基于客户端聚类的个性化联邦学习方法、装置及设备与流程
本发明涉及基于客户端聚类的个性化联邦学习,尤其涉及一种基于客户端聚类的个性化联邦学习方法、装置及设备。
背景技术:
1、传统的联邦学习假设存在一个模型能同时适用于所有客户端的数据分布,通过提取所有参与客户端的共同知识来得到高质量的全局模型。但是这种模式现在正面临如下挑战:1)数据异构:不同客户端上的数据不满足独立同分布性质;2)客户端异构:客户端的计算和存储能力不同;3)模型异构:不同的客户端需要定制化的模型以适应自身的应用环境。换言之,一个共享模型的表达能力是无法同时拟合所有客户端的分布,并且不一定适用于某些性能与众不同的客户端,最终制约模型准确率的提升。
2、例如,物联网场景中某客户端的目标是在全部的人脸图像数据集上训练一个“吸引力”分类器。不同的客户端对“吸引力”的定义不同。客户端a可能认为长发代表吸引力,而客户端b并不赞同。在这种情况下,全局共享模型并不适用于所有客户端。
3、个性化联邦学习在享受知识共享优势的同时,能兼顾客户端的数据分布与业务需求的异构性,给客户端提供个性化模型。联邦多任务学习作为联邦学习个性化手段之一,把为不同终端建立模型看作多个任务,并维持一个全局模型作为参考。每个客户端根据当前参考模型和本地数据,通过施加正则项等方法训练自己的个性化模型。但这种方式忽略了客户端间的相似关系且仅参考一个全局模型,制约了收敛性和训练质量的提高。
4、在经过一定数量的全局迭代之后,客户端会表现出与其数据分布和模型需求高度相关的梯度,因此梯度可作为客户端相似度聚类的标准。但是深度神经网络梯度的高维特征对聚类算法的计算效率有更高的要求。同时,客户端承载业务具有动态性和多样化的特点,传统算法存在对初始聚类中心敏感的问题。
5、为解决上述问题,专利号为cn114492847b的《一种高效个性化联邦学习系统和方法》专利,涉及一种高效个性化联邦学习系统和方法,该系统中的终端设备包括:终端设备数据模块、终端设备模型下载模块、两个终端设备模型训练模块和终端设备模型上传模块,中心服务器包括服务器端数据模块、两个服务器端模型整合模块和服务器端模型派发模块。该发明设计合理,其将剪枝处理及模型训练完全放在终端设备进行,降低了中心服务器的负担,提高了处理效率,并且充分考虑数据分布的差异性,实现了模型的个性化功能,能够有效地对不同终端设备上采集到的数据进行分析,在大幅降低通信成本的同时保证用户的隐私信息和个性化,以及终端设备数据缺失情况下的新模型发送。但此类方法的缺点是不适用于客户端数量较大的场景。
