中文媒体评论文本自动生成方法、系统、设备、客户端与流程
本发明属于舆情数据信息处理,尤其涉及中文媒体评论文本自动生成方法、系统、设备、客户端。
背景技术:
1、现有技术文本自动生成中,多采用文本生成、transformer模型、word2vec、文本相似度计算的方法。
2、通过上述分析,现有技术存在的问题及缺陷为:
3、(1)现有中文文本生成算法中所使用的预训练语言模型在位置编码上通常使用的是绝对位置编码,这种编码方式计算方法简单直接,但在训练时受到文本长度的影响,无法推断其余位置的编码问题,因此存在长度上的限制,使得获得的数据准确度低;
4、(2)当前的中文文本生成算法主要应用于个性化广告文案生成、自动客服对话和诗词对联生成等领域。在评论自动生成特别是多样化中文媒体评论信息自动生成领域中尚缺乏足够的应用。
5、(3)现有的文本生成算法通常在生成文本后就结束流程,缺乏文本筛选和排序手段,无法直接根据真实的需求获取用户想要的文本数据。
技术实现思路
1、为克服相关技术中存在的问题,本发明公开实施例提供了中文媒体评论文本自动生成方法、系统、设备、客户端。还涉及人工智能、深度学习、文本生成技术领域。
2、所述技术方案如下:中文媒体评论文本自动生成方法包括以下步骤:
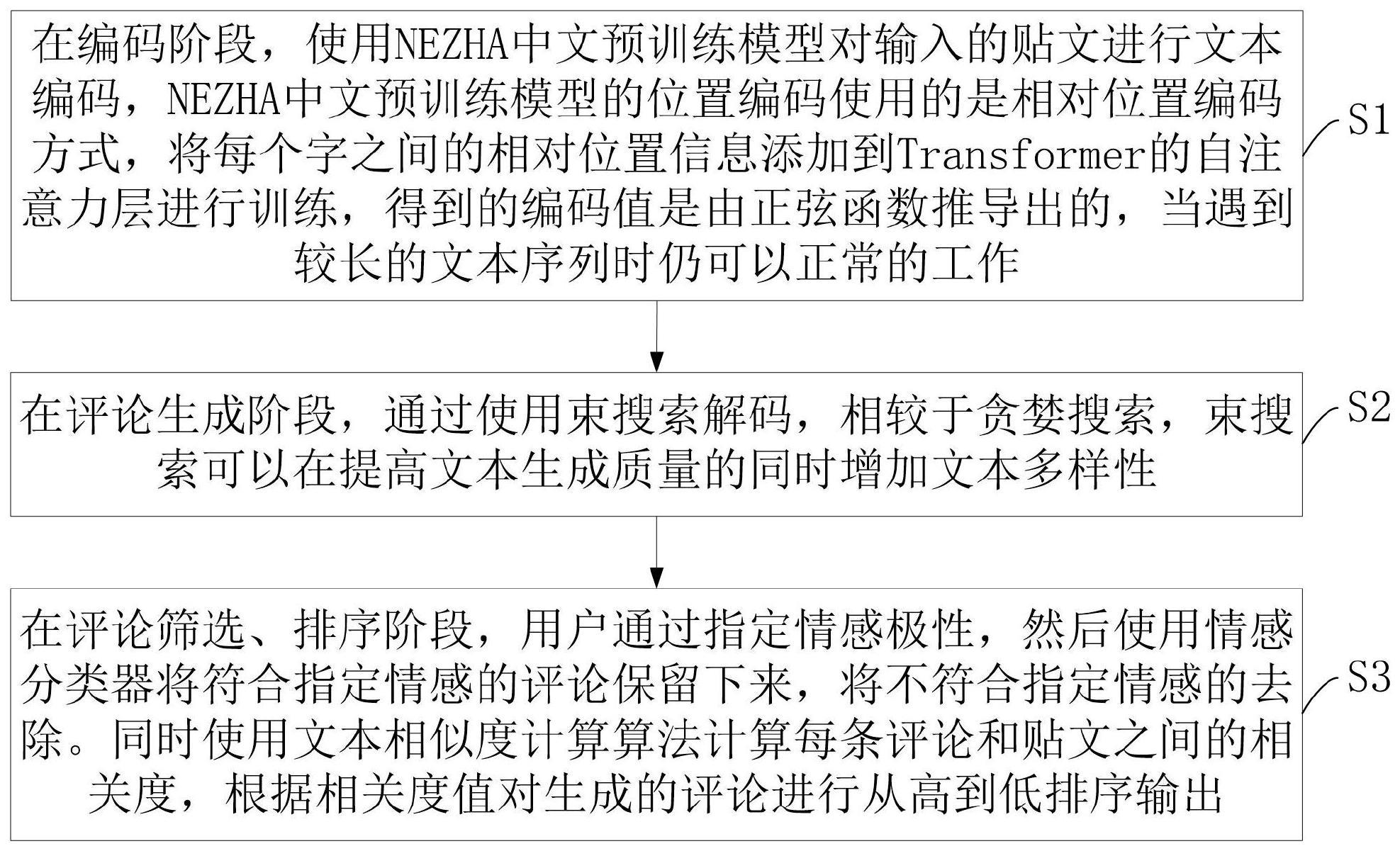
3、s1,使用nezha中文预训练模型对输入的贴文进行文本编码;
4、s2,通过束搜索解码生成多条评论;
5、s3,用户通过指定情感极性,使用情感分类器进行指定情感的评论取舍;并使用文本相似度计算算法计算每条评论和贴文之间的相关度,根据相关度值对生成的评论进行从高到低排序输出评论文本。
6、在步骤s1前,还需进行:数据收集、数据清洗和文本向量化预处理;
7、将收集的前一年时间范围内的中文平台热点贴文和评论文本,清洗处理后作为训练数据集;
8、所述数据清洗预处理包括去除网页链接、去除指定的语种文字、去除无用格式;
9、文本向量化预处理包括:使用transformers分词器将自然语言文本转换为计算机能识别的数值张量。
10、在步骤s1中,nezha中文预训练模型的位置编码使用相对位置编码方式,并使用nezha的预训练权重初始化编码结构中的embedding层权重;将每个字之间的相对位置信息添加到transformer的自注意力层进行训练,并得到编码值。
11、在步骤s2中,通过束搜索解码生成多条评论包括以下步骤:
