文本匹配方法、装置、存储介质以及电子设备与流程
本技术涉及人工智能领域,具体而言,涉及一种文本匹配方法、装置、存储介质以及电子设备。
背景技术:
1、文本匹配是自然语言处理中的一项基本任务,被广泛应用于智能问答系统和信息检索领域。给定两句文本,匹配模型或系统需要判断两句话的语义是否相同,是一个典型的二分类判别任务。早期的文本匹配多是基于统计学习方法实现的,如bm25等,但是由于缺乏对文本语义层次的特征建模,在实际应用过程中效果往往不佳。近年来随着深度学习的快速发展,出现并使用一系列基于静态词向量的文本匹配方法确定文本是否匹配。
2、在深度学习时代,当前主流的文本匹配方法主要分为两大类:基于表示的方法和基于交互的方法。大多数基于表示的方法采用孪生网络架构,如siamese-lstm,利用度量学习等方式分别提取两句文本的高层次特征,之后通过距离计算判定文本相似度。此类匹配方法由于缺少对两句文本语义相关性的考虑,效果一般较差。基于交互式的方法,在模型结构中通常使用注意力机制进行两句话之间的特征交互,从而取得更好的匹配效果。大多数流行的预训练模型,在应用于文本匹配任务时都属于第二类,并且往往具备远超非预训练方法的能力。
3、以上提到的多种文本匹配方法包括传统方法在内,都有一个共同点,也即,直接将需要进行对比的两个文本输入单一的文本匹配模型中,通过文本匹配模型直接确定两个文本是否相同,并未对文本进行预处理,进而导致在输入模型后降低了模型的识别判断准确性。
4、针对相关技术中通过将文本输入单一模型进行相似度判断的准确性低的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术提供一种文本匹配方法、装置、存储介质以及电子设备,以解决相关技术中通过将文本输入单一模型进行相似度判断的准确性低的问题。
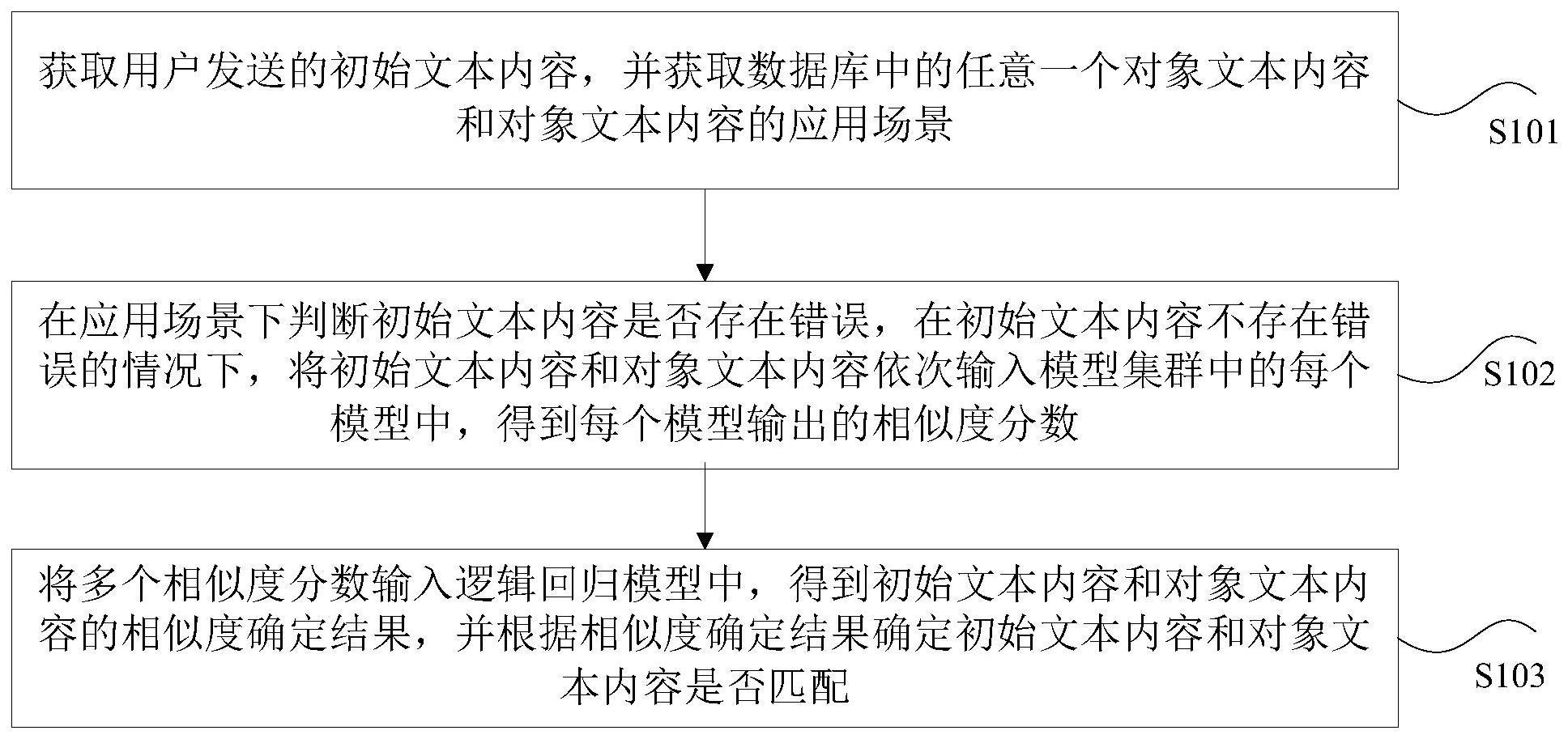
2、根据本技术的一个方面,提供了一种文本匹配方法。该方法包括:获取用户发送的初始文本内容,并获取数据库中的任意一个对象文本内容和对象文本内容的应用场景;在应用场景下判断初始文本内容是否存在错误,在初始文本内容不存在错误的情况下,将初始文本内容和对象文本内容依次输入模型集群中的每个模型中,得到每个模型输出的相似度分数,其中,模型集群中存在多个机器学习模型,每个机器学习模型用于确定初始文本内容和对象文本内容的相似度分数;将多个相似度分数输入逻辑回归模型中,得到初始文本内容和对象文本内容的相似度确定结果,并根据相似度确定结果确定初始文本内容和对象文本内容是否匹配。
