基于层次化上下文引导的多目标跟踪方法
本发明涉及计算机视觉,尤其涉及一种基于层次化上下文引导的多目标跟踪方法。
背景技术:
1、随着深度学习的发展,卷积神经网络应用在越来越多的场景中,而多目标跟踪由于其在视频监控、人机交互和虚拟现实中的广泛应用,在计算机视觉领域受到越来越多的重识。多目标跟踪旨在定位给定视频序列中的多个目标对象,为不同的对象分配不同的身份id并记录每个id在视频中的轨迹。目前,随着基于卷积神经网络的目标检测技术不断发展,基于检测的跟踪算法已成为多目标跟踪的主流方向。基于检测的跟踪算法首先需要在每个视频帧上执行目标检测获取每帧的检测结果,然后根据检测结果进行数据关联以创建每个对象在视频中的轨迹。
2、一阶段多目标跟踪方法的核心思想是在一个深度学习网络中同时进行目标检测和跟踪,通过共享大部分计算量来减少推理时间。最近,一种同时兼容跟踪效率和精度的一阶段多目标跟踪方法被提出,它是一个anchor-free的方法,使用resnet-34结构作为骨干网络,使其能够很好的兼容精度和速度,通在骨干网络上添加deep layer aggregation(dla)结构来实现不同尺度的检测,这种网络设计可以根据目标的尺度和姿势动态地适应感受野,同时有助于缓解对齐问题。
3、该方法的框架如图2所示,主要由用于提取特征的特征提取网络,检测部分和嵌入id的重识别3个部分。其中,检测分支分别用热图去预测物体中心的位置、获取目标的中心偏移量和估计目标边界框的高度和宽度,重识别分支的目的是产生能够区分物体的特征。检测部分和重识别部分共享特征提取网络提取到的特征,并同时进行训练学习。这些一次性方法虽然节省了一些计算量,但在跟踪场景复杂的情况下性能仍然有限。
技术实现思路
1、本发明的实施例提供了一种基于层次化上下文引导的多目标跟踪方法,用于解决现有技术中存在的技术问题。
2、为了实现上述目的,本发明采取了如下技术方案。
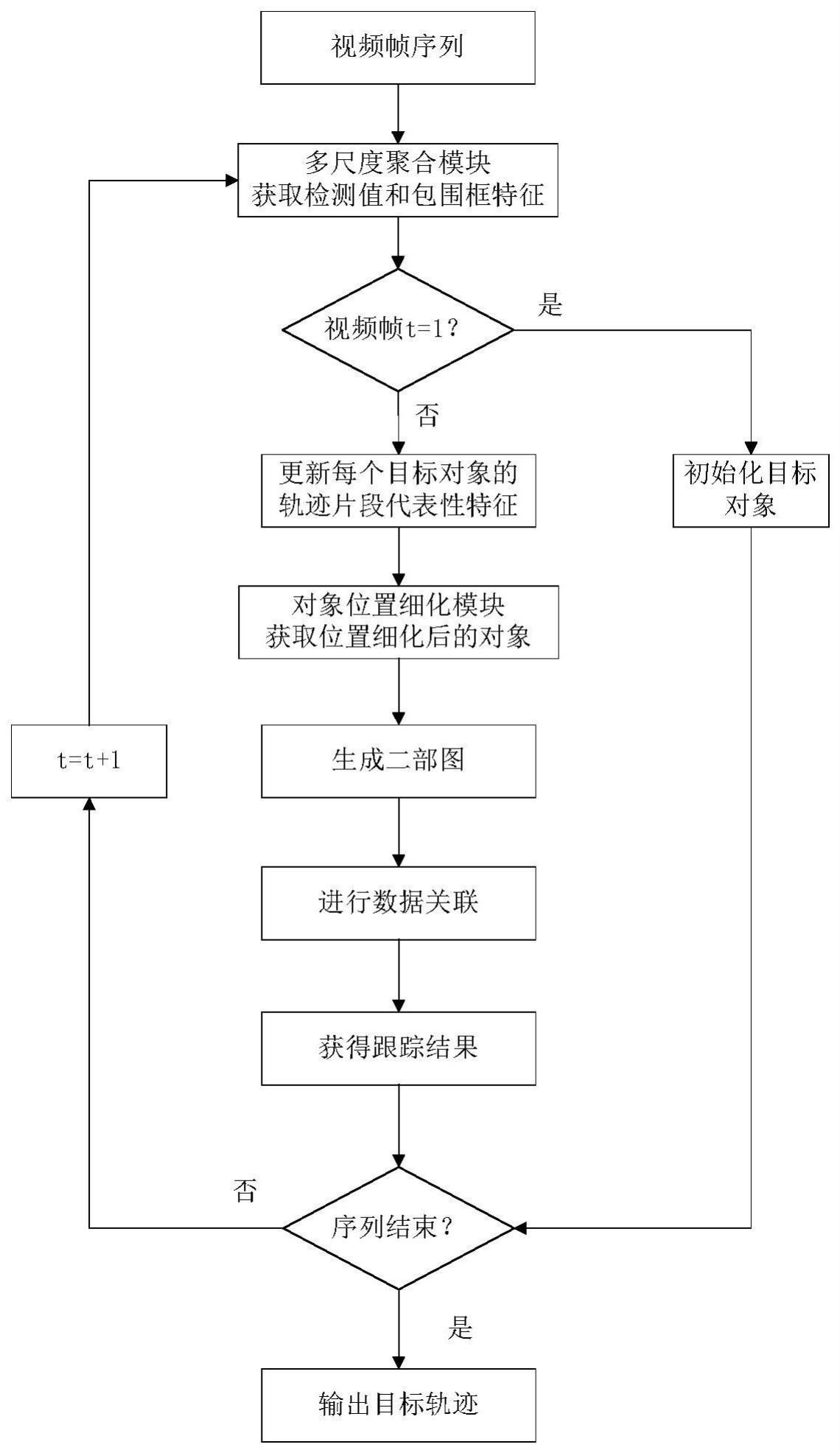
3、基于层次化上下文引导的多目标跟踪方法,包括:
4、s1基于原始视频序列,令t表示原始视频序列的第t帧;
5、s2当t=1时,通过上下文引导的多尺度聚合模块处理原始视频序列,获得目标对象在当前帧的检测值dt、检测值对应的包围框特征和当前视频帧的特征并使用检测值dt初始化目标对象ot,使用检测值对应的包围框特征初始化对象的包围框特征使用目标对象的包围框特征初始化对象轨迹片段的代表性特征当t>1时,通过上下文引导的多尺度聚合模块处理原始视频序列的第t帧和第t-1帧,挖掘获得当前帧的具有时空上下文信息的视频帧特征并根据上下文信息的引导获取第t帧图像中的检测值dt,检测值对应的包围框特征和第t帧图像的特征
