一种适应多对手的无人机强化学习训练方法
本发明涉及人工智能和无人机领域,具体涉及一种适应多对手的无人机强化学习训练方法。
背景技术:
1、无人机具有成本低、灵活性高、隐蔽性强等优点,在勘探、救援、战争等领域起到越来越重要的作用。在实际使用中,由于环境、成本等因素的制约,无人机通常无法与对手进行大量交互以得到训练数据,因此通常会在仿真环境中对无人机进行训练以得到策略,然后在实际任务中进行部署。这种训练方法对仿真环境的精度有着很高的要求,需要对对手信息有足够的了解;并且在使用中也限定实际对手类型与仿真环境具有较高的相似度。
2、现有的无人机训练算法过于依赖精确的仿真环境,导致训练得到的策略泛化性较弱;同时在面对仿真环境外的实际对手时,需要重新建模导致消耗资源过多,不利于策略的大规模部署。因此,减少无人机策略对仿真环境精度的依赖,并提高其面对实际对手时的快速适应能力,是保证无人机策略大规模部署的一个关键点。
技术实现思路
1、本发明技术解决问题:克服现有技术的不足,提供一种适应多对手的无人机强化学习训练方法,降低仿真时对仿真环境精度的依赖,并提高面对实际对手时的快速适应能力;通过该方法训练得到的无人机策略具强泛化性和自适应性,在实际使用时能够快速适应不同的对手策略。
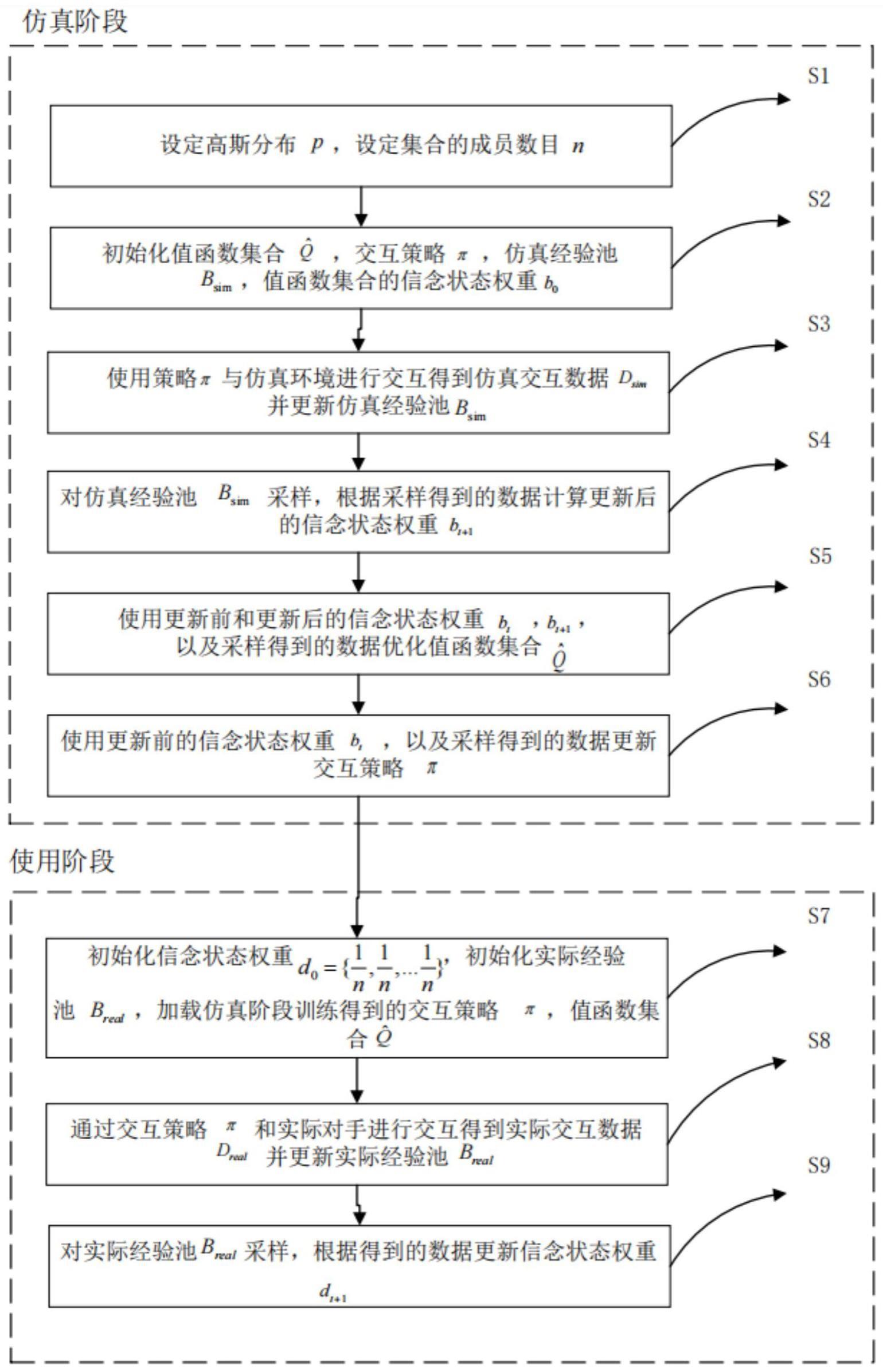
2、本发明的技术方案为:一种适应多对手的无人机强化学习训练方法,包括仿真和使用两个阶段,仿真阶段包括步骤s1-步骤s6:
3、步骤s1:设定高斯分布p~n[0,1],设定集合的成员数目n,其中n为正整数且n≤15;
4、步骤s2:初始化值函数集合其中表示一个值函数,交互策略π,仿真经验池bsim,从高斯分布p中随机初始化值函数集合的信念状态权重b0,其中表示值函数对应的权重;
5、步骤s3:使用交互策略π与仿真环境进行交互得到仿真交互数据dsim,并更新仿真经验池bsim;
6、步骤s4:对仿真经验池bsim采样,根据采样得到的数据和信念状态权重bt计算得到更新后的信念状态权重bt+1;
7、步骤s5:使用更新前的信念状态权重bt和更新后的信念状态权重bt+1,以及采样得到的数据通过最小化平方误差的方式优化值函数集合
8、步骤s6:根据更新前的信念状态权重bt以及采样得到的数据更新交互策略π;
9、当训练结束时,仿真阶段结束;
10、使用阶段包括步骤s7-步骤s9:
11、步骤s7:初始化信念状态权重d0为均匀分布,其中n为仿真阶段设定的集合的成员数目,初始化实际经验池breal,加载仿真阶段训练得到的交互策略π、值函数集合
12、步骤s8:使用交互策略π与实际对手进行交互得到实际交互数据dreal,并更新实际经验池breal;
