基于局部存储器的主核与从核之间消息传递系统
本发明涉及众核处理器的领域,具体涉及基于局部存储器的主核与从核之间消息传递系统。
背景技术:
1、(1)国产众核处理器体系结构
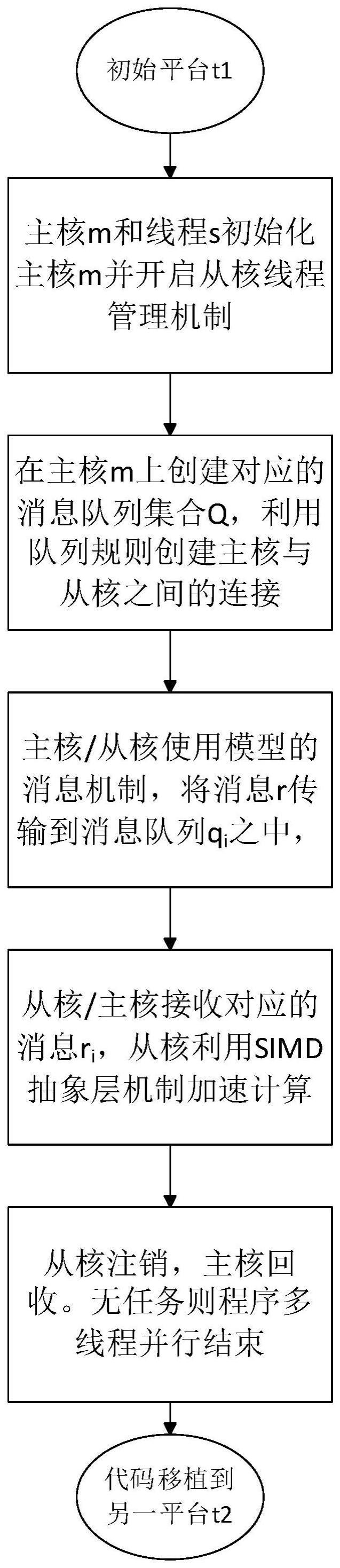
2、如图1所示,一颗sw26010微处理器(haohuan fu,junfeng liao.the sunwaytaihu light supercomputer:system and applications[j].science chinainformation sciences,2016,59(7):1-16)包含了4个异构群。每个异构群包括一个主核和64个从核构成的从核簇,主频为1.5ghz,如图2所示。每个异构群的存储器层次关系相同,由异构群内存(8gb)和从核局部存储空间两部分组成。主核具有容量为32kb的l1数据cache和256kb的l2cache(数据和指令)。每个从核具有64kb的局部存储空间和16kb的指令存储,支持256位的simd指令集。从核可以通过直接访问或dma方式访问主存。
3、面向e级高性能计算的加速器芯片(liu sheng,lu kai,guo yang,liu zhong,chen haiyan,lei yuanwu,sun haiyan,yang qianming,chen xiaowen,chen shenggang,liu biwei,lu jianzhuang.a self-designed heterogeneous accelerator forexascale high performance computing[j].journal of computer research anddevelopment,2021,58(6):1234-1237.)采用了cpu+gpdsp的异构融合架构,由多核cpu和4个gpdsp_cluster组成,如图3所示。多核cpu包含了16个ft-c662cpu内核。每个gpdsp_cluster包含6个dsp节点(每个dsp节点包含4个dsp核)。多核cpu采用硬件维护cache一致性,包含16mb的l2cache。gpdsp簇采用80mb的私有存储、24mb的全局共享存储、32gb的hbm存储三级存储结构。在每个dsp核心上包括了64kb的私有标量内存sm和768kb的私有向量内存am。dsp内核采用了超长指令字(very long instruction word,vliw)技术和标向量协同融合的结构.向量部件由16个同构的vpe阵列组成,最高支持1024位的simd指令操作。
4、(2)国产众核处理器体系结构抽象
5、以sw26010、面向e级高性能计算的加速器芯片为例,国产众核高性能微处理器具有以下特点:
6、1、它们都采用了非对称的结构,包括少量复杂的主核和数量众多的较为简单的计算核,主处理器负责处理复杂的逻辑控制任务,协处理器负责处理计算密度高、逻辑分支简单的大规模数据并行任务。
7、2、每个计算核都具有独立的局部存储器空间,而且这些存储器空间不具备cache一致性,需要程序员通过显式程序控制系统主存与各个计算核存储器之间的数据交换。
8、3、主核和从核之间的数据交换有两种方法:1)从核直接访问主核的内存空间,延迟较长,仅仅适用于传递控制信息;2)从核启动的dma过程,可以传输规模较大的数据。
9、4、从核上支持simd指令,不同处理器的simd宽度各不相同。
10、5、从核上不具备多进程(线程)的操作系统支持,仅仅支持一个线程在从核上运行。不同的处理器具有不同的从核线程编程接口。
11、可以使用图4所述的抽象结构描述这两种不同类型的众核处理器。一个主核和n个从核构成一个完整的处理器簇。主核通过片上cache并访问主存。从核具有局部存储器,且不支持cache一致性协议,由dma完成主核内存和从核之间的数据交换。每个从核上都具有simd指令系统。不同的处理器中,simd的数据宽度不尽相同。表1给出了sw26010和面向e级计算的异构融合加速器的主要体系结构参数。