12、使用预处理模型将贴文转换为语义向量输入在训练好的文本生成模型中,使用束搜索依次生成概率最高的前topk个词语,直至完成n条评论的生成,最后将生成的n条评论进行输出。
13、在步骤s3中,文本相似度计算算法计算每条评论和贴文之间的相关度包括:使用jieba分词系统中的posseg模块对输入的贴文和生成的评论进行分词和词性识别;取贴文和评论中词性为动词、名词和形容词词性的词语作为句子的关键词,贴文文本关键词词集记作:{wp1,wp2,…,wpm},评论文本关键词词集记作:{wc1,wc2,…,wcm};然后使用word2vec依次计算贴文词语和评论词语之间的词语相似度,并取其平均值作为两个句子之间的关键词相似度s1;其中,wp1为第一次输入的贴文进行分词和词性识别后的贴文文本关键词,wp2为第二次输入的贴文进行分词和词性识别后的贴文文本关键词,wpm为第m次输入的贴文进行分词和词性识别后的贴文文本关键词;wc1为第一次生成的评论进行分词和词性识别后的评论文本关键词,wc2为第二次生成的评论进行分词和词性识别后的评论文本关键词,wcm为第m次生成的评论进行分词和词性识别后的评论文本关键词;
14、使用sentence transformers计算贴文和评论之间的语义文本相似度s2,最后经融合得到贴文和评论之间的相关度值。
15、在一个实施例中,关键词相似度s1计算公式为:
16、s1=meani=1…n,j=1…m{simw2v(wpi,wcj)};
17、其中,meani=1…n,j=1…m{simw2v(wpi,wcj)}为计算贴文词语和评论词语之间的词语相似度中两个句子之间的关键词相似度平均值;i,j,n,m均为计算次数,wpi为第i次输入的贴文进行分词和词性识别后的贴文文本关键词,wcj为第j次生成的评论进行分词和词性识别后的评论文本关键词,simw2v(wpi,wcj)为两个句子之间的关键词相似度值,w2v为两个句子之间的关系;
18、语义文本相似度s2计算公式为:
19、s2=λs1+(1-λ)s2;
20、其中,λ=0.4。
21、本发明的另一目的在于提供一种实现所述中文媒体评论文本自动生成方法的系统,该系统包括:
22、所述预处理模块,用于进行数据收集、数据清洗和文本向量化预处理;预处理后的数据作为算法模块的输入;
23、所述算法模块,通过训练阶段和预测阶段生成n条评论文本,并输入后处理模块;
24、后处理模型,用于将生成的n条评论依次使用情感极性判断模型进行情感极性判断,将不符合指定情感的评论进行筛除操作,将符合情感极性的评论再依次计算与输入的贴文之间的语义相关度;并按照相关度计算得分从高到低依次输出评论文本。
