一种基于多重心时空注意图卷积网络的骨架动作识别方法
本发明属于计算机视觉和深度学习领域,具体涉及一种基于多重心时空注意图卷积网络的骨架动作识别方法。
背景技术:
1、行为识别技术广泛应用在智能监控、虚拟现实、人机交互、公共安全、医疗健康等众多领域,具有十分广阔的应用前景,为计算机视觉等领域的重要研究课题。人体行为识别的目的简单来说就是根据输入视频或数据来自动判断有什么人在什么样的场景中做了怎样的动作。识别系统的一般处理流程是:通过分析处理输入数据,提取数据特征,将聚合的特征作为一种特定模式,根据这种模式来对应某类人体行为活动。对人体行为的识别不同于姿态估计,单纯一张图片并不能判断出人体活动的类型,因为行为是个持续性的动作。例如,一张“抬着手”的图片,并不知道图片中的人下一步是要将手放下还是继续抬起,必须通过追踪数据中长期的动态信息才能感知到不同行为的运动特征。
2、骨架数据是包含多个人体骨骼关节的二维或三维坐标位置的时间序列,可以使用姿态估计方法从视频图像中提取或者利用传感器设备直接采集。相比于传统的rgb视频识别方法,基于骨架数据的动作识别能有效地减少识别过程中由于光照变化、环境背景、遮挡等干扰因素的影响,对动态环境和复杂背景具有较强的适应性。
3、目前,将人体骨架数据拓扑为时空图,并利用图卷积网络(gcns)进行处理被证实有着良好的识别效果。然而,目前基于gcn的主流模型还存在如下不足:(1)特征提取能力有限。一般来说,特征明显或者结合数量越多的关节点数据,行为特征信息也就更加复杂,越利于行为预测,通常采用更大的卷积核或加大网络深度的方法,但这些都会带来更大的计算量;(2)多流融合特定行为模式的方法简单。目前,经典的多流框架模型通常直接将各流的softmax分数相加获得最终的预测结果,但实际上各个流的预测效果是有明显差异的,单纯的分数相加难以获得精确的预测结果,并且参数计算量较大。(3)生成具有语义意义的边的邻接矩阵在此任务中尤为重要,传统的空间拓扑图受物理连接性影响,边的提取仍是一个具有挑战性的问题。
技术实现思路
1、本发明的目的在于针对上述问题,提出一种基于多重心时空注意图卷积网络的骨架动作识别方法,可更充分地提取不同重心下的拓扑图信息,并在不增加计算量的情况下,结合数量更多、特征更明显的关节数据以实现人体行为预测,有助于提高人体行为的预测精确度。
2、为实现上述目的,本发明所采取的技术方案为:
3、本发明提出的一种基于多重心时空注意图卷积网络的骨架动作识别方法,包括如下步骤:
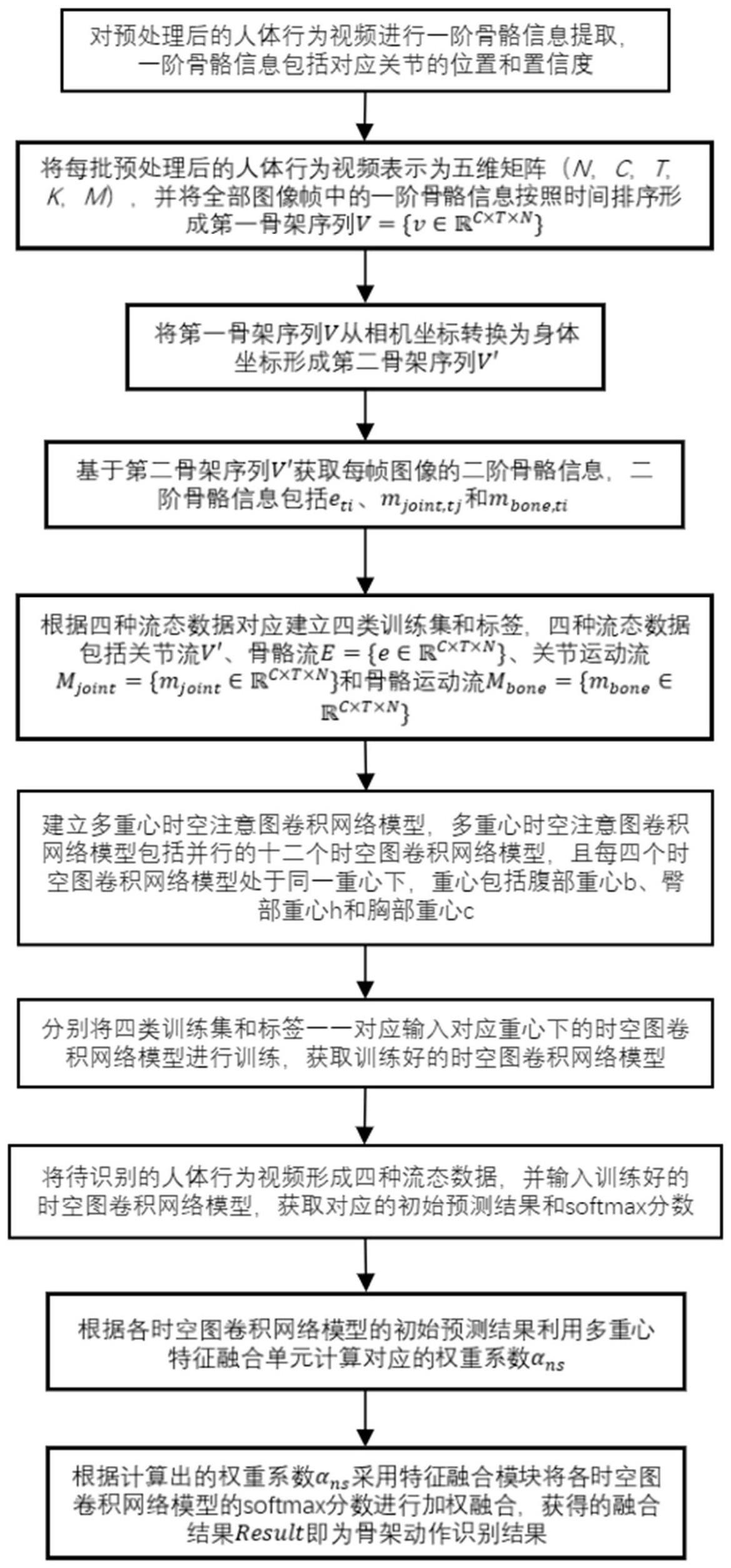
4、s1、对预处理后的人体行为视频进行一阶骨骼信息提取,一阶骨骼信息包括对应关节的位置和置信度;
5、s2、将每批预处理后的人体行为视频表示为五维矩阵(n,c,t,k,m),并将全部图像帧中的一阶骨骼信息按照时间排序形成第一骨架序列其中,n代表每批人体行为视频的数量,c代表关节的特征维度,t代表每个人体行为视频中图像帧的数量,k代表人体关节数量,m代表每帧图像中的人数,v为关节向量;
6、s3、将第一骨架序列v从相机坐标转换为身体坐标形成第二骨架序列v′;
7、s4、基于第二骨架序列v′获取每帧图像的二阶骨骼信息,二阶骨骼信息包括eti、mjoint,tj和mbone,ti,公式如下:
8、eti=vti′-vti
9、mjoint,tj=v(t+1)j-vtj
10、mbone,ti=e(t+1)i-eti
11、其中,eti为第t帧第i个骨骼的骨骼向量,vti为第t帧第i个骨骼上靠近骨架重心的源关节坐标,vti′为第t帧第i个骨骼上远离骨架重心的目标关节坐标,mjoint,tj为第j个关节在第t+1帧和第t帧的向量差,mbone,ti为第i个骨骼在第t+1帧和第t帧的向量差,vtj为第t帧第j个关节的坐标,v(t+1)j为第t+1帧第j个关节的坐标,e(t+1)i为第t+1帧第i个骨骼的骨骼向量;
12、s5、根据四种流态数据对应建立四类训练集和标签,四种流态数据包括关节流v′、骨骼流关节运动流和骨骼运动流其中,e为每个骨骼的骨骼向量,mjoint为每个关节在相邻帧图像的向量差,mbone为每个骨骼在相邻帧图像的向量差;
13、s6、建立多重心时空注意图卷积网络模型,多重心时空注意图卷积网络模型包括并行的十二个时空图卷积网络模型,且每四个时空图卷积网络模型处于同一重心下,重心包括腹部重心b、臀部重心h和胸部重心c;
14、s7、分别将四类训练集和标签一一对应输入对应重心下的时空图卷积网络模型进行训练,获取训练好的时空图卷积网络模型;
15、s8、将待识别的人体行为视频形成四种流态数据,并输入训练好的时空图卷积网络模型,获取对应的初始预测结果和softmax分数;
16、s9、根据各时空图卷积网络模型的初始预测结果利用多重心特征融合单元计算对应的权重系数αns,公式如下:
17、
18、
19、其中,表示每流初始预测结果组成的数组,每流初始预测结果的取值范围为0~1,acu[ns]表示第n个重心第s流识别准确度,acu[nm]表示第n个重心第m流识别准确度,γ为非零常数;
20、s10、根据计算出的权重系数αns采用特征融合模块将各时空图卷积网络模型的softmax分数进行加权融合,获得的融合结果result即为骨架动作识别结果,公式如下:
21、
22、其中,rns为第n个重心第s流的softmax分数。
23、优选地,时空图卷积网络模型包括依次连接的第一bn层、多尺度图卷积模块、全局平均池化层和softmax分类器,多尺度图卷积模块包括输出通道依次为64、64、64、128、128、128、256、256、256的九层特征提取模块。
24、优选地,各层特征提取模块包括第二残差模块、以及依次连接的自适应空间域图卷积单元、第一激活函数、注意力模块、时间域图卷积单元、第二bn层、第二激活函数和第一特征提取单元,第二残差模块的输入端与自适应空间域图卷积单元的输入端连接,输出端与第一特征提取单元连接,第一特征提取单元用于执行相加操作。
25、优选地,自适应空间域图卷积单元,满足如下公式:
26、
27、其中,hin为自适应空间域图卷积单元的输入,hout为自适应空间域图卷积单元的输出,p=0,1,…,pv,pv为根据空间结构划分的邻接矩阵数量,wp为1×1卷积操作的权重函数,bp为k×k大小的邻接矩阵,cp表示每帧图像中关节间是否连接及连接强度的邻接矩阵,β为自适应系数。
28、优选地,时间域图卷积单元包括第二特征提取单元、第二残差模块、第一concat函数和第三特征提取单元,并执行如下操作:
29、将注意力模块的输出特征输入第二特征提取单元获得第一特征,第二特征提取单元包括并行的四个第一分支单元、一个第二分支单元和一个第三分支单元,第一分支单元包括依次连接的第一卷积层和第一膨胀卷积层,第二分支单元包括依次连接的第二卷积层和最大池化层,第三分支单元包括第三卷积层,第一特征为各分支单元的输出特征;
30、将各分支单元的输出特征通过第一concat函数进行聚合,获得第一聚合特征;
31、将注意力模块的输出特征输入第二残差模块获得第二特征,第二残差模块包括第四卷积层;
32、将第一聚合特征和第二特征通过第三特征提取单元进行相加操作,获得第三特征即为时间域图卷积单元的输出特征。
33、优选地,注意力模块包括空间注意力单元、时间注意力单元、通道注意力单元、第二concat函数和第四特征提取单元,并执行如下操作:
34、将自适应空间域图卷积单元的输出特征分别输入空间注意力单元、时间注意力单元和通道注意力单元,对应获得空间注意力图、时间注意力图和通道注意力图;
35、将空间注意力图、时间注意力图和通道注意力图通过第二concat函数进行聚合,获得第二聚合特征;
36、将自适应空间域图卷积单元的输出特征和第二聚合特征通过第四特征提取单元进行相加操作,获得第四特征即为注意力模块的输出特征。
37、优选地,空间注意力单元包括第五卷积层、第五特征提取单元、以及依次连接的第一平均池化层、第一空间卷积层和第三激活函数,第五卷积层和第一平均池化层均与自适应空间域图卷积单元连接,第五卷积层的输出特征和第三激活函数的输出特征通过第五特征提取单元进行相乘操作,获得空间注意力图;
38、时间注意力单元包括第六卷积层、第六特征提取单元、以及依次连接的第二平均池化层、第二空间卷积层和第四激活函数,第六卷积层和第二平均池化层均与自适应空间域图卷积单元连接,第六卷积层的输出特征和第四激活函数的输出特征通过第六特征提取单元进行相乘操作,获得时间注意力图;
39、通道注意力单元包括第七卷积层、第七特征提取单元、以及依次连接的第三平均池化层、第一线性全连接层、第五激活函数、第二线性全连接层和第六激活函数,第七卷积层和第三平均池化层均与自适应空间域图卷积单元连接,第七卷积层的输出特征和第六激活函数的输出特征通过第七特征提取单元进行相乘操作,获得通道注意力图。
40、优选地,预处理为将人体行为视频的分辨率调整为340×256,帧率转换为30fps。
41、优选地,一阶骨骼信息采用人体姿态识别算法提取,人体姿态识别算法为openpose。
42、优选地,第一骨架序列v具有连续的预设帧数的一阶骨骼信息。
43、与现有技术相比,本发明的有益效果为:该方法采用多重心多尺度时空注意图卷积网络模型,将获取的人体行为信息(包括静态信息和运动信息)结合实现动作预测,通过时间域图卷积单元能够灵活有效地捕获人体骨架上的图域关节关系,通过注意力模块确定哪些边和关节在识别中更重要,更好地获取网络不同层的语义信息,并使用残差连接增强模型的稳定性;且通过结合特征更加突出的不同重心的骨架数据建立多重心多流框架,可更充分地提取不同重心下的拓扑图信息,多流之间结果相互补充,同时使用新的加权方式将各流的softmax分数进行加权融合,在不增加计算量的情况下,结合数量更多、特征更明显的关节数据以实现人体行为预测,有效提高人体行为的最终预测精确度。
- 还没有人留言评论。精彩留言会获得点赞!