6、s3通过上下文引导的对象位置细化模块,通过目标对象在第t-1帧时的包围框特征初始化该目标对象在第t-1帧时轨迹片段的代表性特征获得更新后的该目标对象在第t帧时的轨迹片段的代表性特征
7、s4基于步骤s3获得的更新后的轨迹片段的代表性特征和步骤s2得到的具有时空上下文信息的视频帧特征通过上下文引导的对象位置细化模块进行处理,获得位置细化后目标对象rt;
8、s5基于步骤s2得到的第t帧图像中的检测值dt、检测值对应的包围框特征步骤s3获得的更新后的目标对象在第t帧时的轨迹片段的代表性特征和步骤s4得到的位置细化后的目标对象rt,构建二部图;
9、s6基于二部图通过匈牙利算法进行匹配;
10、s7基于步骤s6的匹配结果获得目标的跟踪轨迹结果,包括:将检测值dt的位置坐标作为与该检测值dt匹配的目标对象在当前帧的位置,与该目标对象对应的包围框特征作为该目标对象在当前帧的特征;
11、s8判断原始视频序列的处理是否结束,若是,则输出所有的目标的跟踪轨迹结果,否则,执行针对原始视频序列下一帧的处理操作。
12、优选地,上下文引导的多尺度聚合模块包括全局时序上下文挖掘子模块和基于补丁的空间上下文挖掘子模块;
13、全局时序上下文学习子模块用于处理不同帧之间的时间上下文关系,通过将上一帧的底层特征与当前帧的底层特征进行串联生成连接特征,然后对连接特征进行视频帧全局的时间上下文学习,计算当前帧特征的每个像素与前一帧所有像素之间的关系,并将计算结果输送到局部空间上下文学习子模块;
14、局部空间上下文学习子模块用于:基于全局时序上下文学习子模块的计算结果,利用resnet34进行渐进式编码获得多尺度特征金字塔,对多尺度特征金字塔每一层的特征进行交叉分割,生成多个局部特征,然后对每个局部特征独立地进行空间上下文学习以获得特定范围的空间上下文关系,拼接同一层特征中地所有具有空间上下文信息地局部特征以得到特征金字塔中每一层完整的具有空间上下文的特征图,最后使用深层聚合方法对多尺度特征金字塔每一层的特征图进行聚合操作,获得多尺度聚合的当前视频的特征基于多尺度聚合特征定位感兴趣的区域,获得检测值dt和检测值的包围框特征
15、优选地,局部空间上下文学习子模块通过式
16、
17、