3、可选地,在应用场景下判断初始文本内容是否存在错误包括:将初始文本内容进行分词,得到分词结果,其中,分词结果中包括多个词语;从词典库中获取应用场景下的历史词语修正记录,并判断多个词语中是否存在于历史词语修正记录中,得到判断结果;在判断结果表征多个词语中的至少一个词语存在于历史词语修正记录的情况下,确定初始文本内容存在错误;在判断结果表征多个词语均未存在于历史词语修正记录的情况下,确定初始文本内容不存在错误。
4、可选地,模型集群中包括词语匹配模型,将初始文本内容和对象文本内容输入词语匹配模型中,得到词语匹配模型输出的相似度分数包括:将初始文本内容按照第一粒度和第二粒度进行分词,得到第一分词结果和第二分词结果,其中,第一粒度小于第二粒度;将对象文本内容按照第一粒度和第二粒度进行分词,得到第三分词结果和第四分词结果;将粒度相同的第一分词结果和第三分词结果输入词语匹配模型中,得到第一相似度值;将粒度相同的第二分词结果和第四分词结果输入词语匹配模型中,得到第二相似度值;通过第一相似度值和第二相似度值确定词语匹配模型输出的相似度分数。
5、可选地,模型集群中包括关系判定模型,将初始文本内容和对象文本内容输入关系判定模型中,得到关系判定模型输出的相似度分数包括:将初始文本内容和对象文本内容输入关系判定模型中,得到判定结果,其中,判定结果用于确定初始文本内容和对象文本内容之间是否存在包含关系;在判定结果表征初始文本内容和对象文本内容之间存在包含关系的情况下,将关系判定模型输出的相似度分数确定为第一分数;在判定结果表征初始文本内容和对象文本内容之间不存在包含关系的情况下,将关系判定模型输出的相似度分数确定为第二分数,其中,第二分数小于第一分数。
6、可选地,模型集群中包括第一对比模型,将初始文本内容和对象文本内容输入第一对比模型中,得到第一对比模型输出的相似度分数包括:将初始文本内容和对象文本内容按照句子成分进行分词,得到两组第五分词结果;将两组第五分词结果输入第一对比模型中,得到第一对比结果,其中,第一对比模型用于确定初始文本内容和对象文本内容中句子成分相同的词语中是否存在反义词,第一对比结果中包括反义词的对数;从第一对比结果中获取反义词的对数,并根据对数确定第一对比模型输出的相似度分数。
7、可选地,模型集群中包括第二对比模型,将初始文本内容和对象文本内容输入第二对比模型中,得到第二对比模型输出的相似度分数包括:通过词典库确定初始文本内容中的关键词,得到第一关键词;通过词典库确定对象文本内容中的关键词,得到第二关键词;将第一关键词与第二关键词输入第二对比模型,得到第二对比结果,其中,第二对比模型用于确定文本内容中的关键词的相似度;将第二对比结果确定为第二对比模型输出的相似度分数。