6、专利号为cn112560991a的《基于混合专家模型的个性化联邦学习方法》专利,涉及一种基于混合专家模型的个性化联邦学习方法,该发明为克服大规模无状态的移动联邦环境中私有模型很难实现充分训练的缺陷,提出一种基于混合专家模型的个性化联邦学习方法:所有客户端加入联邦学习共同参与全局模型的训练,得到全局模型参数θg;每个客户端分别从服务器下载θg,并利用该参数初始化客户端中的特征提取层与个性分类层,利用固定基层方法进行个性化获得个性分类层参数;此时客户端i拥有包括特征提取层参数、全局分类层参数的θg和个性分类层参数,利用这三者初始化特征提取层、全局分类层和个性分类层,共同训练门控模型,得到门控模型参数最终客户端获得特征提取层、全局分类层、个性分类层和门控模型的参数,完成个性化联邦学习。该专利根据通过联邦学习得到的全局模型参数,对个性分类层、门控模型的参数进行微调,再利用全局模型和个性分类层单独训练门控模型,实现个性分类层与全局模型的混合,能够提升个性化能力的同时,保留全局知识;该专利将个性分类层和全局模型作为本地和全局的专家,组成混合专家模型,再使用门控模型来将这些专家结合,并采用特征提取层的输出作为门控模型的输入,使门控模型能更有效划分输入数据。但其算法复杂,带来大量的资源开销,并且计算时间较长。
7、专利号为cn112668726a的《一种高效通信且保护隐私的个性化联邦学习方法》专利,涉及一种高效通信且保护隐私的个性化联邦学习方法,包括以下步骤:s1:从中央服务器拉取当前全局模型wt到所有客户端中,初始化各个客户端的本地模型;s2:执行e轮本地训练,得到新的本地模型;s3:将的模型参数发送到中央服务器;s4:在中央服务器中对接收到的模型参数聚合,得到聚合结果wt+1;s5:根据wt+1将所有客户端的本地模型更新;s6:判断是否完成预定迭代次数;若是,则完成个性化联邦学习;若否,则令t=t+1,并返回步骤s2进行下一轮个性化联邦学习。该发明提供一种高效通信且保护隐私的个性化联邦学习方法,解决了现有的个性化联邦学习方法没有实现个性化客户端本地模型与全局模型的平衡的问题。但同样不适用于客户端数量较大的场景。
技术实现思路
1、本发明提供了一种基于客户端聚类的个性化联邦学习方法、装置及设备,解决了传统联邦学习制约个性化模型收敛性能、准确率和精度等技术问题。
2、一种基于客户端聚类的个性化联邦学习方法,包括:
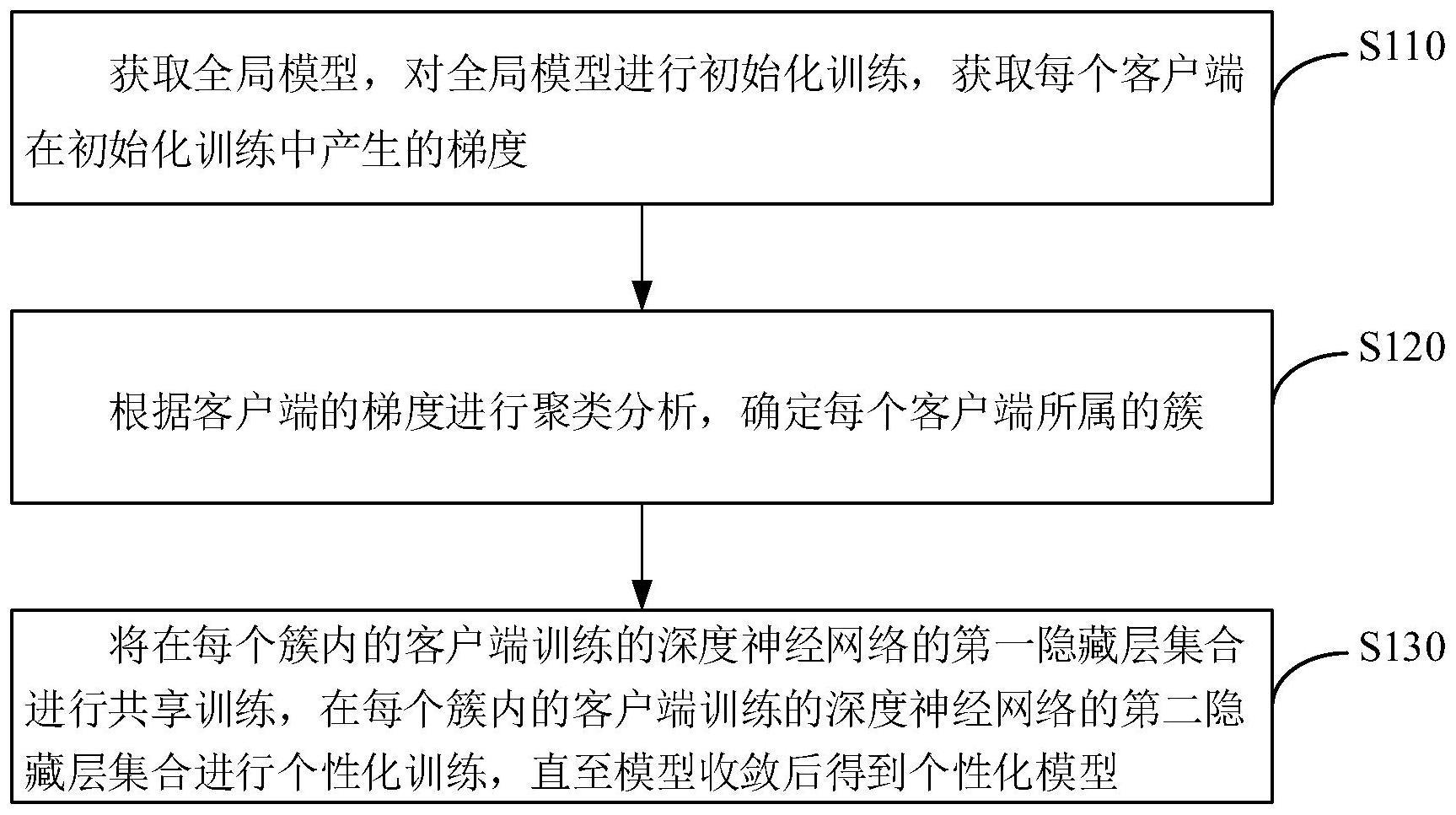
3、获取全局模型,对所述全局模型进行初始化训练,获取每个客户端在所述初始化训练中产生的梯度;
4、根据所述客户端的梯度进行聚类分析,确定每个所述客户端所属的簇;
5、将在每个簇内的客户端训练的深度神经网络的第一隐藏层集合进行共享训练,在每个簇内的客户端训练的深度神经网络的第二隐藏层集合进行个性化训练,直至本地模型收敛后得到个性化模型。
