一种同时支持细粒度形变和多数据流切换的脉动阵列
本发明涉及人工智能加速器设计,具体涉及一种能够高效适用于不同形状矩阵乘法的同时支持细粒度形变和多数据流切换的脉动阵列。
背景技术:
1、随着人工智能技术的兴起,深度神经网络在各种领域中的应用也越来越多。各种深度神经网络虽然结构、规模以及组成网络的算子有明显差异,但都以矩阵乘法作为最常见的基础运算,矩阵乘法占整个网络计算需求的比例极高,因此矩阵乘法的计算效率在极大程度上决定了整个神经网络模型的执行效率。脉动阵列是最常用的矩阵乘法计算架构,以二维计算单元阵列为核心,能够实现高数据重用率、高计算并行度的矩阵乘法计算。
2、目前的脉动阵列在矩阵乘法的计算上仍然存在计算单元利用率过低的问题,特别是面对一些形状特殊的矩阵乘法运算(例如当其中一个矩阵呈现瘦长形状,甚至直接退化为向量时),脉动阵列的计算单元利用率严重降低,无法获得显著的并行加速效果。然而类似的矩阵乘法又不可避免地大量出现在各种神经网络算子中,使得脉动阵列在这些神经网络模型上的计算效率受到极大限制。
3、造成计算单元利用率过低的重要原因在于,目前的脉动阵列要么无法支持动态地改变自身逻辑结构,因而无法适应矩阵形状的变化;要么无法支持多种数据流的切换,导致灵活度大大受限。因此,通过设计一种能够同时支持细粒度形变和多数据流切换的脉动阵列,能够极大地提高其面对各种神经网络模型的计算单元利用率,从而大大提升加速效果。
技术实现思路
1、本发明提供了一种同时支持细粒度形变和多数据流切换的脉动阵列系统,由三部分组成:一组由一种支持四向全双工数据传递和多数据流切换的计算单元组成的二维计算单元阵列;一组细粒度、多模式的片上数据缓存,用于满足脉动阵列在不同形状和数据流下产生的不同存储需求;一个控制器,用于控制脉动阵列和片上数据缓存在不同形状和数据流下实现矩阵乘法的计算。本发明的目的是使得脉动阵列能够动态地、细粒度地改变自身的逻辑形状和数据流,提高脉动阵列在计算各种形状和大小的矩阵乘法时的计算单元利用率和加速效果,从而高效适应各种深度神经网络模型。总体而言,本发明能够支持一个rp行cp列的脉动阵列在min{rp,cp}+1种形状和3种数据流之间任意切换和组合。
2、所述脉动阵列系统实现深度神经网络模型加速的基本过程是:在编译阶段,一个神经网络模型被转化为一个矩阵乘法运算序列,对序列中的每个矩阵乘法,通过贪心算法计算出最优的阵列逻辑形状和数据流;在执行阶段,脉动阵列按序列顺序依次计算每个矩阵乘法,每个矩阵乘法运算都包含一个配置阶段和一个计算阶段;在配置阶段,首先将逻辑形状和数据流的配置信息送入阵列,与此同时,可选地将上一轮的驻留数据移出阵列,并且将这一轮的驻留数据载入阵列;在执行阶段,将非驻留的运算数据按照一定格式送入阵列进行计算,同时可选地将非驻留的运算结果写回到缓存中。