8、可选地,在通过词典库确定初始文本内容中的关键词,得到第一关键词之前,该方法还包括:通过词典库确定初始文本内容和对象文本内容中是否均存在关键词;在初始文本内容或对象文本内容中不存在关键词的情况下,将第二对比模型输出的相似度分数确定为第二分数;在初始文本内容和对象文本内容中均不存在关键词的情况下,将第二对比模型输出的相似度分数确定为第一分数。
9、根据本技术的另一方面,提供了一种文本匹配装置。该装置包括:获取单元,用于获取用户发送的初始文本内容,并获取数据库中的任意一个对象文本内容和对象文本内容的应用场景;输入单元,用于在应用场景下判断初始文本内容是否存在错误,在初始文本内容不存在错误的情况下,将初始文本内容和对象文本内容依次输入模型集群中的每个模型中,得到每个模型输出的相似度分数,其中,模型集群中存在多个机器学习模型,每个机器学习模型用于确定初始文本内容和对象文本内容的相似度分数;第一确定单元,用于将多个相似度分数输入逻辑回归模型中,得到初始文本内容和对象文本内容的相似度确定结果,并根据相似度确定结果确定初始文本内容和对象文本内容是否匹配。
10、根据本发明实施例的另一方面,还提供了一种计算机存储介质,计算机存储介质用于存储程序,其中,程序运行时控制计算机存储介质所在的设备执行一种文本匹配方法。
11、根据本发明实施例的另一方面,还提供了一种电子设备,包含一个或多个处理器和存储器;存储器中存储有计算机可读指令,处理器用于运行计算机可读指令,其中,计算机可读指令运行时执行一种文本匹配方法。
12、通过本技术,采用以下步骤:获取用户发送的初始文本内容,并获取数据库中的任意一个对象文本内容和对象文本内容的应用场景;在应用场景下判断初始文本内容是否存在错误,在初始文本内容不存在错误的情况下,将初始文本内容和对象文本内容依次输入模型集群中的每个模型中,得到每个模型输出的相似度分数,其中,模型集群中存在多个机器学习模型,每个机器学习模型用于确定初始文本内容和对象文本内容的相似度分数;将多个相似度分数输入逻辑回归模型中,得到初始文本内容和对象文本内容的相似度确定结果,并根据相似度确定结果确定初始文本内容和对象文本内容是否匹配。解决了相关技术中通过将文本输入单一模型进行相似度判断的准确性低的问题。通过先对需要进行对比的文本内容进行内容正确与否的确定,在文本内容无误的情况下,通过多个模型依次对初始文本内容与对象文本内容进行判断,得到多个相似度结果,并通过多个相似度结果综合进行判断,进而达到了准确的判断两个文本内容是否匹配的效果。
- 还没有人留言评论。精彩留言会获得点赞!