面向段落级文本的中英文语义相似度计算方法
1.本发明涉及信息技术领域,尤其涉及一种面向段落级文本的中英文语义相似度计算方法。
背景技术:
2.现在,随着世界文化交流程度的加强以及各国跨语言之间的资源共享,跨语言场景变得越来越普遍,这导致了跨语言应用需求的越发迫切。为了解决由此带来的技术壁垒,实现跨语言之间的资源共享,学术界和工业界一直都在积极探索跨语言的自然语言处理技术。而其中,跨语言段落语义相似度计算就是一项重要的研究内容,它研究的是如何对不同语言的段落级文本进行语义相似度计算,这在许多跨语言处理应用及其相关领域中扮演着重要角色,如对不同语言申请书的摘要进行语义相似度计算,完成相似申请书的检测和遴选;对不同语言论文的摘要进行语义相似度计算,从而实现相似论文检测,完成跨语言论文推荐和跨语言抄袭检测。
3.现阶段的中英跨语言段落语义相似度计算方法精度还有待提高,其主要存在以下三点不足:(1)跨语言段落语义相似度计算需要解决语言之间的障碍。但是,目前的大多数跨语言相似度检测使用翻译的技巧来解决语言之间的障碍,包括:基于字典、基于平行语料库、基于机器翻译的方法等。相当于把跨语言问题转换为单语或者中间语言之后,再来解决相似度度量的问题。然而,在转换的过程不管是字典、平行语料库、机器翻译都存在缺陷,极有可能丢失文本的一部分深层信息。
4.(2)中英句子表征对齐里的负样本应该与锚样本语义不相似。中英句子表征对齐使用中英平行句对数据集进行训练,对于中英平行句对数据集,当锚样本是中文句子的时候,那么它的正样本是与中文句子平行的英文句子,负样本则需要自己构造,现有方法把其它平行句子对里的英文句子作为负样本,但是这种方法生成的负样本有可能是语义与锚样本相似的假负样本。如果拉开锚样本与假负样本的表征距离,会影响句子表征的对齐,损害中英句子表征模型的性能。
5.(3)段落文本的表征应该同时考虑词、句子和段落三个层次的信息。但是,现在对段落进行表征的方法或强调通过句子层面的信息对段落进行表征,或强调通过词层面的信息对段落进行表征,缺少对段落不同层次信息的信息交互和信息融合,不能有效地从词、句子和段落三个层次同时对段落文本进行完备的表征。
技术实现要素:
6.本发明提供了一种面向段落级文本的中英文语义相似度计算方法,以解决现有的中英跨语言段落语义相似度计算方法精度不高的问题。
7.为实现上述目的,本发明采用如下技术方案。
8.一种面向段落级文本的中英文语义相似度计算方法,包括:
分别对中文段落和英文段落进行段落表征向量提取,包括如下过程:为中文段落/英文段落中的每个主题词构建主题词节点,为中文段落/英文段落的每个句子构建一个句子节点,为中文段落/英文段落构建一个全局段落节点;提取主题词节点、句子节点及全局段落节点的初始化特征向量;根据句子是否含有主题词建立句子节点与主题词节点间的边关系,根据句子在对应段落里的上下文关系建立句子节点之间的边关系,根据主题词在句子里的共现关系建立主题词节点之间的边关系,全局段落节点与每一个主题词节点和句子节点都用一条边连接;每个节点建立一条与自身连接的边;对节点间的边关系进行建模;将所有节点的初始化特征向量及节点间的边关系输入图注意力网络,输出信息交互后各节点的特征向量;分别将主题词节点、句子节点的特征向量作平均池化,然后对平均池化后的主题词节点表征向量、句子节点表征向量与全局段落节点的特征向量进行拼接及降维,得到中文段落/英文段落的段落表征向量;计算中文段落的段落表征向量与英文段落的段落表征向量之间的距离得到中文段落与英文段落的语义相似度。
9.进一步地,在分别对中文段落和英文段落进行段落表征向量提取之前还包括:基于中英平行句对数据集训练得到中英文句子表征对齐模型,该中英文句子表征对齐模型用于提取主题词节点、句子节点及全局段落节点的初始化特征向量。
10.进一步地,所述基于中英平行句对数据集训练得到中英文句子表征对齐模型,包括:从中英文平行句数据集中选定锚样本,与锚样本平行的句子为正样本,其他中英文平行句对中与锚样本语言不同的句子为负样本;对于每个负样本,若其与锚样本的语义相似度大于设定阈值,则该负样本为假负样本,将假负样本的权重赋值为0;否则,将负样本的权重赋值为1;利用去假负样本后得到的训练集对中英文句子表征对齐模型进行训练,得到训练完成后的中英文句子表征对齐模型;其中,中英文句子表征对齐模型包括两个特征提取分支,其中一个分支包括中文句子编码器和平均池化层,另一个分支包括英文句子编码器和平均池化层。
