一种基于混合权重和双通道图卷积的方面级情感分析方法
本发明涉及自然语言处理,具体涉及一种基于混合权重和双通道图卷积的方面级情感分析方法。
背景技术:
1、方面级情感分析alsa(aspect level sentiment analysis)是一种细粒度的情感分析任务,其目的是自动分类与文本的特定方面相关的情感。alsa的研究工作是基于机器学习方法开展的。wu等人提出一种基于概率图模型的情感分析方法,结合支持向量机进行分类,且在实验中具有良好的表现。但传统的基于机器学习的方法依赖于构建特征工程的质量,这使得alsa的发展受到了限制。而深度学习不受这些限制,并在各种情感分析任务中取得了巨大的成功。目前大多数方面级情感分类的研究主要通过神经网络来展开研究,并且都侧重于语法的改进或语义信息的获取。其中语法信息大多通过依存树获取句子的结构。依存树是指句子中词之间的语法关系,以三联体的形式出现,形成一个句子的树形结构。在此基础上hou xc等人通过多种解析,生成不同句法结构的依存树,并将其组合成一张有向图网络进行训练。wang k等人构建一种以方面词为根节点的依存树,并与关系图注意力网络结合实现了情感预测。苏锦钿等人基于句法依存树,定义了语法距离以及语法距离权重,最终取得了很好的分类效果。这些方法虽然通过改善句法结构或修剪句法依存树,但忽略了对情感极性知识的研究,从而导致方面级情感分类准确率较低的问题。
2、情感知识通常被用来增强情感分析任务中的情感特征表征。ma等人将情感相关概念的常识性知识纳入到长短时记忆网络中,用于面向方面的情感分类。bin liang等人引入senticnet词典来对句法依存树进行润色。现有研究未能有效地将情感知识中的情感极性标签和情感极性值纳入到情感分类模型中,缺乏对情感信息的深度挖掘。
3、为了提高分类性能,p.chen等人将给定方面的线性位置信息集成到方面级情感分类模型中。li等人在gcn的基础上加入掩码机制和句子线性位置编码并采用注意力机制来进行分类,相比之前的方法取得了更好的分类效果,但是缺乏对词性特征和物理距离特征的综合考虑,导致模型无法关注对方面词影响较大的上下文词。所以结合词性特征与物理距离特征也是一个值得考虑的研究方向。此外,付朝燕等人将词性和语法关系融入到每个词的向量表示中来丰富词的向量表示,但是缺少对词的位置特征的考虑。因此,在词的向量表示中融入位置特征可以更有利于语义的学习。
4、上述方法均已在实践中得到了良好的验证,但都是从某一角度对情感分类进行研究,仍缺少一种综合考虑词性、语法关系、位置、物理距离、语法距离和情感极性知识等有助于准确识别方面词情感重要特征的方法,对情感极性知识的挖掘也不够充分,并且缺少对词性和物理距离混合权重的考虑。最终本发明提出了一种基于混合权重和双通道图卷积的方面级情感分析方法。
技术实现思路
1、本发明提供了一种基于混合权重和双通道图卷积的方面级情感分析方法,以解决现有技术中在语义特征、句法依存关系特征和外部情感极性知识特征提取不充分而造成方面级情感分析不准确的问题。
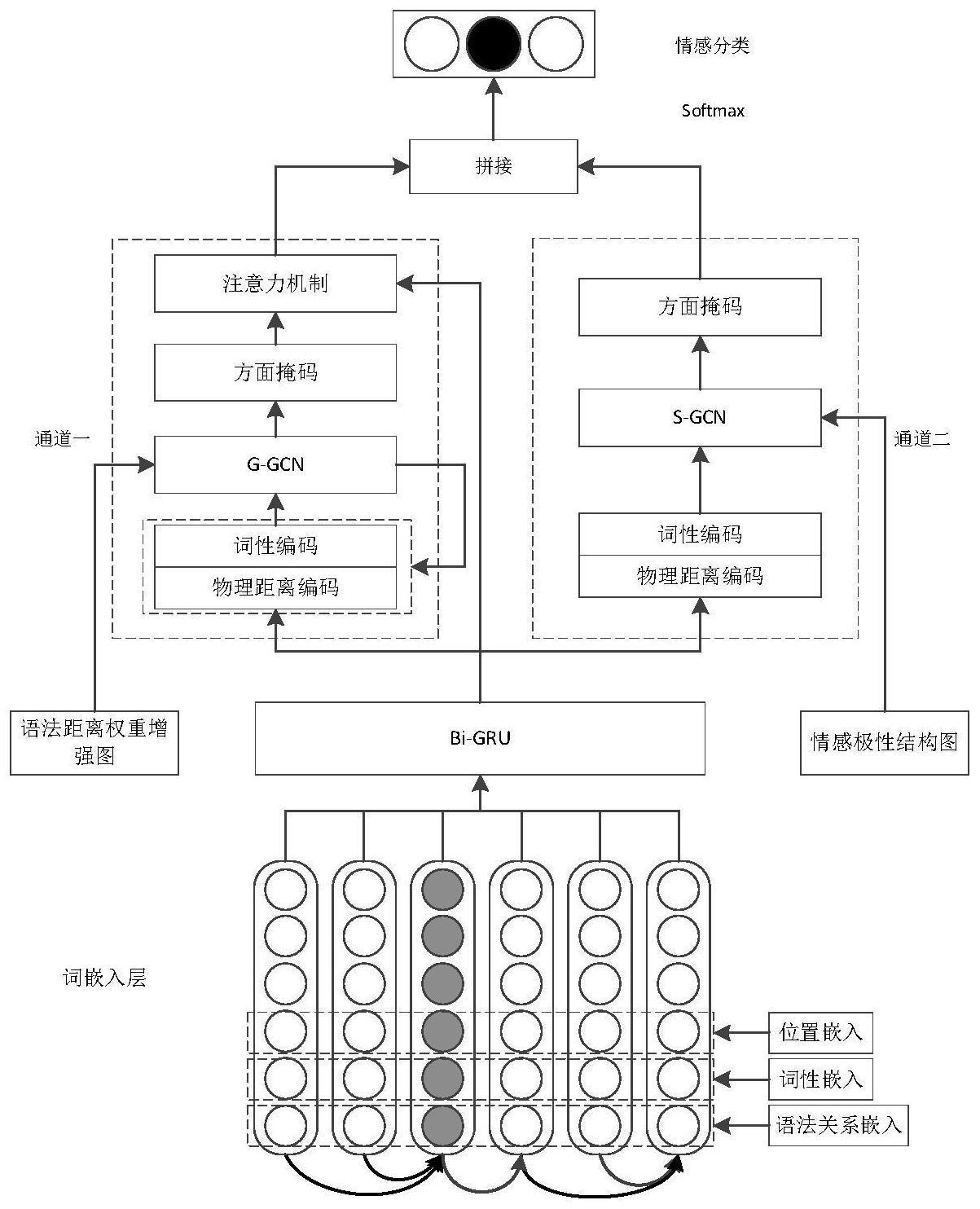
2、本发明提供了一种基于混合权重和双通道图卷积的方面级情感分析方法,包括如下步骤:
3、步骤1:将句子中的每个词生成向量表示;
4、步骤2:将句子中的每个单词的词性、语法关系和位置融入到每个词的向量表示中;
5、步骤3:基于步骤2获取的每个词的向量表示,利用bi-gru模型获取每个词的上下文信息,其中上下文信息包括:方面词的上下文信息;