18、计算获得多尺度聚合的当前视频的特征式中,y为模块学到的具有上下文信息的特征,x为输入特征,在计算时间上下文关系时,x为当前帧和前一帧底层特征串联后的结果,在计算空间上下文时,x为多尺度金字塔中每一层进行交叉分割后的局部特征,w1,w2,w3,w4表示4个卷积层,softmax表示激活函数,maxpool为最大池化操作,是一个系数,具体是通过自注意力机制计算获得的特征关系;
19、局部空间上下文学习子模块将计算获得的多尺度聚合的当前视频的特征输送到检测分支和包围框特征提取分支中,得到当前帧的检测值dt、检测值对应的包围框特征
20、优选地,步骤s3包括:通过式
21、
22、计算获得更新后的该目标对象在第t帧时的轨迹片段的代表性特征式中,j表示第j个目标对象,表示该目标对象在第t-1帧时的包围框特征,代表该目标对象在第t-1帧时轨迹片段的代表性特征。
23、优选地,步骤s4包括:
24、s41将具有时空上下文信息的当前视频帧帧特征和上一视频帧帧特征输入到编码器中进行编码;
25、s42通过式
26、
27、将步骤s3获得的与子步骤s41获得的编码结果输入到解码器中进行对象探查,计算获得细化对象rt;式中,transd和transe是transformer结构的编码器和解码器,f(.)是由卷积层组成的用于预测目标对象中心点位置,偏移量和包围框的函数。
28、由上述本发明的实施例提供的技术方案可以看出,本发明提供一种基于层次化上下文引导的多目标跟踪方法,并提出了一种新的分层上下文引导网络,该网络通过分层次自下而上的全局处理、局部处理和对象包围框处理来执行检测、包围框特征提取和对象位置细化。具体而言,该网络的多尺度聚合模块分别以全局和局部的方式学习时间和空间上下文特征,引导多尺度特征聚合,从而定位感兴趣的区域,提取丰富的包围框特征。这样,每个检测值的包围框特征除了语义信息外,还拥有上下文关系,减少了不完整或不清楚的对象的重要信息的丢失。最后,基于学习到的上下文特征,设计了一个上下文引导的对象位置细化模块,通过传播对象在历史帧中的包围框特征来学习该对象轨迹片段的代表性特征,并利用代表性特征和多尺度聚合模块的上下文特征在每一帧中生成位置细化后的对象,这种方式可以缓解对象和检测之间的错误匹配。以此来提高多目标跟踪任务模型在复杂跟踪场景中的性能。
29、本发明附加的方面和优点将在下面的描述中部分给出,这些将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!