11.进一步地,对于每个负样本,其与锚样本的语义相似度通过如下方法计算:利用单语言句子语义相似度计算模型计算负样本平行的句子与锚样本之间的第一语义相似度作为负样本与锚样本的语义相似度;或,利用单语言句子语义相似度计算模型计算负样本与锚样本平行的句子之间的第二语义相似度作为负样本与锚样本的语义相似度;或,取第一语义相似度和第二语义相似度中的最大值作为负样本与锚样本的语义相似度。
12.进一步地,训练中英文句子表征对齐模型时,目标函数表示如下:
13.其中,和分别表示锚样本为中文句子和英文句子时的对齐
损失函数,表示如下:
[0014][0015]
其中,表示中文句子x与英文句子y的向量相似度;表示温度超参数;表示锚样本的负样本的权重;下标i、j表示中英平行句对的编号,n为该训练批次中中英平行句对的总数。
[0016]
进一步地,所述为中文段落/英文段落中的每个主题词构建主题词节点,为中文段落/英文段落的每个句子构建一个句子节点,包括:利用tf-idf算法提取中文段落/英文段落中的关键词,提取重要性最高的前k个关键词作为中文段落/英文段落的主题词并对应构建主题词节点,分别记录这k个主题词出现的句子序号和在句子中的词序;对中文段落/英文段落进行分句,为中文段落/英文段落的每个句子构建一个句子节点,表示为,c为中文段落/英文段落的句子数。
[0017]
进一步地,所述提取主题词节点、句子节点及全局段落节点的初始化特征向量,包括:对于每个主题词节点,统计其出现的句子序号和在句子中的词序,利用中英文句子表征对齐模型中的中文句子编码器/英文句子编码器对出现对应主题词的句子进行编码,得到句子中每个词的特征向量,根据主题词在句子中的词序提取该主题词的特征向量作为该主题词节点的初始化特征向量;如果该主题词在中文段落/英文段落中出现多次,则将每个位置的主题词的特征向量进行平均池化得到该主题词节点的初始化特征向量;对于每个句子节点,利用中英文句子表征对齐模型中的中文句子编码器/英文句子编码器对句子进行编码得到每个词的特征向量,然后进行平均池化得到特征向量作为该句子节点的初始化特征向量;对所有主题词节点和句子节点的初始化特征向量进行平均池化,得到全局段落节点的初始化特征向量。
[0018]
进一步地,各节点间的边关系通过如下方法确定:如果句子a中含有主题词a,则句子a对应的句子节点与主题词a对应的主题词节点之间建立一条边进行连接;如果句子a和句子b在中文段落/英文段落里有上下文关系,则句子a对应的句子节点与句子b对应的句子节点间建立一条边进行连接;如果主题词a和主题词b在中文段落/英文段落的句子里存在共现关系,则在它们对应的主题词节点之间建立一条边进行连接;全局段落节点与所有的句子节点和主题词节点都建立一条边进行连接;每个节点建立一条与自身连接的边;
节点间的边关系建模表示如下:
[0019]
其中,表示节点p与节点q之间的边关系。
[0020]
进一步地,所述将所有节点的初始化特征向量及节点间的边关系输入图注意力网络,输出信息交互后各节点的特征向量,包括:对于每一层图注意力网络,将上一层图注意力网络输出的节点特征向量作为该层图注意力网络的输入,输出信息交互后各节点的特征向量;其中n为节点总数;第一层图注意力网络的输入为所有节点的初始化特征向量和节点间的边关系;其中,每层图注意力网络构建过程如下:学习一个共享的线性转换w,在节点之间进行自注意力以计算节点之间边的权重,如果节点p和节点q之间有一条边连接的话,则边关系的权重计算公式如下:
[0021]
其中,表示节点q对节点p的重要性,表示两个向量之间的相似度函数;每个节点的邻居节点信息都会传递到该节点身上,其中邻居节点包括该节点自身,对该节点的邻居节点的边关系的权重用softmax进行归一化:
[0022]
其中,是节点p的邻居节点集,m表示节点m;节点p更新后的特征向量表示如下:
[0023]
其中,表示非线性变换函数;将每层图注意力网络最终输出的各节点的特征向量输入到下一层图注意力网络,经过最后一层图注意力网络输出后,得到各节点最终的特征向量。
[0024]