13、步骤s9:对实际经验池breal采样,根据采样得到的数据更新信念状态权重dt+1;
14、当停止与实际对手交互时,使用阶段结束。
15、进一步,所述步骤s 2具体包括:
16、s21:根据设定的集合的成员数目n,初始化包括n个值函数的值函数集合其中表示一个值函数,初始化交互策略π,其中π(·|s,b):s×△n→△(a);初始化仿真经验池
17、s22:从设定的高斯分布p中随机采样n个值{a1,a2,...an},初始化值函数集合的信念状态权重其中表示值函数对应的权重,
18、进一步,所述步骤s3中,使用交互策略π与仿真环境进行交互得到仿真交互数据dsim并更新仿真经验池bsim,具体包括:
19、s31:交互策略π根据当前状态st和信念状态权重bt选择动作:at:at~π(·|st,bt);
20、s32:执行动作at,仿真环境返回奖励rt和下一时刻状态st+1:rt,st+1←env.step(at),得到仿真交互数据dsim;
21、s33:将dsim以经验样本{(st,at,rt,st+1)}的形式存入到仿真经验池bsim。
22、进一步,所述步骤s4中,对仿真经验池bsim采样,根据采样得到的数据和信念状态权重bt计算得到更新后的信念状态权重bt+1,表示为式(1),其中beliefupdate表示信念状态权重的更新表达式,st表示当前状态,at表示当前动作,rt表示仿真环境返回奖励,st+1表示下一时刻状态:
23、bt+1=beliefupdate(bt,(st,at,rt,st+1)) (1)
24、s41:从仿真经验池bsim中采样一批数据;
25、s42:根据采样的数据计算值函数集合中每个值函数对应的更新后的权重如式(2)所示,其中表示值函数对应的更新后的权重,γ表示衰减因子,γ∈(0,1),at+1表示下一时刻动作;
26、
27、s43:将得到的更新后的权重集合,得到更新后的信念状态权重其中i∈{1,2,...n}。
28、进一步,所述步骤s5中,使用更新前的信念状态权重bt和更新后的信念状态权重bt+1,以及采样得到的数据通过最小化平方误差的方式优化值函数集合具体实现为:
29、s51:根据更新前的信念状态权重bt和更新后的信念状态权重bt+1,通过最小化平方误差的方式优化值函数集合中的值函数其中i∈{1,2,...n},如式(3)所示,其中st表示当前状态,at表示当前动作,rt表示仿真环境返回奖励,st+1表示下一时刻状态,at+1表示下一时刻动作,γ表示衰减因子,γ∈(0,1);
30、
31、s52:将优化后的值函数进行集合,得到优化后的值函数集合
