大幅图像小目标检测下的后处理方法、设备及系统
本发明涉及计算机,尤其涉及一种大幅图像小目标检测下的后处理方法、设备及系统。
背景技术:
1、目标检测也叫目标提取,是一种基于目标几何和统计特征的图像分割。目标检测不仅要判断图片中物品的分类,还要在图片中标记出它的位置并用边框把物品圈起来。目标将目标分割和识别合二为一,其准确性和实时性是人工智能系统的一项重要能力。
2、目标检测的感受野尺寸越大,其能接触到的原始图像的范围就越大,所感受到的特征也趋于全局化。而感受野的尺寸越小,其所包含的特征也趋于局部和细节。遥感等大幅面图像中目标相对尺寸较小,感受野尺寸过大会丢失局部特征和细节,导致检测效果急速下降。减少感受野尺寸会显著提高目标检测效果,但是候选框数量则会急剧增长,形成严重的计算负载。
3、神经网络处理器是一种集成了大规模矩阵神经计算的专用处理芯片,具有成本低、功耗低、算力大等特点,特别擅长执行神经网络推理计算。而神经网络推理的后处理计算时序依赖强、空间并行程度低,使用神经网络处理器计算耗时较长、功耗较高。例如,atlas200 dk是一种用来进行深度学习模型推理的嵌入式设备,常用于深度学习模型在实际应用中的落地,例如被用于进行目标检测。atlas200 dk推理深度学习模型的主要流程为:预处理、推理、数据解码以及后处理(见图1),操作为顺序执行,上一步执行完毕后才可以执行下一步。其中推理流程会在atlas200 dk的推理硬件单元上执行,因为有硬件优化和加持,所以推理阶段的速度是比较快的,平均速度为几十毫秒左右。预处理主要包括图像缩放等操作,数据解码主要从推理后的特征图得到坐标和置信度等信息,后处理主要为非极大值抑制操作。而预处理、数据解码以及后处理等操作均在在atlas200 dk的arm cpucortex a53上执行,没有任何硬件优化,速度较慢,尤其是后处理操作,对于需要检测小目标的大幅图像,候选框的数量较多,因此后处理成为了增加整个推理系统延迟的根本因素。经过测算,对于1920x1080的图像,后处理的操作耗时约为200ms,进而导致在图1推理流程下,整体的推理速度约为5fps,那对于尺寸更大的图像,例如遥感图像,如果在atlas200 dk进行小目标检测,那后处理延迟会更大,推理速度会进一步降低。
技术实现思路
1、为了解决现有技术存在的问题,本发明提供了一种大幅图像小目标检测下的后处理方法、设备及系统。
2、本发明是这样实现的:
3、一种大幅图像小目标检测下的后处理方法,其包括:
4、通过并行的方式循环执行如下步骤,直至遍历所有的特征图数组:
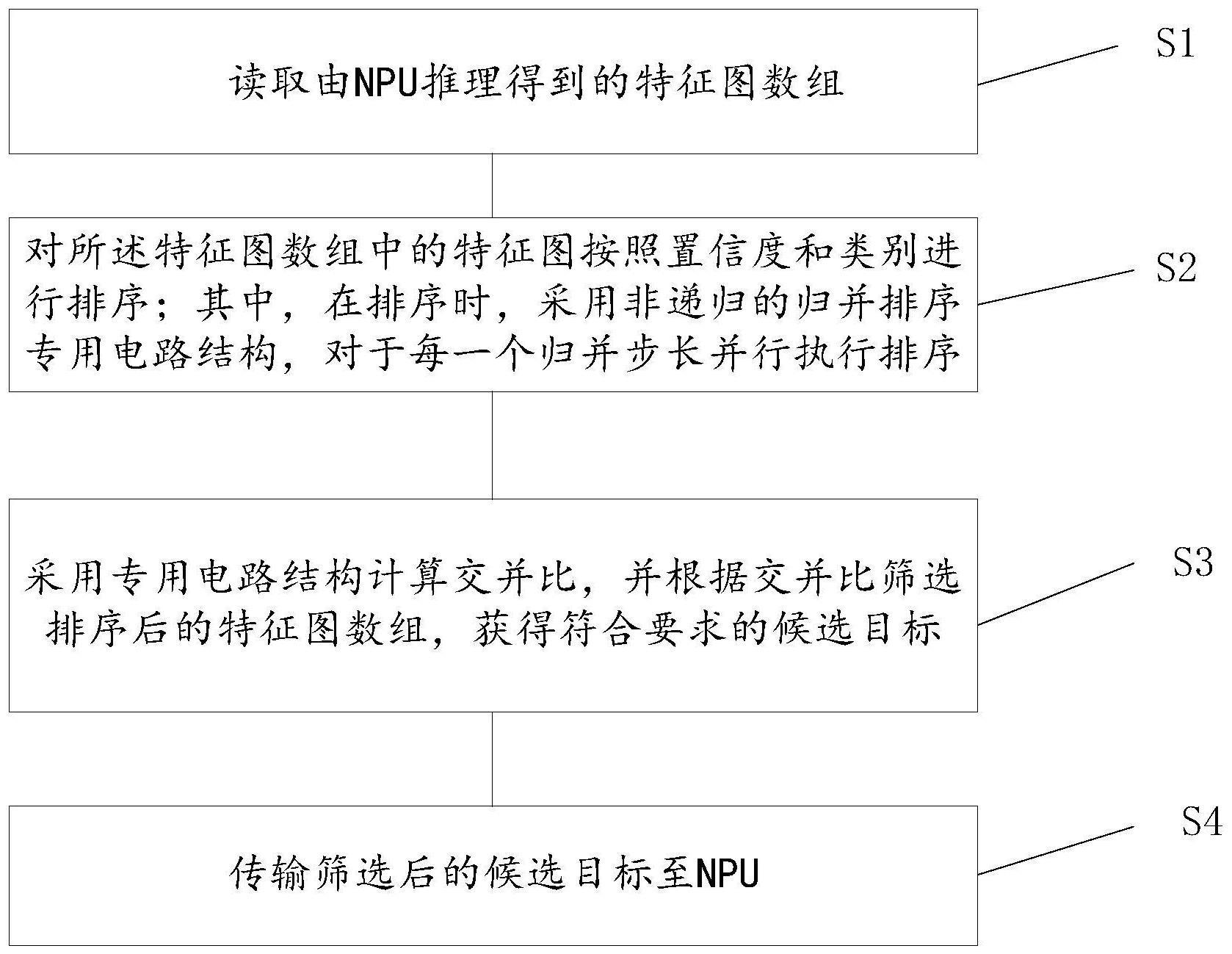
5、s1,读取由npu推理得到的特征图数组;
6、s2,对所述特征图数组中的特征图按照置信度和类别进行排序;其中,在排序时,采用非递归的归并排序专用电路结构,对于每一个归并步长并行执行排序;
7、s3,采用专用电路结构计算交并比,并根据交并比筛选排序后的特征图数组,获得符合要求的候选目标;
8、s4,传输筛选后的候选目标至npu。
9、优选地,s2具体为:
10、由专用电路结构将内存中的特征图批量读入多个bram中,使用多组并行排序单元对bram中的数据进行归并排序后再写回内存;其中,对于特征图数组中的任意两个元素a和b,首先按照类别进行排序,如果元素a的类别优先级大于元素b,那么a排序在前,否则b排序在前;如果元素a和b的类别一样,则按照他们的置信度进行排序,其中,置信度大的排列在置信度小的前面。