12、(3)已有多核处理器编程模型
13、openmp(de supinski b r,scogland t r w,durana,et al.the ongoingevolution of openmp[j].proceedings of the ieee,2018,106(11):2004-2019.)是当前对称多处理器系统上的常见多线程编程接口,得到了广泛支持。基于该标准开发的应用程序具有良好的可移植性。
14、cilk(leiserson,charles e.;plaat,aske(1998)."programming parallelapplications in cilk".siam news.31.)是一种基于任务的多线程并行编程扩展。在此基础上,cilk++(leiserson c e.the cilk++concurrency platform[j].the journal ofsupercomputing,2010,51(3):244-257.)使用了_cilk_for、_cilk_spawn和_cilk_sync三个关键字对c/c++进行并行扩展。运行时应用分而治之的方法在工作线程之间调度任务,以确保多个线程负载均衡。
15、intel公司提出了开源线程构建库tbb(threading building blocks)(anonymous"intel threading building blocks;outfitting c++for multi-coreprocessor parallelism,"scitech book news,vol.32,(3),2008.//reinders j.intelthreading building blocks:outfitting c++for multi-core processor parallelism1st edition)。tbb以任务为调度单位,并在posix和windows线程库上具有可移植性。2018年,intel公司又公布了oneapi的软件编程框架。oneapi旨在提供一个适用于cpu、gpu、fpga、神经网络处理器,或者其他硬件加速器的统一编程模型和应用程序接口。oneapi的核心是data parallel c++(dpc++)(james reinders et al.data parallel c++[m].apress,berkeley,ca,2021.gerhard r.joubert,hugh leather,mark parsons,franspeters,mark sawyer,ruyman reyes,victor lomü,ller.sycl:single-source c++accelerator programming[j].advances in parallel computing,2016,27.)的编程语言,dpc++本质上是c++的扩展,增加了对sycl编程模型的支持,可以支持跨cpu和加速器上的数据并行和异构编程,以简化编程以及提高代码在不同硬件上的可重用性,同时能根据特定的加速器进行调优。
16、以sw26010、面向e级计算的异构融合加速器为例,sw26010众核处理器提供了一套创建和管理线程的athread函数库,每个线程绑定一个从核。在athread中,主核接口部分负责控制线程的创建回收、线程调度控制、中断异常管理、异步掩码支持等操作。从核接口部分负责发起数据传输、执行核心计算、线程识别和中断发送等操作。
17、面向e级计算的异构融合加速器上使用了hthread多线程编程接口。该编程接口包含主核端程序编程接口和从核设备端程序编程接口,其中宿主端编程接口主要包括设备管理、镜像管理、线程管理、设备端存储管理和设备端共享资源管理;设备端程序编程接口主要包括并行管理接口、dsp片上存储管理接口、同步管理、终端/异常处理函数接口以及向量化函数接口。