6、在本发明的一种实施例中,所述获取每个客户端在所述初始化训练中产生的梯度,具体包括:将所述全局模型下发至各个客户端,形成对应每个客户端的本地模型;对所述本地模型进行训练,确定每个所述客户端对应的本地模型的损失函数,所述损失函数包括所述本地模型的目标参数;通过随机梯度下降算法不断对所述目标参数进行n次迭代,直到确定所述目标参数使所述损失函数最小化;获取对应每个所述客户端的梯度。
7、在本发明的一种实施例中,所述根据所述客户端的梯度进行聚类分析,确定每个所述客户端所属的簇,具体包括:根据所述客户端的数据集和所述客户端对应的梯度确定加权客户端;初始化多个球簇的质心和半径;将每个所述加权客户端划分到离它最近的质心所在的球簇中;根据所述半径和任意所述球簇之间的质心距离确定任意两个球簇之间的邻域关系;根据所述邻域关系和所述加权客户端到所属球簇及其邻域球簇质心的距离,移动球簇中的加权客户端到其邻域球簇中;根据所述加权客户端到所属球簇及其邻域球簇质心的距离,不断将每个所述球簇中的加权客户端进行迭代,直到每个球簇中拥有的加权客户端不变。
8、在本发明的一种实施例中,根据所述客户端的梯度进行聚类分析,还包括:确定所有球簇半径的平均值和球簇分裂的增量步长;比较每个球簇半径与所述平均值的大小;将所述球簇半径大于所述平均值的球簇进行分裂;确定分裂的球簇数量大于等于所述增量步长时,停止分裂。
9、在本发明的一种实施例中,根据所述加权客户端到所属球簇及其邻域球簇质心的距离,不断将每个所述球簇中的加权客户端进行迭代,具体包括:确定球簇的稳定域和活动域;若确定所述加权客户端在所述稳定域中,则在当前迭代中不移动所述加权客户端到所述球簇的其他邻域球簇中;将球簇的所述活动域划分为多个环形区域,确定所述加权客户端所属的环形区域;根据所述加权客户端所属的环形区域和所述加权客户端到所属球簇及其邻域球簇质心的距离,移动所述加权客户端到对应的邻域球簇或其所属球簇本身。
10、在本发明的一种实施例中,根据所述半径和任意所述球簇之间的质心距离确定任意两个球簇之间的邻域关系,具体包括:确定第一球簇和第二球簇的质心差,确定所述质心差的范数;若所述质心差的范数的一半小于所述第一球簇的半径,则确定第二球簇为第一球簇的邻域球簇。
11、在本发明的一种实施例中,所述将在每个簇内的客户端训练的深度神经网络的第一隐藏层集合进行共享训练,在每个簇内的客户端训练的深度神经网络的第二隐藏层集合进行个性化训练,直至本地模型收敛后得到个性化模型,具体包括:所述客户端所属的簇为球簇;确定所述球簇内的客户端共享的第一隐藏层集合,将所述共享的隐藏层训练作为全局模型训练任务;确定球簇内的客户端高于所述第一隐藏层集合的第二隐藏层集合,将给每个客户端的第二隐藏层集合训练作为个性化模型训练任务;确定每个客户端在执行所述全局模型训练任务时的第一目标函数;根据所述第一目标函数确定每个客户端在执行所述个性化模型训练任务时的第二目标函数。