11、优选地,s3具体包括:
12、s31,初始化首指针和尾指针寄存器指向排序后的特征图数组的内存首地址;
13、s32,判断尾指针是否小于所述特征图数组的长度;若是,则执行s33,若否,则执行s35;
14、s33,初始化指针i寄存器指向所述特征图数组内存首地址,判断指针i是否小于所述特征图数组的长度;若指针i大于等于特征图数组的长度,则流程结束,否则执行s34;
15、s34,判断指针i指向的特征图的标志位是否为true,如果为true,首先将指针j指向结果数组内存首地址,同时将指针i指向的特征图赋值给指针j指向的位置,然后指针i和指针j同时自增1,并返回s33;如果标志位为false,直接返回s33;
16、s35,判断尾指针小于特征图数组的长度且首指针指向的特征图的类别和尾指针指向的特征图的类别相同两个条件是否同时满足;若满足,则执行s36,否则执行s37;
17、s36,自增尾指针并返回s35;
18、s37,自减尾指针,然后判断首指针是否小于尾指针;若否,则将尾指针的值加1后赋值给首指针,再自增尾指针后返回s32,若是,则执行s38;
19、s38,判断首指针指向的特征图的标志位是否为false;若是,则自增首指针后,执行s37;若否,则定义指针k,并初始化为首指针的值加1,执行s39;
20、s39,判断指针k是否小于等于尾指针;若否,在自增首指针后,执行s37;若是,则执行s310;
21、s310,判断指针k指向的特征图的标志位是否为true;若是,则自增指针k后,返回s39;若否,则在根据指针k指向的数据和首指针指向的特征图计算交并比并执行s311;
22、s311,比较交并比和预设阈值的大小,如果交并比大于阈值,那么将指针k指向特征图的标志位设置为false后,自增指针k,返回s38;否则自增指针k后,返回s38。
23、优选地,对于特征图数组中的元素,其对应有两组坐标(x1,y1),(x2,y2),分别指示元素的左上角和右下角;
24、则对于元素a和b,交并比的计算步骤具体为:
25、使用组合逻辑电路计算交集矩形宽度width和高度height;
26、其中交集矩形的宽度按照公式width=min(a.x2-b.x2)-max(a.x1-b.x1)计算;交集矩形的高度按照公式height=min(a.y2-b.y2)-max(a.y1-b.y1)计算;
27、使用硬件乘法器计算交集矩形面积s1,s1按照公式s1=height*width计算;
28、使用硬件乘累加器计算并集矩形面积s2,s2按照公式s2=(a.x2-a.x1)*(a.y2-a.y1)+(b.x2-b.x1)*(b.y2-b.y1)-s1计算;其中,m.n表示元素m的n坐标的值;
29、使用硬件除法器根据交集矩形面积s1和并集矩形面积s2计算交并比iou=s1/s2。
30、本发明实施例还提供了一种大幅图像小目标检测下的后处理设备,其包括fpga;
31、所述fpga包括nms模块,所述nms模块用于实现如上述的大幅图像小目标检测下的后处理方法。
32、优选地,所述fpga还包括:
33、硬核处理器模块、processor system reset模块、axi bram controller模块、axiinterconnect模块、block memory generator模块;其中:
34、硬核处理器模块的工作时钟引脚连接processor system reset模块的低速同步时钟引脚;
35、硬核处理器模块的工作时钟引脚连接axi interconnect模块的各个主从接口工作时钟引脚;
36、硬核处理器模块的工作时钟引脚连接nms模块的工作时钟引脚;
37、硬核处理器模块的工作时钟引脚连接axi bram controller模块的从接口工作时钟引脚;
38、硬核处理器模块的fpga工作时钟引脚连接axi interconnect模块的各个主从接口工作时钟引脚;
39、硬核处理器模块的fpga工作时钟引脚连接nms模块的工作时钟引脚;
40、硬核处理器模块的fpga复位引脚连接processor system reset模块的外部复位输入引脚;
41、硬核处理器模块的axi快速主接口引脚连接axi interconnect模块的axi从接口引脚;
42、硬核处理器模块的axi慢速主接口引脚连接axi interconnect模块的axi从接口引脚;
43、processor system reset模块的外部设备复位引脚连接axi interconnect模块的主从接口复位引脚;
44、processor system reset模块的外部设备复位引脚连接nms模块的复位引脚;
45、processor system reset模块的外部设备复位引脚连接axi bram controller模块的从接口复位引脚;
46、processor system reset模块的axi从接口引脚连接nms模块的axi主接口引脚;
47、processor system reset模块的axi主接口引脚连接axi bram controller模块的axi从接口引脚;
48、processor system reset模块的axi主接口引脚连接nms模块的axi从接口控制引脚;
49、axi bram controller模块的写引脚连接block memory generator模块的读引脚。
50、优选地,硬核处理器模块,用于接收npu发送的神经网络推理的特征图后,通过axi快速主接口引脚将特征图发送到axi bram controller模块;
51、axi bram controller模块,用于通过axi从接口引脚接收到特征图后,通过写引脚写特征图到block memory generator模块;
52、多个block memory generator模块,用于缓存特征图;
53、所述nms模块,用于通过axi主接口引脚跟axi interconnect模块通信,而axiinterconnect模块通过axi主接口引脚与axi bram controller模块通信,获取到blockmemory generator模块中的特征图,nms模块获取到特征图后,执行如上述的大幅图像小目标检测下的后处理加速方法,执行完毕后,对候选目标进行拷贝;nms模块,还用于通过axi主接口引脚与axi interconnect模块的axi从接口引脚通信,axi interconnect模块通过axi从接口引脚和硬核处理器模块的axi慢速接口引脚通信,硬核处理器模块通过axi慢速接口引脚将候选目标从nms模块拷贝后传输给npu。