32、进一步,所述步骤s6中,根据更新前的信念状态权重bt和以及采样得到的数据更新交互策略π,更新公式,如式(4)所示,其中st表示当前状态,at表示当前动作,表示值函数对应的更新前的权重:
33、
34、进一步,所述步骤s7中,初始化信念状态权重d0为均匀分布,其中n为仿真阶段设定的集合的成员数目,初始化实际经验池breal,加载仿真阶段训练得到的交互策略π、值函数集合具体包括:
35、s71:初始化信念状态权重d0为均匀分布,其中n为仿真阶段设定的集合的成员数目,初始化实际经验池breal;
36、s72:加载仿真阶段训练得到的交互策略π和值函数集合使用交互策略π采样初始状态。
37、进一步,所述步骤s8中,使用交互策略π与实际对手进行交互得到实际交互数据dreal并更新实际经验池breal,具体包括:
38、s81:交互策略π根据当前状态st和信念状态权重bt选择动作at:at~π(·|st,dt);
39、s82:执行动作at,仿真环境返回奖励rt和下一时刻状态st+1,得到实际交互数据dreal;
40、s83:将dreal以经验样本{(st,at,rt,st+1)}的形式存入到实际经验池breal。
41、进一步,所述步骤s9中,对实际经验池breal采样,根据采样得到的数据更新信念状态权重dt+1,具体包括:
42、s91:从实际经验池breal中采样一批数据;
43、s92:根据使用采样的数据计算值函数集合中每个值函数对应的更新后的权重其中st表示当前状态,at表示当前动作,rt表示仿真环境返回奖励,st+1表示下一时刻状态,at+1表示下一时刻动作,dt表示更新前的信念状态权重,γ表示衰减因子,γ∈(0,1),表示值函数对应的更新后的权重。
44、本发明与现有技术相比,具有以下优点∶
45、(1)本发明提高了面对实际对手时的快速适应能力;通过该方法训练得到的无人机策略具强泛化性和自适应性,在实际使用时能够快速适应不同的对手策略。
46、(2)本发明的一种适应多对手的无人机强化学习训练方法。通过该方法在仿真阶段训练得到的无人机交互策略,能够最大化信念状态权重加权的值函数集合的平均值。在使用阶段根据实际交互数据更新信念状态权重,降低那些预测值与实际交互数据不一致的值函数集合中成员的权重。这保证了通过仿真阶段得到的无人机策略能够自适应不同的对手,并减少无人机交互策略对仿真环境精度的依赖,快速适应对手策略。
47、(3)本发明公开的一种适应多对手的无人机强化学习训练方法,能够和任意的无人机强化学习算法相结合,具有很强的普适性,有利于实际中无人机策略的大规模部署。
- 还没有人留言评论。精彩留言会获得点赞!