6、步骤4:获取句子中每个方面词的上下文词相对方面词的词性-距离混合权重;
7、步骤5:构建双通道图卷积网络,双通道图卷积网络分别对句子的语法距离权重增强图和情感极性结构图进行卷积操作,得到基于语法距离的图卷积网络输出特征向量以及基于情感极性的图卷积网络输出特征向量;
8、其中,语法距离权重增强图是在句法依存树的基础上加入语法距离;
9、情感极性结构图是在句法依存树的基础上加入情感极性标签和情感极性值;
10、步骤6:将步骤5中获得的两个特征向量分别进行方面掩码,得到仅包含方面词隐藏特征的特征向量;
11、步骤7:将步骤6中得到的仅包含方面词隐藏特征的基于语法距离的图卷积网络输出特征向量和步骤3中方面词的上下文信息通过注意力机制进行注意力权重分配,得到经过注意力机制处理的特征向量;其中,步骤3中方面词的上下文信息作为注意力机制的键矩阵和值矩阵,步骤6中得到的仅包含方面词隐藏特征的基于语法距离的图卷积网络输出特征向量作为注意力机制的查询矩阵;
12、步骤8:对步骤7中得到的经过注意力机制处理的特征向量与步骤6得到的仅包含方面词隐藏特征的基于情感极性的图卷积网络输出特征向量进行拼接融合,然后输入到分类函数,将分类函数输出结果作为目标词的情感极性预测结果。
13、进一步地,所述步骤2的具体过程为:
14、先将句子的每个单词的词性、语法关系和位置映射到低维、连续、稠密空间后得到词性嵌入、语法关系嵌入和位置嵌入,然后将词性嵌入、语法关系嵌入和位置嵌入融入到每个词的向量表示中完成融入过程。
15、进一步地,所述步骤4的具体过程为:
16、获取当前的方面词与当前的方面词对应的每个上下文词的物理距离,根据物理距离从近至远对每个上下文词赋予从高至低的物理距离权重;
17、获取当前的方面词与当前的方面词对应的每个上下文词中的形容词,对形容词赋予高权重的词性权重,对其他词的词性权重赋予零;
18、将当前的方面词对应的每个上下文词的物理距离权重与词性权重相加得到当前的方面词对应的每个上下文词的词性-距离混合权重;
19、进一步地,所述步骤4中还包括获取当前的方面词与当前的方面词对应的每个上下文词中冠词,对形容词赋予高权重的词性权重,对冠词赋予低权重的词性权重,对其他词的词性权重赋予零。
20、进一步地,所述步骤5中对双通道图卷积网络对句子的语法距离权重增强图进行卷积操作时,包括:
21、对双通道图卷积网络中基于语法距离的图卷积网络当前卷积的输出,与向量表示的词性-距离混合权重进行加权作为下次卷积的输入。
22、本发明的有益效果:
23、本发明因为在每个词的向量表示中融入了词性、语法关系和位置来丰富每个词的向量表示,以及使用词性权重和物理距离权重构建混合权重来排除对方面词不重要的上下文词的干扰,最后融合了语法距离特征和情感极性知识特征使方法从多角度捕获方面词的信息,因此本发明的方面级情感分类性能优于其他方法;
24、本发明因为在每个词的向量表示中融入了词性嵌入、语法关系嵌入和位置嵌入,可以丰富词的向量表示,因此本发明使模型学习到更多的信息,有助于提高分类效果;
25、本发明因为基于词性特征和物理距离特征的混合权重可以在句子线性结构中给予关键信息更大的权重,因此本发明可以排除不重要的上下文词带来的噪音和偏差;
26、本发明因为在句子树形结构上融合了语法距离特征和情感极性知识(情感极性标签、情感极性值),因此本发明可以从不同角度来捕获方面词的信息,有助于提高情感分类的准确性。
- 还没有人留言评论。精彩留言会获得点赞!