基于人工智能的测谎方法、装置、电子设备及存储介质与流程
本技术涉及人工智能,尤其涉及一种基于人工智能的测谎方法、装置、电子设备及存储介质。
背景技术:
1、测谎在小额借贷面审、抵押贷款面审等金融风控场景中有着重要的作用,可以协助面审人员进行高效的风险规避操作,同时,在案件审讯、视频面试等其他场景中也起到重要作用。
2、微表情是一种瞬间闪现的面部表情,这种反应在一个情绪唤起之后快速出现而且很难抑制,能揭示人的真实感情和情绪。说谎时人的微表情与正常交谈时是有所不同的,一些微小的表情变化和脸部微妙的肌肉跳动很容易在无意识间暴露真实的想法。
3、目前,通常将视频中的多个图像帧作为分类模型的输入并直接输出测谎结果,然而,这种方式需要采集应用场景中的大量业务数据进行标注以训练分类模型,标注成本较高,且说谎时的人会对自己的行为进行伪装,导致分类模型输出的测谎结果不准确。
技术实现思路
1、鉴于以上内容,有必要提出一种基于人工智能的测谎方法及相关设备,以解决如何降低标注成本的同时提高测谎结果的准确性这一技术问题,其中,相关设备包括基于人工智能的测谎装置、电子设备及存储介质。
2、本技术提供基于人工智能的测谎方法,所述方法包括:
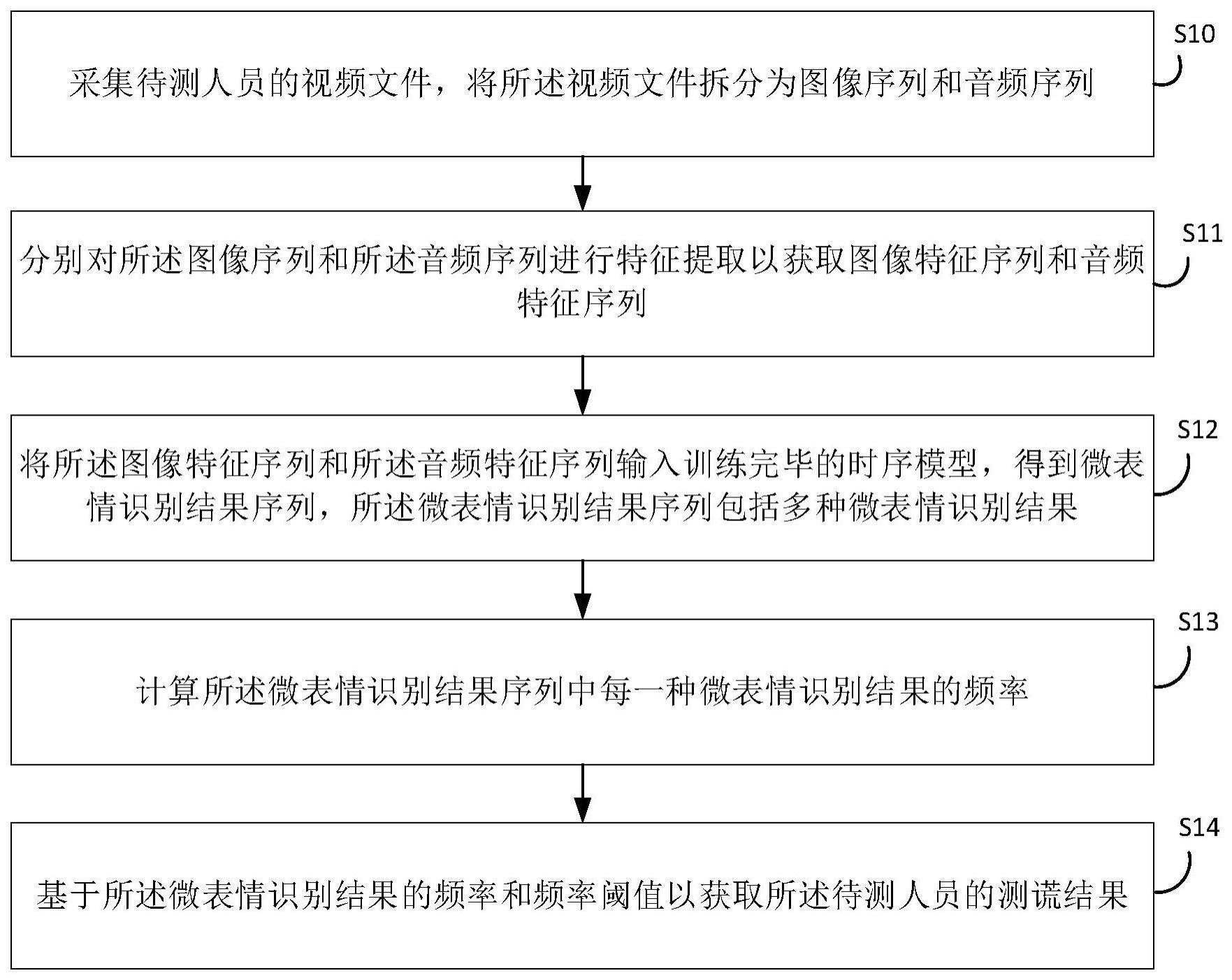
3、采集待测人员的视频文件,将所述视频文件拆分为图像序列和音频序列;
4、分别对所述图像序列和所述音频序列进行特征提取以获取图像特征序列和音频特征序列;
5、将所述图像特征序列和所述音频特征序列输入训练完毕的时序模型,得到微表情识别结果序列,所述微表情识别结果序列包括多种微表情识别结果;
6、计算所述微表情识别结果序列中每一种微表情识别结果的频率;
7、基于所述微表情识别结果的频率和频率阈值以获取所述待测人员的测谎结果。
8、在一些实施例中,所述采集待测人员的视频文件,将所述视频文件拆分为图像序列和音频序列,包括:
9、采集待测人员的视频文件,所述视频文件包括至少两个时间戳;
10、按照所述时间戳的先后顺序提取所述视频文件中每一个时间戳的图像帧以获取图像序列,所述图像帧包括所述待测人员的人脸图像;
11、按照所述时间戳的先后顺序提取所述视频文件中每一个时间戳的音频信号以获取音频序列。
12、在一些实施例中,所述分别对所述图像序列和所述音频序列进行特征提取以获取图像特征序列和音频特征序列包括:
13、依据预设时间长度对所述图像序列进行切分以获取至少两个时间片的图像子序列;
14、基于所述预设时间长度对所述音频序列进行切分以获取至少两个时间片的音频子序列;
15、基于光流法对所述图像子序列进行特征提取以得到每一个时间片的光流特征,并将所有光流特征按照所述时间片的先后顺序进行排列以获取图像特征序列;
