双方态势评估函数
52、ρnew=-r'1+λr'2+s'
53、其中λ=0.2为给定超参数;
54、步骤72:以概率接受步骤45中攻击方候选联合策略更新,否则为此攻击策略集合不变,其中t=1/2代表控制温度参数。
55、其中,所述步骤8中,判断终止条件;如果满足终止条件迭代停止;否则转到步骤3重新开始计算。
56、其中,所述步骤8中,所述终止条件包括如下两个条件之一:
57、1)当最大迭代步数超过给定阈值itmax=100,迭代停止;
58、2)当提升防御者策略变化小于给定阈值ε=0.1时,即
59、
60、迭代停止。
61、(三)有益效果
62、与现有技术相比较,本发明提出了一种基于自适应对手集成建模的网络安全对抗自学习仿真方法;首先,针对防御方联合策略采用多智能体强化学习训练一个攻击方联合策略;其次根据攻击方联合策略采用哈密顿蒙特卡洛采样方法生成攻击方联合策略候选集合;然后对攻击方联合策略候选集合进行策略蒸馏获得一个“平均”的蒸馏攻击方联合策略;使用蒸馏攻击方联合策略与防御方联合策略自博弈提升防御方联合策略,并进行回报函数评估,决定是否接受候选策略集合。最终,本发明技术方案通过自适应生成多样的攻击策略集合、使得防御者通过自学习逐步提升自身策略,特别可以对于未见攻击策略提升应对的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!