54、本发明实施例还提供了一种大幅图像小目标检测下的后处理系统,其包括npu以及如上述的大幅图像小目标检测下的后处理设备;其中:
55、在npu端,实现了对输入的原始图像数据的预处理、推理生成特征图数据,并发送给fpga;
56、在fpga端,通过并行的方式实现了对推理后的特征图数组进行排序、筛选后传输候选目标至npu;
57、在npu端,输出筛选后的候选目标。
58、优选地,在npu端,包括:
59、s201,读入原始图像数据后,执行s202;
60、s202,为每一个读取到的原始图像数据标上序号i1,同时将原始图像数据放入缓冲池当中,执行s203;
61、s203,对原始图像数据进行预处理,预处理结束后,用预处理后的图像数据在硬件推理单元上执行推理工作,在推理结束后,进行数据解码得到推理后的特征图,执行s204;
62、s204,对特征图进行分片处理,将每一个特征图数据分片标上序号j,然后利用udp协议将特征图数据分片发送给fpga端;
63、在fpga端:
64、s205,初始化接收标志位flag为true;
65、s206,接收推理后的特征图数据分片j;
66、s207,判断推理后的特征图数据分片序号j是否等于0,如果等于0,那么设置接收标志位flag为true,执行s208,否则直接执行s208;
67、s208,判断序号j是否是连续,如果不连续,将接收标志位flag设置为false,执行s209,否则直接执行s209;
68、s209,判断接收标志位flag是否为true,如果不为true,丢弃当前推理后的特征图数据分片j,执行s206,否则直接执行s206;
69、s210,判断当前推理后的特征图数据分片是否是最后一片,如果不是最后一片,那么执行s206,否则执行s211;
70、s211,进行特征图数据分片的重组,得到原始序号i1和每一个推理后的特征图数据分片的序号j,根据序号j进行重组,将重组后的特征图放入缓冲池中,执行s212;
71、s212,判断缓冲池是否为空,如果不为空,那么执行s213,否则执行s212;
72、s213,从缓冲池中读取特征图,通过hls中编译得到的数据交互api将特征图发送给nms模块,生成候选目标后,将原始序号i1作为i2,放入报文头中,根据候选目标重组数据包,利用udp协议传输数据包给npu;
73、在npu端:
74、s214,接收到候选目标后,解析候选目标,得到坐标信息和序号i2,执行s215;
75、s215,将序号i2和本地缓冲当中的原始图像数据的序号i1进行比较;如果序号i1等于i2,说明匹配,直接从缓冲池中取出当前的原始图像数据,并将坐标信息与原始图像数据结合后一起输出,执行s201;如果i1>i2,说明fpga端在向npu端传输候选目标时,发生数据的丢失,那么丢弃该候选目标后,执行s214;如果i1<i2,说明npu在向fpga端传输推理后的特征图时,发生了数据的丢失,那么直接从缓冲池中丢弃该原始图像数据,再次执行s215。
76、在本实施例中,采用多级流水线方法展开,从而实现特征图中候选框排序算法的并行展开,从而可以优化循环的时序关系,尽量减少循环耗时,提高了后处理速度。
- 还没有人留言评论。精彩留言会获得点赞!