基于簇置信度的深度聚类集成方法、装置、设备和介质
本发明涉及数据挖掘和人工智能,特别是一种基于簇置信度的深度聚类集成方法、装置、设备和介质。
背景技术:
1、随着5g时代的到来,大数据应用得到了快速发展,这些应用所产生的数据往往具有大规模、非结构化和高维度的特点,从这些复杂的数据中挖掘简单而有效的信息是一项非常具有挑战性的任务。数据聚类分析是一种经典的无监督机器学习方法,可以有效地揭示和挖掘数据的潜在知识模式,其目的是根据数据空间中的相似性、密度、区间或特定的统计分布度量对数据进行分组。传统的聚类方法,如k-means和高斯混合聚类,在很多领域都取得了良好的聚类性能。然而,面对大规模、高维的非结构化数据,传统的聚类方法效果并不理想,甚至失败,这是因为一方面,这些数据往往表现出比较稀疏的分布,使得它们很难被分割;另一方面,大多数传统聚类方法只能利用数据的浅层特征,无法挖掘潜在空间中复杂数据特征的相互依赖关系。
2、近年来,深度聚类方法的出现和发展,为解决这一难题提供了思路。深度聚类结合了深度表示学习和聚类方法的无监督共性,利用深度表示网络将原始数据映射到一个低维的嵌入表征空间,然后与聚类算法联合调整网络参数实现聚类。然而,现有的深度聚类方法几乎都存在以下局限性,即聚类结果高度依赖预训练阶段的低维嵌入。而预训练阶段深度表示网络生成的低维嵌入并不一定都适合聚类任务,此外,深度表示网络会因为不同的网络参数初始化而呈现不同的映射,因而深度聚类方法的聚类结果不稳定,鲁棒性较差。
技术实现思路
1、针对上述传统方法中存在的问题,本发明提出了一种基于簇置信度的深度聚类集成方法,一种基于簇置信度的深度聚类集成装置,一种计算机设备和一种计算机可读存储介质,能够获得鲁棒性和聚类表现更好的聚类结果。
2、为了实现上述目的,本发明实施例采用以下技术方案:
3、一方面,提供一种基于簇置信度的深度聚类集成方法,包括步骤:
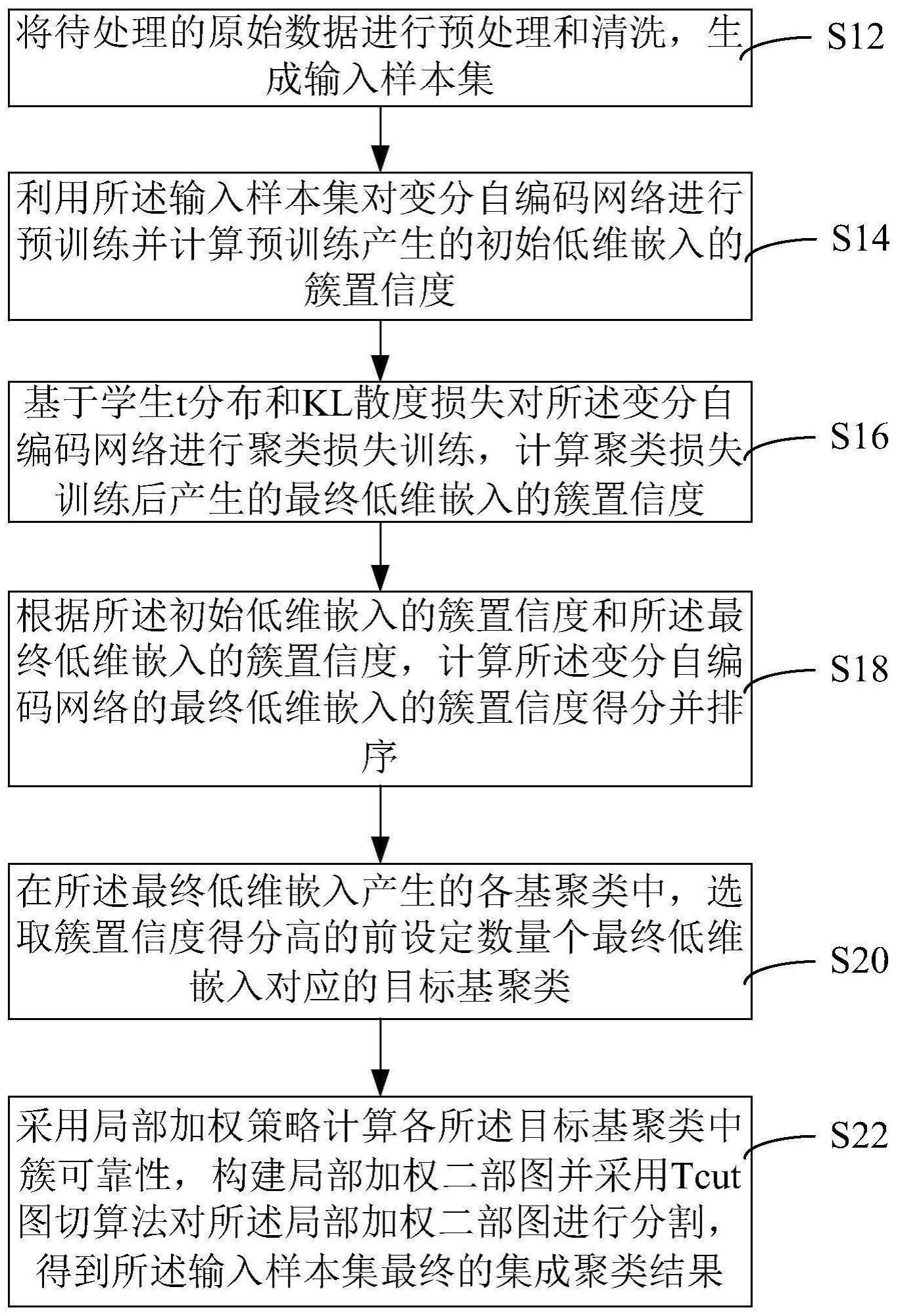
4、将待处理的原始数据进行预处理和清洗,生成输入样本集;
5、利用输入样本集对变分自编码网络进行预训练并计算预训练产生的初始低维嵌入的簇置信度;
6、基于学生t分布和kl散度损失对变分自编码网络进行聚类损失训练,计算聚类损失训练后产生的最终低维嵌入的簇置信度;
7、根据初始低维嵌入的簇置信度和最终低维嵌入的簇置信度,计算变分自编码网络的最终低维嵌入的簇置信度得分并排序;
8、在最终低维嵌入产生的各基聚类中,选取簇置信度得分高的前设定数量个最终低维嵌入对应的目标基聚类;
9、采用局部加权策略计算各目标基聚类中簇可靠性,构建局部加权二部图并采用tcut图切算法对局部加权二部图进行分割,得到输入样本集最终的集成聚类结果。
10、在其中一个实施例中,利用输入样本集对变分自编码网络进行预训练的过程,包括:
11、设定每个输入样本的后验概率的隐藏层变量分布遵循正态分布;
12、在预训练中采用kl散度对后验概率的隐藏层变量分布和标准正态分布进行度量,确定非聚类损失;
13、根据非聚类损失利用输入样本集进行变分自编码网络的预训练。
14、在其中一个实施例中,计算预训练产生的初始低维嵌入的簇置信度的过程,包括:
15、分别计算变分自编码网络中各变分自编码器的各个簇的置信度;
16、分别根据各变分自编码器的各个簇的置信度,计算各变分自编码器的初始低维嵌入的簇置信度。