18、综上所述,提高应用软件在不同硬件平台上的可移植性已经成为国际高性能软件编程模型的主要工作方向。但国产高性能众核微处理器的体系结构和操作系统具有自己的特色,难以直接使用已有的编程模型,而且互不通用,严重阻碍了国产高性能软件的发展。与此同时,当前simd编程模型也存在一些问题,如openmp、cilk++需要编译器版本支持,mal仅支持部分isa中的宏,无法用于国产众核处理器,vc库和gsimd方法对simd指令进行了封装,用户不直接操作向量指令,由库来填充向量宽度,其支持的指令集同样也十分有限。
技术实现思路
1、我国自主开发的sw26010和面向e级计算的异构融合加速器等高性能众核处理器采用少量主核+多个从核的体系结构,从核采用不带cache一致性的局部存储器,与传统smp(对称多处理器)和cc-uma(cache一致性的统一存储器访问)结构有较大差异。同时,从核上线程使用、局部存储器数据传输等接口也是每种处理器所独有的,也与国际常见标准存在较大差异。这直接导致两个问题:1)需要直接使用最底层的接口开发国产高性能众核处理器软件,而且一般只能远程连接到超算中心调试,软件开发较为困难;2)不同国产高性能众核处理器上的国产软件不能通用,使得原本就非常薄弱的国产软件研发力量更为分散,造成了很多重复性开发工作。
2、本发明提出的基于局部存储器的主核与从核之间消息传递系统,提出了主核和从核之间消息传递的一般方法,在x86微处理器、sw26010处理器、面向e级计算的异构融合加速器等不同平台上提供通用的消息传递编程接口。与传统的基于国产高性能众核处理器的独有接口编程相比,具有以下优点:1)编程模型简单易学,降低了编程难度;2)应用软件可以在仅仅修改编译器配置的情况下在不同类型的国产高性能微处理器上快速迁移;3)在软件开发方法上,可以首先使用基于x86平台上的模型开发和调试高性能计算软件,然后再将应用软件移植到国产高性能众核处理器上,可以有效减少开发的难度。这些特点将有效提升国产高性能计算软件开发和迁移的效率。
3、本发明的目的至少通过如下技术方案之一实现。
4、基于局部存储器的主核与从核之间消息传递系统,包括主核集合m,分别记为m1,…,m|m|,其中|m|表示主核集合m中主核的数量;主核mi对应一个或多个从核集合sa,且满足|sa|=|sb|,|sa|表示从核集合sa中的从核数量,1≤a,b≤m;
5、通过从核线程管理接口,一个主核mi可以管理从核集合si,1≤i≤|m|;
6、其中,在创建第i个主核mi到第i个从核集合si中的第j个从核si,j的第k个消息队列qi,j,k时,其中,si,j∈si,1≤j≤|si|,1≤k,可以利用调用接口在主核mi和从核si,j的内存中创建对应的消息队列qi,j,k,所有的主核mi到从核si,j的消息队列qi,j,k构成了集合q,qi,j,k∈q,完成主核mi和从核si,j之间的连接;
7、主核mi或从核si,j通过消息发送机制,将一系列的消息rx,,传输到消息队列qi,j,k之中,得到消息序列集合r,对其中的消息进行有序的发送,1≤x,rx∈r;
8、从核si,j或主核mi根据消息队列qi,j,k的相关信息,从消息序列r中选择对应的消息rx,其中rx∈r,1≤x≤|r|,用户获取消息rx,完成自定义的对消息rx的处理后,消息队列qi,j,k中释放该消息rx所用内存;
9、从核si,j处理完数据之后注销从核si,j的缓存,主核mi的运行线程回收从核si,j的线程并继续处理主核mi的其余任务,若没有任务则主核mi注销缓存,程序多线程并行结束。
10、进一步地,在主核上创建消息队列,需要指明以下参数:
11、字符串类型的消息队列名称qname、连接的从核编号slaveid、消息的尺寸msgsize、消息队列在主核部分容纳的消息数量msize、在从核部分容纳的消息数量ssize、主核消息队列的起始地址mqaddr、消息队列在从核中所占用的存储器类型stype以及消息队列的方向direction;调用成功后将返回句柄号handle;
12、其中,主核以(从核编号,句柄号)或者(从核编号,队列名称)标识一个队列实体;从核以句柄号或者队列名称作为队列的唯一标识号,以确定唯一的队列实体;同一个的队列在主核上的句柄与从核上的句柄相同;