25、本发明的另一目的在于提供一种接收用户输入程序存储介质,所存储的计算机程序使电子设备执行所述中文媒体评论文本自动生成方法。
26、本发明的另一目的在于提供一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,所述计算机程序被所述处理器执行时,使得所述处理器执行所述中文媒体评论文本自动生成方法。
27、本发明的另一目的在于提供一种社交网络多样化中文媒体评论信息自动生成客户端,执行所述中文媒体评论文本自动生成方法。
28、本发明的另一目的在于提供一种社交网络多样化中文媒体评论信息自动生成客户端,执行所述中文媒体评论文本自动生成方法。
29、结合上述的所有技术方案,本发明所具备的优点及积极效果为:
30、第一、针对上述现有技术存在的技术问题以及解决该问题的难度,紧密结合本发明的所要保护的技术方案以及研发过程中结果和数据等,详细、深刻地分析本发明技术方案如何解决的技术问题,解决问题之后带来的一些具备创造性的技术效果,具体描述如下:
31、本发明使用nezha中文语言预训练模型解决中文媒体评论文本自动生成算法中文本长度限制的问题。
32、使用束搜索解码算法增加中文媒体评论文本自动生成领域所生成评论文本的多样性。
33、使用情感极性判定算法和文本相关度算法对中文媒体评论文本自动生成领域所生成评论文本进行过滤和排序。
34、第二、把技术方案看作一个整体或者从产品的角度,本发明所要保护的技术方案具备的技术效果和优点,具体描述如下:
35、本发明实现了基于nezha中文语言预训练模型的多样化中文媒体评论自动生成技术,实现了在媒体贴子新发表的初始阶段,评论量不高的时候自动生成多条个性化评论,可以提升该条贴子的热度,提高浏览者的注意力和评论欲望。
36、第三、作为本发明的权利要求的创造性辅助证据,还体现在以下几个重要方面:
37、(1)随着媒体时代的发展,一些商业性质的新发贴文需要在短时间内获得一定的热度和浏览量,本发明可以通过自动生成积极评论提升贴文的热度,从而进一步贴文的点击率,提升贴文的商业价值;此外,对于一些舆论风波较为激烈的贴文,本发明可以通过生成引导性评论,引导浏览者的思考方向,进而达到舆论风控的作用。
38、(2)本发明填补了国内外中文社交媒体评论生成领域中,使用深度学习模型自动生成情感可控评论的技术空白。
- 还没有人留言评论。精彩留言会获得点赞!