进一步地,中文段落/英文段落的段落表征向量通过如下方法得到:用表示主题词节点的特征向量,用
表示句子节点的特征向量,用表示全局段落节点的特征向量;其中,k为主题词节点总数,c为句子节点总数;分别将主题词节点、句子节点的特征向量作平均池化,表示如下:
[0025]
其中,分别表示平均池化后的主题词节点表征向量、句子节点表征向量;对平均池化后的主题词节点表征向量、句子节点表征向量与全局段落节点的特征向量进行拼接后,再经过两层全连接层进行维度压缩,得到中文段落/英文段落的段落表征向量,表示如下:
[0026]
其中,表示全局段落节点的特征向量,分别表示两层全连接层的权重矩阵,分别表示两层全连接层的偏置系数。
[0027]
本发明提出了一种面向段落级文本的中英文语义相似度计算方法,提出了一种多层次的段落表征方法,能够从主题词、句子和段落三个层次对段落文本进行建模,并基于图注意力网络在各个层次内部和各个层次信息之间进行信息交互,然后融合主题词、句子和段落三个层次的信息得到高质量的段落表征向量,通过计算段落表征向量的距离得到中文段落和英文段落的语义相似度,该方法能实现中英跨语言段落语义相似度的高精度计算,可以应用于对不同语言申请书的摘要进行相似度计算,完成相似申请书的检测和遴选;还可以应用于对不同语言论文的摘要进行相似度计算,从而实现相似论文检测,完成跨语言的论文推荐。
附图说明
[0028]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0029]
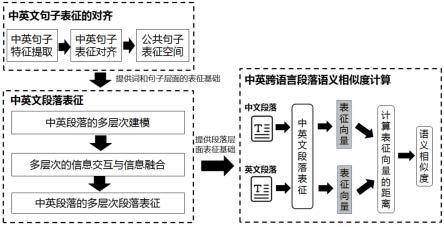
图1是本发明实施例提供的面向段落级文本的中英文语义相似度计算方法整体框架图;
图2是本发明实施例提供的去假负样本的中英文句子表征对齐流程图;图3是本发明实施例提供的正负样本的构建过程示意图;图4是本发明实施例提供的中英文句子表征对齐模型框架示意图,其中,(a)和(b)分别为锚样本为中文句子和英文句子的中英文句子表征对齐模型框架示意图;图5是本发明实施例提供的中英文句子表征对齐后的结果展示图。
实施例方式
[0030]
为使本发明的目的、技术方案和优点更加清楚,下面将对本发明的技术方案进行详细的描述。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动的前提下所得到的所有其它实施方式,都属于本发明所保护的范围。
[0031]
本发明实施例提供了一种面向段落级文本的中英文语义相似度计算方法,首先通过去假负样本的中英文句子表征对齐方法,将不同语言的句子表征对齐到公共的表征空间下,在公共表征空间下句子的相似度可以通过计算句子向量的距离得到,为实现中英文段落表征提供词和句子层面的表征基础。其次提出一种多层次的段落表征方法,能够从主题词、句子和段落三个层次对段落文本进行建模,并基于图注意力网络在各个层次内部和各个层次信息之间进行信息交互,然后融合主题词、句子和段落三个层次的信息得到高质量的段落表征向量,通过计算段落表征向量的距离得到中文段落和英文段落的语义相似度。
[0032]
如图1所示,本实施例提供的面向段落级文本的中英文语义相似度计算方法包括三个阶段:去假负样本的中英文句子表征对齐,基于图注意力网络的多层次中英文段落表征,中英跨语言段落语义相似度计算。
[0033]
s1:第一阶段,去假负样本的中英文句子表征对齐。
[0034]
去假负样本的中英文句子表征对齐方法选取中英平行句对数据集作为训练数据,首先以中英平行句对数据集为基础,选取锚样本并生成对应的负样本与正样本;然后对负样本进行筛选,筛掉假负样本,保留真负样本;在构建中英文句子表征对齐模型后,就可以用锚样本、正样本和真负样本来训练中英文句子表征对齐模型;训练完成后就得了中英文句子表征模型,它能够对中文句子和英文句子进行编码,将它们表示在一个公共的语义表征空间下,通过计算中文句子和英文句子的表征向量间的距离就可以得到句子间的语义相似度。
[0035]
本实施例中基于深度语义的特征提取方法,因为中文和英文之间有大量的中英平行句对语料作为监督信息,能够通过有监督的句子表征对齐方法将不同语言的句子语义表征对齐到一个公共的表征空间下,在公共表征空间下句子的相似度可以通过计算句子向量的距离得到,而不需要翻译成单语言再进行计算,避免了机器翻译过程的翻译偏差可能带来的语义丢失。
