面向非独立同分布场景的联邦学习蒸馏方法及装置与流程
本发明涉及人工智能,尤其涉及一种面向非独立同分布场景的联邦学习蒸馏方法及装置。
背景技术:
1、联邦学习(federated learning,fl)是一种新型的模型训练方法,可以通过各个分散的终端设备,将服务端下发的全局模型通过本地数据先进行初步训练,再让每个终端设备将初步训练好的本地模型上传到服务端,在服务端对每个上传的本地模型进行统一聚合,并将聚合模型下发至各终端设备。联邦学习实现了既让本地数据不泄漏,有效地保护了本地数据的隐私安全,又实现了充分利用海量分散的本地数据进行模型训练,获得拟合性能更加优良的本地模型。由于联邦学习允许参与者在不共享数据的前提下协同训练模型,很好地保护了本地数据的隐私并打破数据孤岛,因此联邦学习受到了广泛的关注,尤其广泛应用于分布式训练场景。
2、在分布式训练场景下,很多传统的分布式机器学习算法,都需要假设数据分布是均匀的,即各个终端设备之间的数据分布需要服从独立同分布(independent-andidentically-distritributed,iid)。然而,在现实生活中,本地数据的产生无法控制,不同终端设备上独立产生本地数据,当多个分散的终端设备作为联邦学习的参与方时,各个终端设备上的本地数据有可能是非独立同分布(non-independent-and-identically-distributed,non-iid)的,甚至本地数据带有的标签也是非独立同分布的,这将导致联邦学习中模型训练效率大幅下降,模型泛化能力弱的问题出现。而且,联邦学习的参与方在进行联邦学习后,得到的聚合模型的准确性提升不大,甚至会有所降低。
3、因此,如何提高联邦学习在non-iid场景下的模型训练效率,提升模型泛化能力,提高聚合模型的准确性至关重要。
技术实现思路
1、本发明提供一种面向非独立同分布场景的联邦学习蒸馏方法及装置,用以解决现有技术中存在的缺陷。
2、本发明提供一种面向非独立同分布场景的联邦学习蒸馏方法,应用于目标终端,所述目标终端归属的目标服务端下各终端的数据和/或标签满足非独立同分布;所述方法包括:
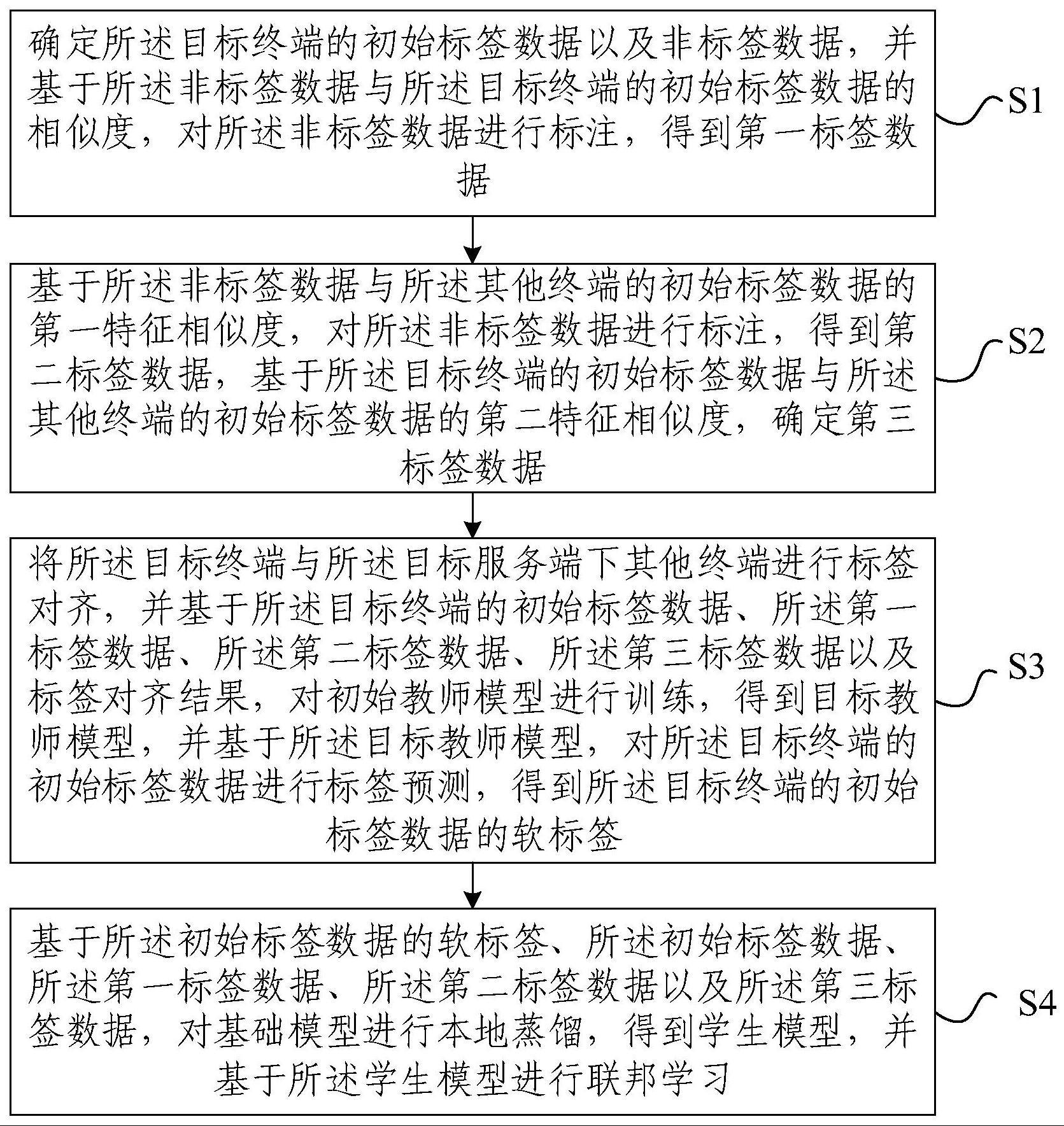
3、确定所述目标终端的初始标签数据以及非标签数据,并基于所述非标签数据与所述目标终端的初始标签数据的相似度,对所述非标签数据进行标注,得到第一标签数据;
4、基于所述非标签数据与所述其他终端的初始标签数据的第一特征相似度,对所述非标签数据进行标注,得到第二标签数据,基于所述目标终端的初始标签数据与所述其他终端的初始标签数据的第二特征相似度,确定第三标签数据;
5、将所述目标终端与所述目标服务端下其他终端进行标签对齐,并基于所述目标终端的初始标签数据、所述第一标签数据、所述第二标签数据、所述第三标签数据以及标签对齐结果,对初始教师模型进行训练,得到目标教师模型,并基于所述目标教师模型,对所述目标终端的初始标签数据进行标签预测,得到所述目标终端的初始标签数据的软标签;