13、消息队列仅仅用于主核和从核之间的通信,用户可以指定队列所在的从核slaveid;在一对主核和从核之间,可以设置多个;不同的消息队列;
14、消息队列中每个消息的尺寸不大于msgsize个字节;
15、一个消息队列分布在主核存储器和从核的局部存储器中,两者容纳的消息数量分别为msize和ssize;
16、消息队列在主核存储器上的起始地址是由应用程序指定的连续存储器空间,起始地址为mqaddr;
17、如果从核上的局部存储器具有不同类型,可以通过从核存储器类型stype指定该消息队列所占用的局部存储器类型;
18、消息队列采用单向,分为主核写入/从核读出,从核写入主核/读出两种方向,由direction参数指定;
19、主核可以在主核与一个从核之间创建多个消息队列,主核与全部从核之间的消息队列构成了消息队列集合;
20、主核根据从核线程管理接口完成对从核线程的控制,主要为接口创建并启动从核线程组、等待线程组终止、关闭线程组、主核加载镜像文件到设备。
21、进一步地,一个消息队列在主核部分和从核部分都具有一块连续的存储空间存放消息内容,两者能容纳的消息数量分为msize和ssize,所占用的存储器容量分别为msize×msgsize字节和ssize×msgsize字节;消息队列从核部分的容量受限于局部存储器的容量;
22、每个消息队列的控制信息布局分为两个部分:状态列表和位置索引;
23、位置索引分为:与主核位置相关的imtran、imready、imlocked和imidle,与从核位置相关的istran、isready、islocked和isidle;根据消息队列方向的不同也会有不同的设计,在主核发往从核的消息队列控制信息布局中,imlocked和imidle存储在主核地址区域;imtran、imready和其余4个位置索引均位于从核局部存储器;而在从核发往主核的消息队列控制信息布局中imready、imlocked和imidle存储在主核地址区域;imtran和其余4个位置索引均位于从核局部存储器;
24、imtran表示主核空间中第一个消息块状态为传输中的消息位置索引;imready表示主核空间中第一个消息块状态为消息准备好的消息位置索引;imlocked表示主核空间中第一个消息块状态为消息锁定中的消息位置索引;imidle表示主核空间中第一个消息块状态为消息空闲中的消息位置索引;
25、istran表示从核空间中第一个消息块状态为传输中的消息位置索引;isready表示从核空间中第一个消息块状态为消息准备好的消息位置索引;islocked表示从核空间中第一个消息块状态为消息锁定中的消息位置索引;isidle表示从核空间中第一个消息块状态为消息空闲中的消息位置索引;
26、状态列表中每个状态与环形的消息块数据区中的每个消息块一一对应;主核部分的消息块状态列表和从核部分的消息块状态列表分别记为mstate和sstate,分别处于主核地址区域和从核局部存储器;
27、一个消息队列分为主核部分和从核部分;
28、在消息队列创建时,主核部分和从核部分能容纳的消息数量就已经确定;
29、消息队列控制信息布局中的位置索引会根据消息队列方向的不同而有不同的设计,将主核不必要的变量放置在从核中存储,可以减少从核代码对主核变量的访问,从而提高模型的性能。
30、进一步地,在主核到从核的消息队列中,一个消息块在主核部分的状态包括:masteridle,masterlocked,masterready,mtransferring;一个消息块在从核部分的状态包括slaveidle,stransferring,slaveready,slavelocked;每个消息块的状态信息都存储在各自存储器中;
31、消息队列创建后,主核部分所有的消息块都处于masteridle状态,从核部分所有消息块处于slaveidle状态;
32、masteridle表示主核中该消息块为空闲可分配状态,masterlocked表示主核中该消息块为锁定状态,masterready表示主核中该消息块为准备好可使用状态,mtransferring表示主核中该消息块为传输中状态;