17、在其中一个实施例中,基于学生t分布和kl散度损失对变分自编码网络进行聚类损失训练的过程,包括:
18、采用学生t分布度量变分自编码网络的隐藏层变量与聚类中心的相似度;
19、利用kl散度损失作为构建的辅助分布和待迭代优化的软簇分配之间的聚类损失,进行聚类损失训练。
20、在其中一个实施例中,各目标基聚类中簇可靠性通过如下公式进行计算度量:
21、
22、其中,ece(ci)表示簇ci的集成簇可靠性度量,hπ(ci)表示集成π中簇ci的不确定性,m表示基聚类的个数。
23、在其中一个实施例中,局部加权二部图中点vi和点vj之间的边权重计算方式为:
24、
25、其中,ece(vi)表示点vi的集成簇可靠性度量,ece(vj)表示点vj的集成簇可靠性度量,表示样本集,表示簇集。
26、在其中一个实施例中,变分自编码网络的预训练损失函数为:
27、
28、其中,x表示输入样本,表示重构样本,σ表示输入样本在训练过程中的标准差,μ表示输入样本在训练过程中的均值。
29、另一方面,提供一种基于簇置信度的深度聚类集成装置,包括:
30、预处理模块,用于将待处理的原始数据进行预处理和清洗,生成输入样本集;
31、预训练模块,用于利用输入样本集对变分自编码网络进行预训练并计算预训练产生的初始低维嵌入的簇置信度;
32、聚类训练模块,用于基于学生t分布和kl散度损失对变分自编码网络进行聚类损失训练,计算聚类损失训练后产生的最终低维嵌入的簇置信度;
33、得分计算模块,用于根据初始低维嵌入的簇置信度和最终低维嵌入的簇置信度,计算变分自编码网络的最终低维嵌入的簇置信度得分并排序;
34、聚类选择模块,用于在最终低维嵌入产生的各基聚类中,选取簇置信度得分高的前设定数量个最终低维嵌入对应的目标基聚类;
35、集成聚类模块,用于采用局部加权策略计算各目标基聚类中簇可靠性,构建局部加权二部图并采用tcut图切算法对局部加权二部图进行分割,得到输入样本集最终的集成聚类结果。
36、又一方面,还提供一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现上述的基于簇置信度的深度聚类集成方法的步骤。
37、再一方面,还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述的基于簇置信度的深度聚类集成方法的步骤。
38、上述技术方案中的一个技术方案具有如下优点和有益效果:
39、上述基于簇置信度的深度聚类集成方法、装置、设备和介质,通过对待处理的原始数据进行预处理和清洗等处理后,生成输入样本集,然后利用输入样本集对变分自编码网络进行预训练并计算预训练产生的初始低维嵌入的簇置信度,再基于学生t分布和kl散度损失进行聚类损失训练,计算聚类损失训练后产生的最终低维嵌入的簇置信度,进而计算变分自编码网络的最终低维嵌入的簇置信度得分并排序后,选取簇置信度得分高的前设定数量个最终低维嵌入对应的目标基聚类作为后续聚类集成输入,最后采用局部加权策略计算各目标基聚类中簇可靠性,构建局部加权二部图并采用tcut图切算法对局部加权二部图进行分割来获得最终的集成聚类结果。
40、与传统方法相比,上述方案结合了簇置信度评估和聚类集成方法,将原始无标签的样本数据映射到低维(深度)嵌入,构建簇置信度评估低维深度嵌入的质量并引入聚类集成方法,实现了鲁棒性和聚类表现都更好的聚类结果。
- 还没有人留言评论。精彩留言会获得点赞!