6、基于所述目标终端的初始标签数据的软标签、所述目标终端的初始标签数据、所述第一标签数据、所述第二标签数据以及所述第三标签数据,对基础模型进行本地蒸馏,得到学生模型,并基于所述学生模型进行联邦学习。
7、根据本发明提供的一种面向非独立同分布场景的联邦学习蒸馏方法,所述第一特征相似度,基于如下步骤确定:
8、确定初始特征提取模型,并基于所述初始特征提取模型,提取所述非标签数据的第一特征向量;
9、将所述初始特征提取模型中的预设结构进行差分隐私保护,得到目标特征提取模型;
10、将所述目标特征提取模型发送至所述其他终端,并接收所述其他终端基于所述目标特征提取模型提取的其初始标签数据的第二特征向量;
11、确定所述第一特征向量与所述第二特征向量之间的相似度为所述第一特征相似度。
12、根据本发明提供的一种面向非独立同分布场景的联邦学习蒸馏方法,所述第二特征相似度,基于如下步骤确定:
13、基于所述初始特征提取模型,提取所述目标终端的初始标签数据的第三特征向量;
14、确定所述第三特征向量与所述第二特征向量之间的相似度为所述第二特征相似度。
15、根据本发明提供的一种面向非独立同分布场景的联邦学习蒸馏方法,所述基于所述学生模型进行联邦学习,包括:
16、将所述学生模型上传至所述目标服务端;
17、接收所述目标服务端基于对所述各终端上传的学生模型进行联邦平均聚合后得到的聚合模型,并将所述聚合模型作为所述基础模型循环进行本地蒸馏,直至联邦学习结束。
18、根据本发明提供的一种面向非独立同分布场景的联邦学习蒸馏方法,所述基于所述非标签数据与所述目标终端的初始标签数据的相似度,对所述非标签数据进行标注,得到第一标签数据,包括:
19、确定所述目标终端的初始标签数据中与所述非标签数据的相似度最大的第一相似数据,并基于所述第一相似数据带有的标签,对所述非标签数据进行标注,得到所述第一标注数据。
20、根据本发明提供的一种面向非独立同分布场景的联邦学习蒸馏方法,所述基于所述非标签数据与所述其他终端的初始标签数据的第一特征相似度,对所述非标签数据进行标注,得到第二标签数据,包括:
21、确定所述其他终端的初始标签数据中与所述非标签数据的第一特征相似度最大的第二相似数据,并基于所述第二相似数据带有的标签,对所述非标签数据进行标注,得到所述第二标注数据。
22、根据本发明提供的一种面向非独立同分布场景的联邦学习蒸馏方法,所述基于所述目标终端的初始标签数据与所述其他终端的初始标签数据的第二特征相似度,确定第三标签数据,包括:
23、计算第三相似数据与第四相似数据带有的标签均值,所述第三相似数据为大于预设阈值的第二特征相似度对应的所述目标终端的初始标签数据,所述第四相似数据为大于所述预设阈值的第二特征相似度对应的所述其他终端的初始标签数据;