33、slaveidle表示从核中该消息块为空闲可分配状态,stransferring表示从核中该消息块为传输中状态,slaveready表示从核中该消息块为准备好可使用状态,slavelocked表示从核中该消息块为锁定状态;
34、基于局部存储器的主核与从核之间消息传递系统为主核应用程序所提供的接口包括:
35、m1、mallocatemsg(),在消息队列主核部分获得一个消息块的地址;
36、m2、msendmsg(),启动主核向从核传递消息;
37、m3、mrecvmsg(),接收一个从核发送来的消息;
38、m4、mreleasemsg(),释放一个主核部分的消息;
39、所述的消息队列系统为从核应用程序所提供的接口包括:
40、s1、srecvmsg(),接收一个主核发送来的消息;
41、s2、sreleasemsg(),释放一个从核部分的消息;
42、s3、sallocatemsg(),在消息队列从核部分获得一个消息块的地址;
43、s4、ssendmsg(),启动从核向主核传递消息;
44、上述接口中,m1、m2、s1和s2用于主核向从核传递消息,m3、m4、s3和s4用于从核向主核传递消息。
45、进一步地,从主核向从核发送一个消息的操作序列包括:
46、a1、主核应用程序调用mallocatemsg();基于局部存储器的主核与从核之间消息传递系统在消息队列的主核部分中分配一个位置索引imidle指向的空闲的消息块,设置该块为masterlocked状态,循环移动imidle,将该块地址mastermsg返回给主核应用程序;
47、a2、主核应用程序在mastermsg指向的空闲消息块中设置需要发送的消息;
48、a3、主核应用程序调用msendmsg(),取得位置索引imlocked指向的第一个消息块mastermsg,基于局部存储器的主核与从核之间消息传递系统将设置消息块mastermsg为masterready状态,循环移动imlocked;
49、a4、基于局部存储器的主核与从核之间消息传递系统在设定的时机,为需要传输的消息块在从核部分分配一个位置索引isidle指向的空闲的消息块消息存储空间slavemsg,循环移动isidle;启动dma将mastermsg中的消息块传输slavemsg,取得位置索引imready指向的第一个消息块mastermsg,并将消息块mastermsg设置为mtransferring状态,将slavemsg设置为stransferring状态;当dma传输结束后,基于局部存储器的主核与从核之间消息传递系统将从核消息块位置索引istran指向的消息块slavemsg设置为slaveready状态,将主核消息块位置索引imtran指向的消息块mastermsg设置为masteridle状态;
50、a5、从核应用程序调用srecvmsg();消息队列向从核应用程序返回已经处于从核部分的位置索引isready指向的消息块slavemsg,将其设置为slavelocked;
51、a6、从核应用程序读取slavemsg中的内容;
52、a7、从核应用程序调用sreleasemsg();消息队列将从核消息块slavemsg设置为slaveidle状态;
53、从核向主核发送一个消息的操作序列包括:
54、b1、从核应用程序调用sallocatemsg();基于局部存储器的主核与从核之间消息传递系统在消息队列的从核部分中分配一个位置索引isidle指向的空闲的消息块,设置该块为slavelocked状态,循环移动isidle,将该块地址slavemsg返回给主核应用程序;
55、b2、从核应用程序在slavemsg指向的空闲消息块中设置需要发送的消息;
56、b3、从应用程序调用ssendmsg();取得位置索引islocked指向的第一个消息块slavemsg,基于局部存储器的主核与从核之间消息传递系统将设置消息块slavemsg为slaveready状态;循环移动islocked;