[0036]
如图2所示,去假负样本的中英文句子表征对齐包括如下步骤。
[0037]
s11:以中英平行句对数据集为基础,选取锚样本并生成对应的负样本与正样本。
[0038]
对于一个中文句子的锚样本,它的正样本是与它语义相似的英文句子,而负样本是与它语义不相似的英文句子,正样本和负样本的质量会对中英文句子表征对齐模型训练有很大的影响,会使得模型的表征能力下降。目前可用的训练数据集只有中英平行句对数
据集,每个中英平行句对由一对平行的中文句子和英文句子组成,假设一个训练批次里有n对中英平行句对,则对于中文句子来说,它的一个正样本就是与之平行的英文句子,负样本是同一训练批次中其它平行句对里的英文句子。
[0039]
同理,当英文句子作为锚样本的时候,正样本是与之平行的中文句子,负样本是同一训练批次中其它平行句对里的中文句子。
[0040]
s12:对负样本进行筛选,筛掉假负样本,保留真负样本。
[0041]
对于负样本,需要满足与锚样本语义不相似这一条件,但是通过同一训练批次下其它中英平行句对构造的负样本并不一定满足这个条件,需要对负样本进行筛选。对于负样本,如果它与锚样本的语义相似度大于设定阈值,则说明负样本与锚样本是语义相似的,不符合负样本的要求,即这个负样本是假负样本。如果拉开锚样本与假负样本的表征距离,会影响句子表征的对齐,损害中英文句子表征对齐模型的性能。
[0042]
但是因为锚样本与负样本是不同语言的句子,而现有的中英文句子语义相似度计算技术并不成熟(精度不高),不能直接计算它们的相似度,这里提出一种间接计算相似度的方法。当锚样本是中文句子时,如果要与英文句子计算相似度,可以用中文句子的平行英文句子来与英文句子计算相似度得到,同理也可以利用英文句子的平行中文句子来和中文句子计算相似度得到,这里和分别表示中文句子相似度计算和英文句子相似度计算。具体实施时,利用成熟的单语言句子语义相似度计算模型来计算锚样本与负样本的语义相似度,在计算中文句子相似度时,可以利用中文句子编码器roberta-wwm-ext(chinese version)来对中文句子进行编码,然后将编码后得到的词的表征向量进行平均池化得到中文句子的特征向量,然后通过计算两个中文句子的特征向量的余弦相似度得到中文句子相似度;在计算英文句子相似度时,可以利用英文句子编码器bert-base-uncased (english version)来对英文句子进行编码,然后将编码后得到的词的表征向量进行平均池化得到英文句子的特征向量,然后通过计算两个英文句子的特征向量的余弦相似度得到英文句子相似度。
[0043]
因为负样本与锚样本的相似度越大则说明这个负样本是假负样本的可能性越大,为了提高判断假负样本的鲁棒性,在本发明一优选实施例中,中文句子和英文句子的语义相似度取两者的最大值,其表示如下:。
[0044]
得到相似度后,需要设置一个阈值,如果负样本与锚样本的相似度,则说明这个负样本是假负样本,不能用来训练模型,需要通过给假负样本赋权重为0来去除它对模型训练的影响。负样本的权重赋值可表示如下:
[0045]
其中,表示锚样本的负样本的权重。当然,需要说明的是,上述是以锚样本为中文句子为例的说明,图3所示为一个正负样本的构建过程示意图。同理,当以英文句子为锚样本时,上述筛选掉假负样本的过程原理相同,只需对处理对象作对应调整即可。
[0046]
s13:构建中英文句子表征对齐模型。
[0047]
中英文句子表征对齐模型如图4所示,其中图4(a)为锚样本为中文句子的示意图,图4(b)为锚样本为英文句子的示意图。中文句子进入中文句子编码器得到句子中词的表征向量,经过平均池化层得到中文句子的表征向量,英文句子进入英文句子编码器得到句子中词的表征向量,经过平均池化层得到英文句子的表征向量。这里的英文句子编码器采用bert-base-uncased (english version),它是已经训练好的单语言英语句子编码器,可以对英文句子进行语义表征;中文句子的编码器采用roberta-wwm-ext(chinese version),它是已经训练好的单语言中文句子编码器,可以对中文句子进行语义表征。
[0048]
s14:训练中英文句子表征对齐模型。
