基于布降过滤器实现双核心文件比对的方法与流程
本发明涉及计算机,具体为基于布降过滤器实现双核心文件比对的方法。
背景技术:
1、在实现双核心文件重复比对时发现,文件中核心客户的数量高达数百万级时,常用的比对多文件重复数据的方法将出现性能瓶颈,如将a核心文件落库落表a。读取b核心文件时,查询b核心文件该数据是否存在于a表中,若是则表示该数据重复,需要从b文件中剔除。但是这种常用方式会导致数据比对缓慢且步骤复杂,耗时较长效率较低。
2、而布隆过滤器则是一种空间效率很高的随机数据结构,它利用位数组很简洁的表示一个集合,并且可以判断一个元素是否属于这个集合。相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数o(k),另外,散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。且布隆过滤器可以表示全集,其它任何数据结构都不能。布隆过滤器也存在着一些缺点,随着数据量的增加,会出现一定的误算率,可以通过改变位数组的大小调解误算率。
3、基于此,本领域技术人员提供了基于布降过滤器实现双核心文件比对的方法,以解决上述背景技术中提出的问题。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了基于布降过滤器实现双核心文件比对的方法,能够高效的进行双核心文件的比对,解决了文件比对重复数据时效率低下的问题。
3、(二)技术方案
4、为实现以上目的,本发明通过以下技术方案予以实现:
5、基于布降过滤器实现双核心文件比对的方法,包括以下步骤:
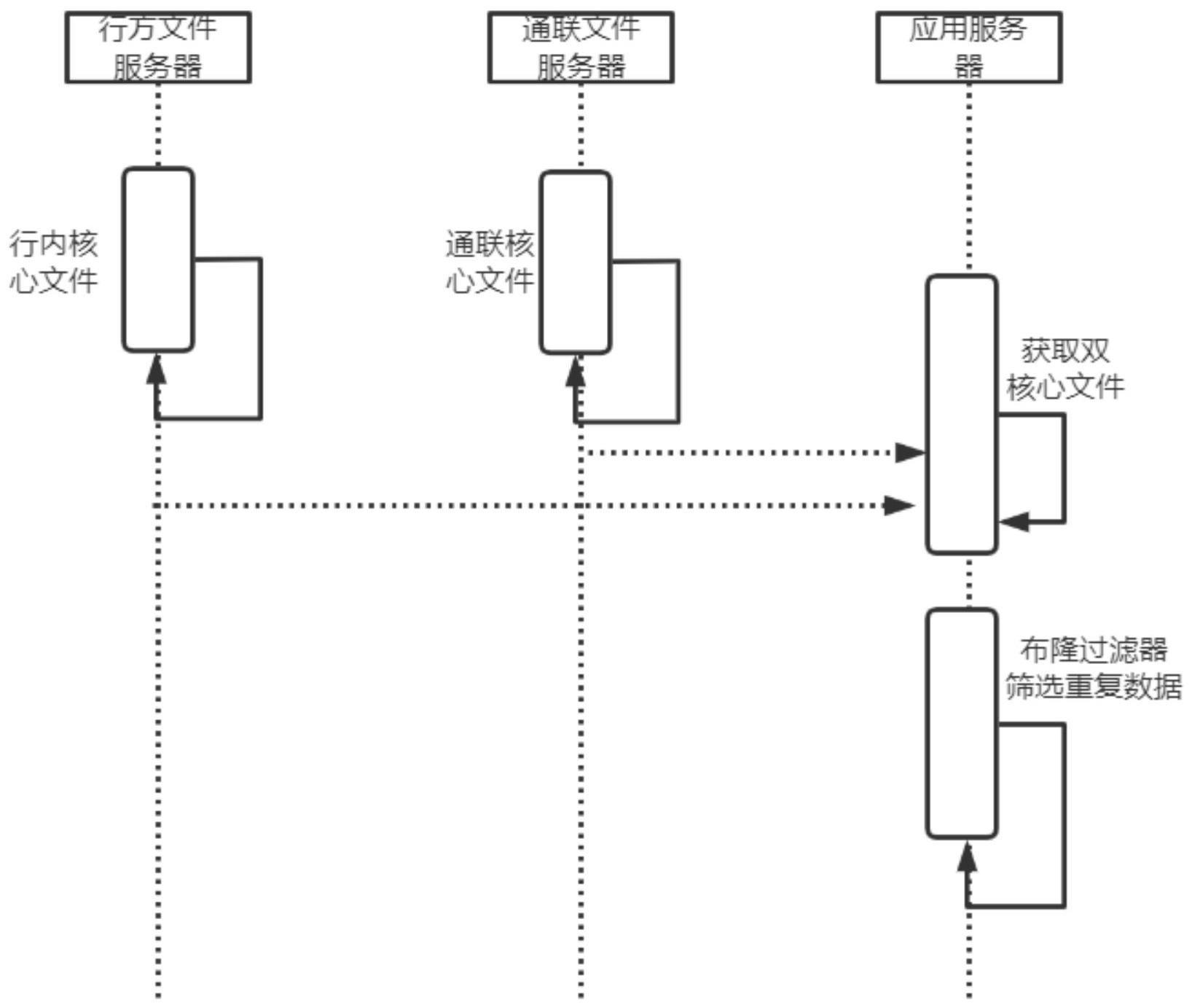
6、s1.登录行方文件服务器,获取行内和通联的核心客户号文件;
7、s2.将文件以字节流的方式读取到内存里;
8、s3.定义并实现布隆过滤器,将两个核心文件中的客户号数据进行比对,判断一个客户号是否存在于另一个文件里,若存在则将该客户号删除。
9、优选的,获取行内和通联的核心客户号文件,将两个文件放置在待程序处理的目录下。
10、优选的,建设服务限流功能,将双核心的文件以字节流的方式读取到内存中。
11、优选的,定义并实现布隆过滤器,判断客户号是否存在另一个核心文件中,若是则将该客户号从当前文件中剔除。
12、优选的,该方法包括一个二进制向量和一系列随机映射的函数。
13、优选的,该方法还包括时间复杂度低,增加和查询元素的时间复杂为o(n)。
14、优选的,该方法还包括存储空间小,如果允许存在一定的误判,布隆过滤器非常节省空间。
15、优选的,所述至少一个组件包含上述特性及功能,使得所述至少一个方法如权利要求1-4任一项所述的基于布隆过滤器实现双核心文件比对的方法。
16、(三)有益效果