57、b4、基于局部存储器的主核与从核之间消息传递系统在设置的时机,为需要传输的消息块在从核部分分配一个位置索引imidle指向的空闲的消息块消息存储空间mastermsg;启动dma将slavemsg中的消息块传输mastermsg,并将消息块mastermsg设置为mtransferring状态,将slavemsg设置为stransferring状态;当dma传输结束后,基于局部存储器的主核与从核之间消息传递系统将主核消息块位置索引imtran指向的mastermsg设置为masterready状态,将从核消息块位置索引istran指向的slavemsg设置为slaveidle状态;
58、b5、主核应用程序调用mrecvmsg();消息队列向主核应用程序返回已经处于主核部分的位置索引imready指向的一个消息块地址mastermsg;
59、b6、主核应用程序读取mastermsg中的内容;
60、b7、主核应用程序调用mreleasemsg();消息队列将主核消息块mastermsg设置为masteridle状态;
61、主核或从核的应用程序直接在消息队列所管理的内存区域中读出和写入消息块的内容,而无需将消息内容搬移到其他内存空间;这样既可以减少消息内容的数据搬移开销,又可以有效减少从核局部存储器的使用量;
62、主核或从核应用程序仅仅启动消息的传输或者接收消息,而不需要考虑消息在主核和从核之间传输的具体实现;由基于局部存储器的主核与从核之间消息传递系统完成消息传输的实现;这样一方面简化了应用程序设计,同时应用程序也具有更好的可移植性。
63、进一步地,主核和从核之间的阻塞式消息传输过程具体如下:
64、消息队列在每个消息队列中都将维护一个dma请求集合dmareqs;该集合初始化为空集;
65、在主核发送消息/从核接收消息的过程中,应用程序调用接口srecvmsg();在srecvmsg()中,按照下述步骤执行:
66、a1.判断本消息队列的dma请求集合dmareqs是否为空,若是,执行步骤a2,否则执行步骤a3;
67、a2.依次检查dmareqs中的每个请求req,查看请求req是否完成dma,未完成则忽略,完成则设置req.smsg状态为slaveready,设置req.mmsg状态为masteridle,并在dmareqs中去除req;
68、a3.判断从核部分是否可以取得处于slaveidle状态的消息块smsg,主核部分是否可以取得处于masteready状态的消息块mmsg,若是则执行步骤a4,否则直接执行步骤a5;
69、a4.设置mmsg对应消息块的状态为mtransferring状态,设置smsg对应消息块的状态为stransferring状态,启动从mmsg到smsg,长度为msgsize个字节的异步dma请求,req={mmsg,smsg},在dmareqs中加入req,再次执行步骤a3;
70、a5.如果从核部分消息中具有消息处于slaveready状态,则设置最早的一个slaveready状态消息msg为slavelocked状态,返回msg到应用程序结束,否则执行步骤a1;
71、其中,dma请求集合dmareqs初始化为空;
72、在从核发送消息/主核接收消息的过程中,从核应用程序调用接口ssendmsg();在ssendmsg()中,按照下述步骤执行:
73、b1.判断本消息队列的dma请求集合dmareqs是否为空,若是则执行步骤b2,否则执行步骤b3;
74、b2.依次检查dmareqs中的每个请求req,查看请求req是否完成dma,未完成则忽略,完成则设置req.smsg状态为slaveidle,设置req.mmsg状态为masterready,并在dmareqs中去除req;
75、b3.判断从核部分是否可以取得处于slaveready状态的消息块smsg,主核部分是否可以取得处于masteridle状态的消息块mmsg,若是则执行步骤b4,否则直接执行步骤b5;