12、一种基于客户端聚类的个性化联邦学习装置,包括:
13、梯度获取模块,用于获取全局模型,对所述全局模型进行初始化训练,获取每个客户端在所述初始化训练中产生的梯度;
14、聚类分析模块,用于根据所述客户端的梯度进行聚类分析,确定每个所述客户端所属的簇;
15、共享训练模块,用于将在每个簇内的客户端训练的深度神经网络的第一隐藏层集合进行共享训练,在每个簇内的客户端训练的深度神经网络的第二隐藏层集合进行个性化训练,直至本地模型收敛后得到个性化模型。
16、一种基于客户端聚类的个性化联邦学习设备,包括:
17、至少一个处理器;以及,
18、与所述至少一个处理器通过总线通信连接的存储器;其中,
19、所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被执行,以实现:
20、获取全局模型,对所述全局模型进行初始化训练,获取每个客户端在所述初始化训练中产生的梯度;
21、根据所述客户端的梯度进行聚类分析,确定每个所述客户端所属的簇;
22、将在每个簇内的客户端训练的深度神经网络的第一隐藏层集合进行共享训练,在每个簇内的客户端训练的深度神经网络的第二隐藏层集合进行个性化训练,直至本地模型收敛后得到个性化模型。
23、一种非易失性存储介质,存储有计算机可执行指令,所述计算机可执行指令由处理器执行,以实现下述步骤:
24、获取全局模型,对所述全局模型进行初始化训练,获取每个客户端在所述初始化训练中产生的梯度;
25、根据所述客户端的梯度进行聚类分析,确定每个所述客户端所属的簇;
26、将在每个簇内的客户端训练的深度神经网络的第一隐藏层集合进行共享训练,在每个簇内的客户端训练的深度神经网络的第二隐藏层集合进行个性化训练,直至本地模型收敛后得到个性化模型。
27、本发明提供了一种基于客户端聚类的个性化联邦学习方法、装置及设备,至少包括以下有益效果:考虑到多任务之间的相似性,通过基于多球分裂的改进bkm算法,并根据客户端在一定全局训练次数后的梯度表现进行分簇。然后,簇内具有相似分布的客户端采用基于软参数共享的方法进行多任务训练,直至每个客户端都获得个性化模型,不仅能够适用于客户端数量较大的场景,也能够降低算法复杂度,降低资源开销,减少计算时长。通过低复杂度的球簇质心分裂,提高了模型收敛效率和精度。本发明相比于上述专利能提高模型准确率15.6%到22.9%,且具有良好的训练速度和收敛性能。
- 还没有人留言评论。精彩留言会获得点赞!