17、本发明提供了基于布降过滤器实现双核心文件比对的方法。具备以下有益效果:
18、1、本发明提供了基于布降过滤器实现双核心文件比对的方法,能够获取行内核心客户号文件,将该文件放置在待处理目录下,定义并实现布隆过滤器,判断客户号是否存在另一个核心文件中,若是则将该客户号从当前文件中剔除,进而能够高效的进行双核心文件的比对。
技术特征:
1.基于布降过滤器实现双核心文件比对的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,获取行内和通联的核心客户号文件,将两个文件放置在待程序处理的目录下。
3.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,建设服务限流功能,将双核心的文件以字节流的方式读取到内存中。
4.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,定义并实现布隆过滤器,判断客户号是否存在另一个核心文件中,若是则将该客户号从当前文件中剔除。
5.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,该方法包括一个二进制向量和一系列随机映射的函数。
6.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,该方法还包括时间复杂度低,增加和查询元素的时间复杂为o(n)。
7.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,该方法还包括存储空间小,如果允许存在一定的误判,布隆过滤器非常节省空间。
8.根据权利要求1所述的基于布降过滤器实现双核心文件比对的方法,其特征在于,所述至少一个组件包含上述特性及功能,使得所述至少一个方法如权利要求1-4任一项所述的基于布隆过滤器实现双核心文件比对的方法。
技术总结
本发明提供基于布降过滤器实现双核心文件比对的方法,涉及计算机技术领域。该基于布降过滤器实现双核心文件比对的方法,包括以下步骤:S1.登录行方文件服务器,获取行内和通联的核心客户号文件;S2.将文件以字节流的方式读取到内存里;S3.定义并实现布隆过滤器,将两个核心文件中的客户号数据进行比对,判断一个客户号是否存在于另一个文件里,若存在则将该客户号删除。本发明中,能够获取行内核心客户号文件,将该文件放置在待处理目录下,定义并实现布隆过滤器,判断客户号是否存在另一个核心文件中,若是则将该客户号从当前文件中剔除,进而能够高效的进行双核心文件的比对。
技术研发人员:程赫
受保护的技术使用者:上海通联金融服务有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!