[0049]
用锚样本、正样本、负样本来训练中英文句子表征对齐模型,训练过程中,损失函数采用infonce loss的变体,当锚样本是中文句子时,正样本是英文句子,负样本是n-1个英文句子。对齐损失函数为:
[0050]
其中,表示中文句子x与英文句子y的向量相似度;表示温度超参数;表示锚样本的负样本的权重;下标i、j表示中英平行句对的编号,n为该训练批次中中英平行句对的总数。对齐损失函数相当于一个n路的softmax分类问题,其中正样本是正确的,而n-1个负样本是错误的。模型的训练目标是拉近锚样本与正样本的向量距离,拉开与负样本的向量距离,从而能够在拉近语义相似的句子在公共语义空间中的表示,同时拉开语义不相似的句子在公共语义空间中的表示,实现对齐到同一表征空间的目的。
[0051]
同理,当锚样本是英文句子时,对齐损失函数为:
[0052]
其中,表示锚样本的负样本的权重。
[0053]
则中英文句子表征对齐模型的目标函数表示如下:。
[0054]
总的来说训练的目的是使得语义相似的句子它们向量间的距离最小化,语义不相似的句子它们向量间的距离最大化,以此来实现不同语言句子表征空间的对齐。
[0055]
目标函数包括两个对齐损失,相当于从两个方向进行对齐(中-》英,英-》中)。举个简单的例子,有下面四对中英平行句子对来训练模型:
①ꢀ
英语是使用最广泛的语言。 english is the most widely spoken language.
②ꢀ
汉语是使用人数最多的语言。chinese is the most spoken language.
③ꢀ
世界上现存的语言大约有6909种。 there are about 6909 languages in existence in the world.
④ꢀ
英语的使用最广泛。english is the most widely used.当以平行句[
①
英语是使用最广泛的语言。 english is the most widely spoken language.]来计算loss训练模型时有:1、当把“英语是使用最广泛的语言。”作为锚样本时,正样本是“english is the most widely spoken language.”,负样本是“chinese is the most spoken language.”、“there are about 6909 languages in existence in the world.”和“english is the most widely used.”。对负样本进行筛选可以判断出{“chinese is the most spoken language.”,“there are about 6909 languages in existence in the world.”}是真负样本,而“english is the most widely used.”语义与“英语是使用最广泛的语言。”语义相似,所以是假负样本。我们要在公共表征空间把“英语是使用最广泛的语言。”与“english is the most widely spoken language.”拉近,同时把“英语是使用最广泛的语言。”和真负样本{“chinese is the most spoken language.”,“there are about 6909 languages in existence in the world.”}这两个句子拉远,假负样本不进行拉远。
[0056]
2、当把“english is the most widely spoken language.”作为锚样本时,正样本是“英语是使用最广泛的语言。”,负样本是“汉语是使用人数最多的语言。”、“世界上现存的语言大约有6909种。”和“英语的使用最广泛。”。对负样本进行筛选可以判断出{“汉语是使用人数最多的语言。”,“世界上现存的语言大约有6909种。”}是真负样本,而“英语的使用最广泛。”语义与“english is the most widely spoken language.”语义相似,所以是假负样本。我们要在公共表征空间把“english is the most widely spoken language.”与“英语是使用最广泛的语言。”拉近,同时把“english is the most widely spoken language.”和{“汉语是使用人数最多的语言。”,“世界上现存的语言大约有6909种。”}这两个句子拉远,假负样本不进行拉远。