3、所述脉动阵列是由一种特殊计算单元组成的二维阵列,其物理形状表示为(rp,cp),rp和cp分别是阵列的行数和列数。每个计算单元都只与其上下左右四个相邻的计算单元相连,且在四个方向上都能支持全双工的数据传递。当不发生形变时,脉动阵列以物理形状(rp,cp)计算矩阵乘法;当发生细粒度形变时,脉动阵列以逻辑形状(rl,cl)计算矩阵乘法。对于一个正方形的二维阵列(rp=cp),细粒度形变的基本步骤是:第一步,脉动阵列被旋转对称地划分成四个形状相同、相邻但不重叠的子阵列,子阵列形状表示为(rs,cs),满足rs+cs=rp并且rs不超过rp的一半;第二步,四个子阵列被首尾相接地连接起来形成逻辑阵列(rl,cl),根据不同的数据缓存分配情况和子阵列连接情况,连接之后的逻辑形状可能是(4rs,cs),也可能是(rs,4cs)。对于一个非正方形的二维阵列(rp≠cp),细粒度形变的基本步骤类似,但是四个子阵列可能包含两种不同的形状。根据上述形变方案,所述脉动阵列总共能够支持min{rp,cp}+1种不同逻辑形状。
4、所述脉动阵列中,子阵列之间的数据传递方式采用内部路径的方式。内部路径存在于前一个子阵列的尾边界和后一个子阵列的首边界之间,由若干相邻计算单元内部的寄存器和单元之间的短连接构成。内部路径的作用是将数据从前一个子阵列的尾边界,经过若干时钟周期延迟,传递到后一个子阵列的首边界。处于内部路径上的计算单元同时承担了子阵列内部的计算任务和跨子阵列传递数据的任务。内部路径利用相邻计算单元进行数据传递,避免引入跨越计算单元的长连接以及大量额外的多选器,保证了时序约束,降低了设计复杂度。
5、所述脉动阵列支持在三种数据流之间动态切换,分别是输入驻留、权重驻留和输出驻留。对于一个矩阵乘法运算c=ab(a是输入特征矩阵、b是权重矩阵、c是输出特征矩阵),三种数据流分别表示将对应矩阵中的各个元素暂存在各计算单元内部的驻留寄存器中,另外两个矩阵的元素则分别沿着变形后逻辑阵列的横向和纵向传递。例如,对于输出驻留,矩阵乘法产生的部分和(即在形成输出矩阵过程中的中间值)会被暂存在各个计算单元内部的驻留寄存器中,而输入特征矩阵和权重矩阵则分别沿着变形后逻辑阵列的横向和纵向传递。