76、b4.设置mmsg对应消息块的状态为mtransferring状态,设置smsg对应消息块的状态为stransferring状态,启动从mmsg到smsg,长度为msgsize个字节的异步dma请求,req={mmsg,smsg},在dmareqs中加入req,再次执行步骤b3;
77、b5.如果从核部分此次发送的消息处于slavelocked状态,则设置此slavelocked状态消息msg为slaveready状态,返回msg到应用程序结束,否则执行步骤b1;
78、其中,dma请求集合dmareqs初始化为空。
79、进一步地,从核访问主核的内存空间具有直接访问和异步dma传输两种不同方式;直接访问方式效率较低,适合于少量数据访问;异步dma传输方式分为启动dma传输过程和查询dma结果两个步骤;启动dma传输后,软件系统无需等待dma结束就完成其他工作,并通过查询dma结果得知是否dma是否已经完成;
80、在阻塞主核发送消息/从核接收消息的过程中,只有在从核接收到主核的消息后才返回,否则将一直等待主核发送消息;
81、从核在接收消息时,将启动主核部分中已经处于masterready状态消息的dma传输过程;在从核部分具有两个或以上消息块且主核发送消息的速度高于从核使用消息的速度时,可以实现从核应用程序读取消息和dma传输过程并行完成。
82、进一步地,消息队列是由主核创建,会在主核和从核均产生一个新的队列句柄handle;在主核方面,将按照不同从核编号分区设置句柄,在从核方面,句柄号handle或者队列名称qname就可以确定唯一的队列实体;同一个的队列在主核上的句柄包括从核上的句柄,即主核上(slaveid,handle)对应的队列与第slaveid个从核上对应的句柄为handle的队列为同一个队列实体;通过消息队列的标识号handle,可以查询到特定消息队列的状态,主要包括队列是否存在、方向、消息的尺寸以及当前队列中消息的数量;
83、基于局部存储器的主核与从核之间消息传递系统为主核应用程序所提供的接口包括:
84、m5、mqueryqueue(),查询消息队列是否存在;
85、m6、mqueuedirection(),获取消息队列的队列方向;
86、m7、mqueuemsgnuminmaster(),获取消息队列的控制核心部分能容纳的消息数量;
87、m8、mqueuemsgnuminslave(),获取消息队列的计算核心部分能容纳的消息数量;
88、m9、mqueuemsgsize(),获取消息队列的队列每个消息的最大字节数;
89、m10、mqueuemsgslavememtype(),获取消息队列中从核部分的存储器类型;
90、m11、mqueuemsgnumstatus(),获取消息队列的动态信息;
91、m12、mcreatequeue(),创建消息队列;
92、基于局部存储器的主核与从核之间消息传递系统为从核应用程序所提供的接口包括:
93、s5、squeryqueue(),查询消息队列是否存在;
94、s6、squeuedirection(),获取消息队列的队列方向;
95、s7、squeuemsgnuminmaster(),获取消息队列的控制核心部分能容纳的消息数量;
96、s8、squeuemsgnuminslave(),获取消息队列的计算核心部分能容纳的消息数量;
97、s9、squeuemsgsize(),获取消息队列的队列每个消息的最大字节数;
98、s10、squeuemsgslavememtype(),获取消息队列中从核部分的存储器类型;
99、s11、squeuemsgnumstatus(),获取消息队列的动态信息;
100、其中,接口m5-m12用于在主核上查询相关的消息队列信息,接口s5-s11用于在从核上查询相关的消息队列信息。
101、进一步地,在用户创建一个消息队列时便会产生一个专属的消息队列句柄handle,可以通过句柄号或者队列名称来获取这个唯一的消息队列;
102、在主核与从核方面都可以获取消息队列相应的状态信息;主核因为要与多个从核进行通信所以(从核编号,句柄号)或者(从核编号,队列名称)可以确定唯一的队列实体;在从核方面,句柄号handle或者队列名称qname就可以确定唯一的队列实体。