[0057]
这样双向训练后,对于句子“英语是使用最广泛的语言。”,句子“english is the most widely spoken language.”在表征空间中离它最近,对于句子“english is the most widely spoken language.”,句子“英语是使用最广泛的语言。”在表征空间中也离它最近。如果只训练一个方向,就可能导致这样一个情况:对于句子“英语是使用最广泛的语
言。”,句子“english is the most widely spoken language.”在表征空间中离它最近,而对于句子“english is the most widely spoken language.”,句子“英语是使用最广泛的语言。”在表征空间中并不是离它最近的,也就是可能有其它句子离句子“english is the most widely spoken language.”更近,这样达不到句子表征对齐的目的,所以需要双向对齐。
[0058]
图5所示为中英文句子表征对齐后的结果展示图(中英句子表征对齐以锚样本为“英语是使用最广泛的语言。”作为例子进行展示),在中英句子表征对齐之前,英文句子语义表征空间和中文句子语义表征空间是两个独立的表征空间,这时中文句子和英文句子它们表征向量的距离是不能反映它们语义相似度的。在通过中英句子表征对齐后,通过拉近锚样本和正样本的表征距离,同时拉开锚样本和真负样本的表征距离,将英文句子语义表征空间和中文句子语义表征空间对齐到一个公共的句子语义表征空间下,这样在公共句子语义表征空间下,中文句子和英文句子它们表征向量的距离就能反映出它们的语义相似度。
[0059]
s15:得到中英文句子表征模型。
[0060]
中英文句子表征对齐模型训练完成后,中英文句子表征对齐模型中的中文句子编码器和英文句子编码器就可以作为中英句子表征模型,分别对中文句子和英文句子进行编码得到对应的向量,得到的中文句子向量和英文句子向量是在一个公共的句子语义表征空间下的,通过计算向量间的距离可以得到句子间的语义相似度。
[0061]
s2:第二阶段,基于图注意力网络的多层次中英文段落表征。
[0062]
基于图注意力网络的多层次中英文段落表征具体包括如下过程:s21:从主题词、句子和段落三个层次对中文段落/英文段落进行建模(段落的多层次信息建模)。
[0063]
首先根据段落的主题词和句子构建主题词节点和句子节点,并添加一个全局段落节点,其次根据句子是否含有主题词建立句子节点与主题词节点间的边关系,同时根据句子在段落里的上下文关系和主题词在句子里的共现关系分别建立句子节点之间的边关系和主题词节点之间的边关系,全局段落节点与每一个主题词节点和句子节点都用一条边连接。通过这样的方式从主题词、句子和段落三个层面把段落建模成一个段落图,以作为下一步中英段落表征的输入。具体步骤如下:s211:利用tf-idf算法提取中文段落/英文段落中的关键词,关键词是能够表达段落中心内容的词语,提取重要性最高的前k个关键词作为段落的主题词并对应构建主题词节点,分别记录这k个主题词出现的句子序号和在句子中的词序。
[0064]
s212:对中文段落/英文段落的进行分句,为段落里的每个句子构建一个句子节点,表示为,c为中文段落/英文段落里的句子数。
[0065]
s213:为中文段落/英文段落构建一个全局段落节点。
[0066]
s214:利用中英文句子表征模型对节点的特征进行初始化。
[0067]
假设所构建的段落图中有k个主题词节点,c个句子节点,1个全局节点,一共有n=k
+c+1个节点,按照主题词节点、句子节点和全局节点的顺序对节点进行排序得到,对这些节点进行特征初始化,方法如下:对于每个主题词节点,需要统计主题词在段落里出现的位置(在哪些句子中出现过以及在句子里的位置,即句子序号和在句子中的词序),在对主题词进行编码时,首先将主题词出现的句子输入进中英文句子表征模型中,在经过中文/英文句子编码器对句子编码后,得到每个词的特征向量,根据记录的词序提取出该主题词的特征向量作为该主题词节点的初始化向量;如果主题词在段落里出现了多次,则先分别通过上面方法得到每个位置主题词的特征向量,然后对这些向量进行平均池化得到主题词节点的初始化特征。