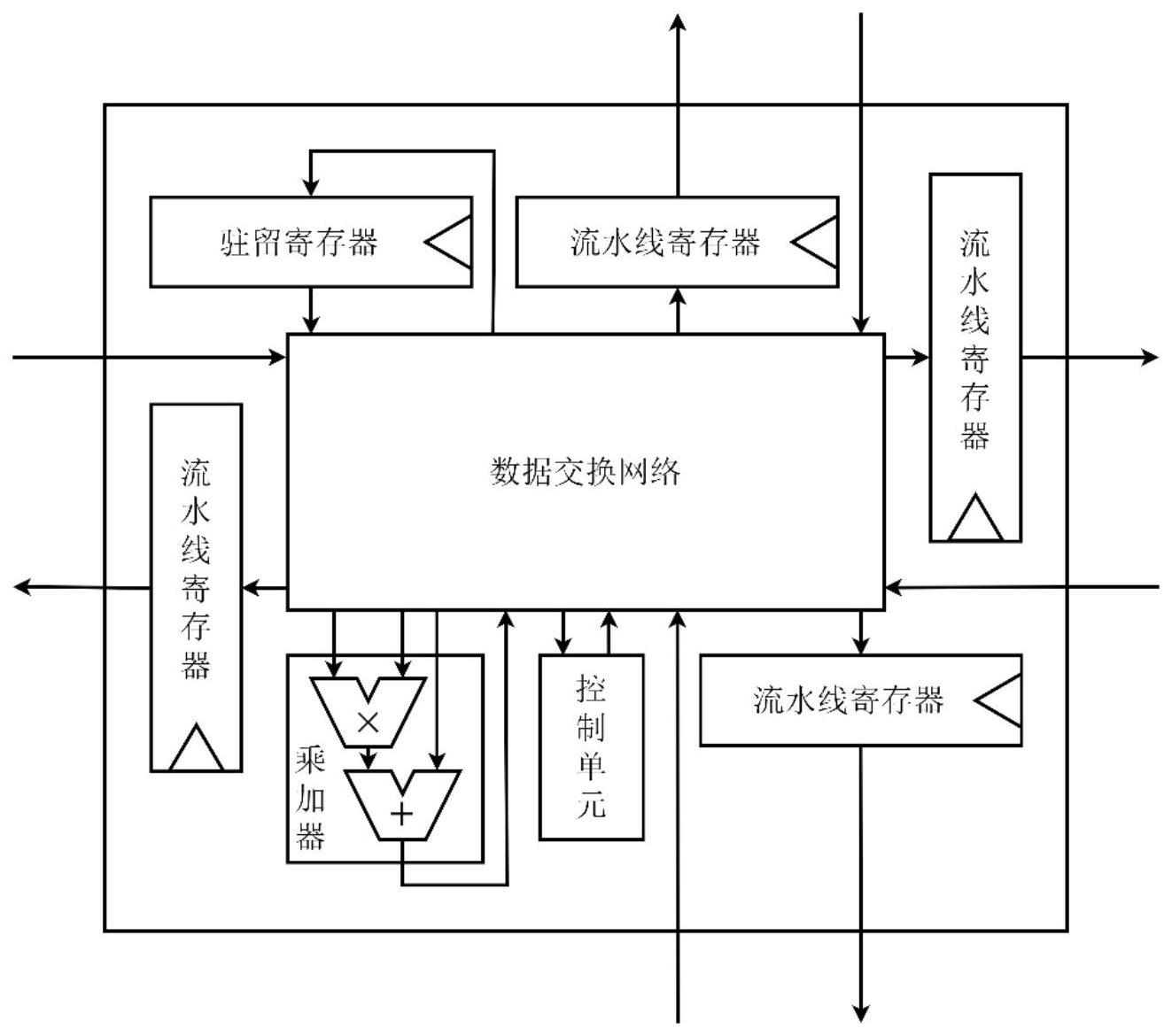
6、所述计算单元是一种支持四向全双工数据传递和多数据流切换的计算单元,包含一个乘加器、一个驻留寄存器、四个流水线寄存器、一个数据交换网络和一个控制单元,在上下左右四个方向上均包含一个输出数据端口和输入数据端口。乘加器的作用是对三个操作数先后进行一次乘法和加法计算,这是构成矩阵乘法的最基本原子运算;驻留寄存器的作用是暂存矩阵乘法中某个矩阵中的元素;流水线寄存器的作用是在相邻计算单元之间暂存一次数据,将关键路径约束在一个计算单元内部;数据交换网络的作用是对来自相邻单元的数据以及本单元内部产生的数据进行选择,并准确送往本单元内部的各个部件;控制单元的作用是存储本计算单元的配置信息,并产生控制信号以指导交换网络的数据流向。
7、所述计算单元中,数据交换网络的作用是对来自相邻单元的数据以及本单元内部产生的数据进行选择,并准确送往本单元内部的各个部件。具体而言,对来自任意方位的相邻单元的数据,交换网络将其可选择地送往另外三个方位中某个方位的流水线寄存器,也可以将其送往乘加器;特别的,对于来自上方的数据,交换网络还将其可选择地送往驻留寄存器或控制单元;对于驻留寄存器的输出数据,交换网络将其可选择地送往乘加器或上方的流水线寄存器;对于累加器的输出数据,交换网络将其可选择地送往四个方位中某个方位的流水线寄存器,也可以送往驻留寄存器。
8、所述计算单元中,控制单元的作用是存储本计算单元的配置信息,并产生控制信号以指导交换网络的数据流向。配置信息根据脉动阵列逻辑形状、数据流以及单元在脉动阵列中的位置的不同而发生变化,当某一种逻辑形状和数据流被选定之后,就可以确定各个计算单元对应的配置信息。在配置阶段,这些配置信息被自上而下地、流水线地传递到相应单元的控制单元中暂存起来。当所有控制寄存器被重新赋值以后,就意味着脉动阵列完成了一次细粒度形变和数据流切换。
9、所述片上数据缓存是一种支持细粒度重分配的多模式数据缓存,包括一个驻留数据缓存和四个非驻留数据缓存。驻留数据缓存用于存储三种数据流各自对应的驻留数据;非驻留数据缓存用于存储另外两种非驻留数据。四个非驻留数据缓存分别置于脉动阵列的四个边界外部。每个非驻留数据缓存被划分为与对应边界计算单元数量相等的若干个缓存块,每个缓存块支持独立读写。当脉动阵列工作在不同的逻辑形状和数据流时,每个缓存块根据所在位置被重分配为存储第一非驻留数据、存储第二非驻留数据或者空闲三种工作模式。
- 还没有人留言评论。精彩留言会获得点赞!