16、基于音频特征提取算法对所述音频子序列进行特征提取得到每一个时间片的音频特征,并将所有音频特征按照所述时间片的先后顺序进行排列以获取音频特征序列。
17、在一些实施例中,所述训练完毕的时序模型的输入为所述图像特征序列和所述音频特征序列,输出为微表情识别结果序列;
18、所述时序模型包括:
19、第一时序编码层、第二时序编码层、拼接层和时序解码层;
20、所述第一时序编码层用于对所述图像特征序列进行编码得到图像编码序列,所述图像编码序列包括每一个时间片的图像编码特征;
21、所述第二时序编码层用于对所述音频特征序列进行编码得到音频编码序列,所述音频编码序列包括每一个时间片的音频编码特征;
22、所述拼接层将所述图像编码序列和所述音频编码序列在预设维度上进行拼接,得到拼接序列;
23、所述时序解码层接收所述拼接序列并输出所述微表情识别结果序列,所述微表情识别结果序列包括每一个时间片的微表情识别结果。
24、在一些实施例中,所述时序模型的训练过程包括:
25、获取微表情数据集,所述微表情数据集包括多个微表情视频文件,每一个微表情视频文件均对应一个微表情标签,所述微表情标签为微表情视频文件中每一个时间片的微表情识别结果;
26、获取所有微表情视频文件的图像特征序列和音频特征序列,将同一微表情视频文件的图像特征序列、音频特征序列和微表情标签作为一组训练样本;
27、不断挑选训练样本输入所述时序模型得到输出结果,基于所述输出结果和所述微表情标签计算交叉熵损失函数,并利用梯度下降法更新所述时序模型,当交叉熵损失函数不再变化时停止训练,得到训练完毕的时序模型,所述交叉熵损失函数满足关系式:
28、
29、其中,n为训练样本中时间片的总数,m为不同微表情识别结果的总数,yij为微表情标签中时间片i属于微表情识别结果j的真实概率,pij为输出结果中时间片i属于微表情识别结果j的预测概率,loss为交叉熵损失函数的数值。
30、在一些实施例中,所述基于所述微表情识别结果的频率和频率阈值以获取所述待测人员的测谎结果包括:
31、基于每一种微表情识别结果对应的预设权重和频率计算测谎相关频率,所述测谎相关频率满足关系式:
32、
33、其中,m为不同微表情识别结果的总数,qj为微表情识别结果j的频率,αj微表情识别结果j的预设权重,∑α为所有微表情识别结果的预设权重的总和,q为测谎相关频率;
34、对比所述测谎相关频率和频率阈值,若所述测谎相关频率大于所述频率阈值,则所述待测人员的测谎结果为说谎,若所述测谎相关频率不大于所述频率阈值,则所述待测人员的测谎结果为未说谎。
35、在一些实施例中,所述频率阈值的获取方法包括:
36、采集多个业务数据并储存人为标注的所述多个业务数据的测谎结果作为测谎标签,所述业务数据为预设应用场景下的视频文件;
37、基于所述训练完毕的时序模型得到所述业务数据的微表情识别结果序列,计算所述微表情识别结果序列中每一种微表情识别结果的频率,并基于每一种微表情识别结果对应的预设权重和频率计算所述业务数据的测谎相关频率;
38、将所述测谎标签为说谎的业务数据对应的测谎相关频率作为第一数据集,将所述测谎标签为未说谎的业务数据对应的测谎相关频率作为第二数据集;
39、基于所述第一数据集和所述第二数据集计算频率阈值,所述频率阈值满足关系式:
40、
41、其中,n1为第一数据集中所有测谎相关频率的数量,n2为第二数据集中所有测谎相关频率的数量,为第一数据集中第n1个测谎相关频率,为第二数据集中第n2个测谎相关频率;q′为待定阈值;表示满足条件时的输出为1,否则输出为0;表示满足条件时的输出为1,否则输出为0;表示待定阈值q′对应的测谎准确率,n1的取值范围为[1,n1],n2的取值范围为[1,n2];q*表示频率阈值,为测谎准确率取最大值时待定阈值q′的取值。
42、本技术实施例还提供一种基于人工智能的测谎装置,所述装置包括:
43、采集单元,用于采集待测人员的视频文件,将所述视频文件拆分为图像序列和音频序列;
44、特征提取单元,用于分别对所述图像序列和所述音频序列进行特征提取以获取图像特征序列和音频特征序列;
45、输入单元,用于将所述图像特征序列和所述音频特征序列输入训练完毕的时序模型,得到微表情识别结果序列,所述微表情识别结果序列包括多种微表情识别结果;
46、计算单元,用于计算所述微表情识别结果序列中每一种微表情识别结果的频率;
47、测谎单元,用于基于所述微表情识别结果的频率和频率阈值以获取所述待测人员的测谎结果。
48、本技术实施例还提供一种电子设备,所述电子设备包括:
49、存储器,存储至少一个指令;
50、处理器,执行所述存储器中存储的指令以实现所述的基于人工智能的测谎方法。
51、本技术实施例还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现所述的基于人工智能的测谎方法。
52、综上,本技术提取待测人员视频文件中的图像信息和音频信息,并借助时序模型得到每一个时间片的微表情识别结果;进一步根据少量预设应用场景下人为标注的业务数据确定频率阈值,根据不同微表情识别结果的频率和频率阈值得到测谎结果,微表情识别结果可以反应待测人员真实的内心想法,且通过现有的微表情数据集和少量的人为标注的业务数据得到测谎结果,降低预设应用场景下业务数据标注成本的同时提高测谎结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!