[0068]
对于k个主题词节点就可以得到特征向量。这样得到的主题词特征包含了句子的上下文信息,在不同句子里的词根据上下文信息的不同可以有着不同的语义,能够有效解决一词多义问题。
[0069]
句子节点的初始化特征向量就是句子通过中英文句子表征模型进行编码和平均池化后得到的特征向量,对于c个句子节点得到。
[0070]
全局节点的初始化特征向量是其它所有主题词节点和句子节点初始化特征向量进行平均池化后得到的。
[0071]
s215:通过如下方式建立节点间的边关系:(1)如果句子a中含有主题词a,则句子a对应的句子节点与主题词a对应的主题词节点之间建立一条边进行连接;(2)如果句子a和句子b在中文段落/英文段落里有上下文关系,则句子a对应的句子节点与句子b对应的句子节点间建立一条边进行连接;(3)如果主题词a和主题词b在中文段落/英文段落的句子里存在共现关系,则在它们对应的主题词节点之间建立一条边进行连接;(4)全局段落节点与所有的句子节点和主题词节点都建立一条边进行连接;(5)每个节点建立一条与自身连接的边。
[0072]
s216:对节点间的边关系进行建模表示。
[0073]
对于节点p和节点q,如果它们之间有一条边连接,则它们互为邻居节点(节点自己也算作自己的邻居节点)。如果节点p和节点q互为邻居节点则=1,否则=0。节点间的边关系建模表示如下:
[0074]
其中,表示节点p与节点q之间的边关系。
[0075]
s22:基于图注意力网络的信息交互和信息融合。
[0076]
通过图注意力网络对段落图进行处理,在各个节点间进行信息传递,最后通过融合主题词、句子和全局段落信息三个层次的信息生成中文段落/英文段落的段落表征向量。
[0077]
对于每一层图注意力网络,将上一层图注意力网络输出的节点特征向量作为该层图注意力网络的输入,输出信息交互后各节点的特征向量;其中n为节点总数;第一层图注意力网络的输入为所有节点的初始化特征向量和节点间的边关系。每层图注意力网络构建过程如下:为了获得足够的表达能力,学习一个共享的线性转换w,将节点的输入特征转换为更深层次的特征。然后在节点之间进行自注意力以计算节点之间边的权重,如果节点p和节点q之间有一条边连接的话,则边关系的权重计算公式如下:
[0078]
其中,表示节点q对节点p的重要性;表示两个向量之间的相似度函数,这里采用余弦相似度;在信息传递过程中,每个节点的邻居节点信息都会传递到该节点身上,其中邻居节点包括该节点自身,对该节点的邻居节点的边关系的权重用softmax进行归一化:
[0079]
其中,是节点p的邻居节点集,m表示节点m。得到归一化的注意力权重后就可以用来更新节点p的特征,节点p更新后的特征向量表示如下:
[0080]
其中,表示非线性变换函数。
[0081]
将每层图注意力网络最终输出的各节点的特征向量输入到下一层图注意力网络,经过最后一层图注意力网络输出后,得到各节点最终的特征向量。
[0082]
对各节点最终的特征向量进行融合得到中文段落/英文段落的段落表征向量,首先分别将主题词节点、句子节点的特征向量作平均池化,表示如下:
[0083]
其中,分别表示平均池化后的主题词节点表征向量、句子节点表征向量。然后对平均池化后的主题词节点表征向量、句子节点表征向量与全局段落节点的特征向量进行拼接后,再经过两层全连接层进行维度压缩,得到中文段落/英文段落的段落表征向量,表示如下:
[0084]
其中,表示全局段落节点的特征向量,分别表示两层全连接层的权重矩阵,分别表示两层全连接层的偏置系数。
[0085]
s3:第三阶段,中英跨语言段落语义相似度计算。
[0086]
计算中文段落的段落表征向量与英文段落的段落表征向量之间的距离得到中文段落与英文段落的语义相似度similarity:
[0087]
其中,是计算向量间的余弦相似度。
[0088]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1