24、将所述标签均值作为所述第三相似数据的标签,得到所述第三标签数据。
25、本发明还提供一种面向非独立同分布场景的联邦学习蒸馏装置,应用于目标终端,所述目标终端归属的目标服务端下各终端的数据和/或标签满足非独立同分布;所述装置包括:
26、数据聚合模块,用于确定所述目标终端的初始标签数据以及非标签数据,并基于所述非标签数据与所述目标终端的初始标签数据的相似度,对所述非标签数据进行标注,得到第一标签数据;
27、数据标注模块,用于将所述目标终端与所述目标服务端下其他终端进行标签对齐,并基于所述非标签数据与所述其他终端的初始标签数据的第一特征相似度,对所述非标签数据进行标注,得到第二标签数据,基于所述目标终端的初始标签数据与所述其他终端的初始标签数据的第二特征相似度,确定第三标签数据;
28、标签预测模块,用于基于所述目标终端的初始标签数据、所述第一标签数据、所述第二标签数据、所述第三标签数据以及标签对齐结果,对初始教师模型进行训练,得到目标教师模型,并基于所述目标教师模型,对所述目标终端的初始标签数据进行标签预测,得到所述目标终端的初始标签数据的软标签;
29、联邦蒸馏模块,用于基于所述目标终端的初始标签数据的软标签、所述目标终端的初始标签数据、所述第一标签数据、所述第二标签数据以及所述第三标签数据,对基础模型进行本地蒸馏,得到学生模型,并基于所述学生模型进行联邦学习。
30、本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述的面向非独立同分布场景的联邦学习蒸馏方法。
31、本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述的面向非独立同分布场景的联邦学习蒸馏方法。
32、本发明还提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现如上述任一种所述的面向非独立同分布场景的联邦学习蒸馏方法。
33、本发明提供的面向非独立同分布场景的联邦学习蒸馏方法及装置,该方法借助于目标终端的非标签数据与目标终端的初始标签数据的相似度、与其他终端的初始标签数据的第一特征相似度以及目标终端的初始标签数据与其他终端的初始标签数据的第二特征相似度,可以丰富初始教师模型以及基础模型的训练样本,不仅可以大大提高初始教师模型以及基础模型的训练效率,还可以使得到的目标教师模型以及学生模型的泛化能力更强,进而可以提升联邦学习得到的聚合模型的准确性。此外,该方法结合知识蒸馏以及联邦学习,可以使学生模型学习到自身完全不存在的其他终端的知识,即自身数据没有相关标签,但是能通过联邦学习学到相关知识,这是一种极端的对于数据标签的非独立同分布场景。同时该方法能够通过联邦学习使学生模型已经拥有的拟合能力更佳。
- 还没有人留言评论。精彩留言会获得点赞!