103、进一步地,设置如下接口用于不同高性能众核处理器上,涵盖了主核与从核通信所需要的步骤,包括主核上的从核管理机制,使用这些接口可以让代码在完成相应功能的同时,快速的可移植到多种高性能众核处理器;在移植到新平台时,只需要将代码重新编译,编译时指定对应平台的编译选项即可;
104、基于局部存储器的主核与从核之间消息传递系统为主核应用程序所提供的接口包括:
105、m13、mhaltdevice:退出加速设备的运行环境();
106、m14、mhmessqueueinit:控制核心部分缓存的初始化方法();
107、m15、mhmessqueuequit:控制核心部分缓存的注销方法();
108、m16、mloaddatfile:加载镜像文件到设备,仅mt3需要使用();
109、m17、munloaddatfile:卸载镜像文件到设备,仅mt3需要使用();
110、m18、mgetslavecorenum:获取计算核心数:控制核心部分缓存的注销方法();
111、m19、mgetmemsize:获取控制核心和计算核心的存储大小,单位为字节
112、m20、mgetslavesimdlanes:获取计算核心的simd指令并行处理的通道数
113、m21、minitdevice:加载加速设备的运行环境()
114、m22、mgetinitthreadid:获取初始化的线程数据结构
115、m23、mstartslavethreads:创建并启动,绑定计算核心的线程组
116、m24、mwaitslavethreads:等待线程组终止
117、m25、mdestroyslavethreads:关闭线程组
118、m26、mslavethreadactive:获取计算核心的线程是否活跃
119、基于局部存储器的主核与从核之间消息传递系统为从核应用程序所提供的接口包括:
120、s12、shmessqueueinit():消息队列从核初始化;
121、s13、shmessqueuequit:计算核心部分缓存的注销方法(),获取消息队列的队列方向;
122、s14、sgetslavenum:获取计算核心数(),获取消息队列的控制核心部分能容纳的消息数量;
123、s15、sgetslaveid:获取当前计算核心编号(),获取消息队列的计算核心部分能容纳的消息数量;
124、s16、squeuemsgsize(),获取消息队列的队列每个消息的最大字节数;
125、s17、ssimdlanes:获取计算核心的simd指令并行处理的通道数(),获取消息队列中从核部分的存储器类型;
126、上述接口中m13-m20用于在主核上查询相关的消息队列信息,m21-m26用于在主核上管理从核线程,s12-s20用于在从核上查询相关的消息队列信息;
127、上述接口涵盖当前不同高性能众核处理器所需要的功能,提供的接口集合i为不同高性能众核处理器底层接口li的并集,1≤i,即i={l1∪l2…;},若在没有相应函数功能的处理器l1上调用接口集合i里的函数i,即i∈i,代码也不会有任何的负面影响;
128、利用宏定义的编程,通过在不同处理器对应不同的预定义的宏,在编译时设置好预定义的宏,在不同高性能众核处理器通过调用相同的接口实现同样的效果,封装了不同众核处理器之间的底层库的差异性。
129、相比于现有技术中,本发明的优点在于:
130、本发明针对国产高性能众核处理器的线程编程库不统一的问题,提供了从核线程管理机制,来用于在多种平台下控制线程;针对每个从核采用独立的存储器空间不具备cache一致性,需要程序显式控制系统主存与各个计算核存储器之间的数据交换的问题,本模型提供了消息队列;
131、在此编程模型的支持下,可以首先使用基于x86平台上的模型开发和调试高性能计算软件,然后再将应用软件移植到国产高性能众核处理器上。这样,不仅可以有效减少开发的难度,而且同一个软件可以在两种不同类型的国产高性能微处理器上快速迁移,将有效提升国产高性能计算软件开发和迁移的效率
- 还没有人留言评论。精彩留言会获得点赞!