基于非易失内存的深度神经网络checkpoint优化系统以及方法
本发明涉及计算机科学领域中的存储系统领域及深度学习系统领域,特别是涉及一种基于非易失内存的深度神经网络checkpoint优化系统以及方法。
背景技术:
1、随着神经网络模型结构和训练集群系统的复杂性与日俱增,训练模型的持久化和数据容错性成为了大规模训练系统中重要的问题。
2、现有神经网络的checkpointing涉及gpu、网络、存储等多个软硬件层,复杂的软件层导致高性能硬件的设备无法充分利用,严重影响了数据持久化时读取和写入性能;并且现有方案的性能不足使得神经网络训练缺乏细粒度的checkpoint机制,使得神经网络训练的容错性较低,缺乏快速数据恢复机制;另外在分布式、多用户的现代神经网络训练过程中,由于硬件和系统故障频发,用户需要高性能的数据持久化机制,但目前缺乏类似的系统。
技术实现思路
1、鉴于以上所述现有技术的缺点,本发明的目的在于提供一种基于非易失内存的深度神经网络checkpoint优化系统以及方法,用于解决以上现有技术问题。
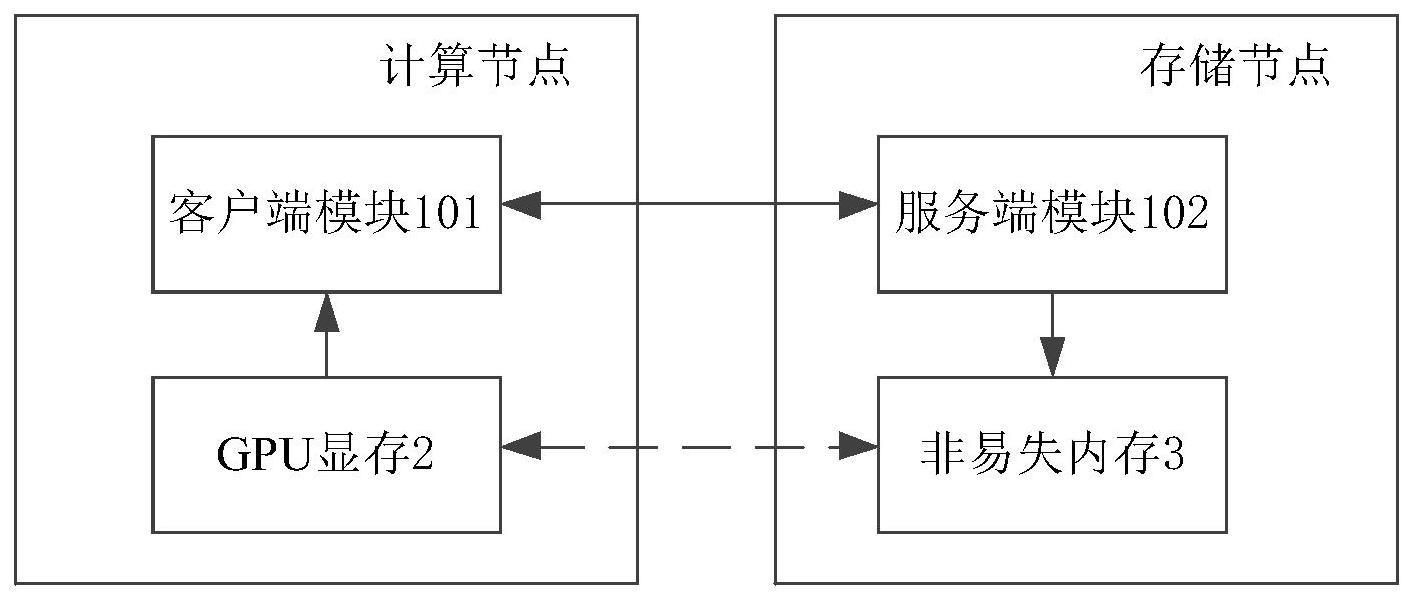
2、为实现上述目的及其他相关目的,本发明提供一种基于非易失内存的深度神经网络checkpoint优化系统,所述系统包括:位于装有gpu显存的计算节点内的客户端模块以及位于装有非易失内存的存储节点内的服务端模块;其中,在每个神经网络模型训练开始之前,所述客户端模块将对存储在所述gpu显存的对应神经网络模型进行初始化获得的网络结构发送给客户端模块构建该神经网络模型在所述非易失内存上的索引结构,以建立所述gpu显存到所述非易失内存之间的端到端通信;当所述服务端模块在对应神经网络模型训练过程中接收到来自客户端模块的checkpoint请求时,基于该神经网络模型的索引结构直接将对应的模型数据由所述gpu显存读取到非易失内存上。
3、于本发明的一实施例中,所述客户端模块对存储在所述gpu显存的对应神经网络模型进行初始化获得网络结构的方式包括:通过神经网络框架收集对应神经网络模型中指向模型每一层的gpu内存指针;使用nvidia peer memory内核模块基于模型每一层的gpu内存指针将模型每一层的gpu地址空间注册为rdma内存区域,并给每个内存区域都赋予唯一的标识符;将各标识符与模型每一层的元数据一一对应地聚合到一个模型结构包中。
4、于本发明的一实施例中,所述客户端模块构建该神经网络模型在所述非易失内存上的索引结构的方式包括:当接收到所述模型结构包后,从线程池中选择一线程基于该模型结构包在非易失内存中构建对应该神经网络模型的索引结构,以便将该神经网络模型的每一层一一映射到checkpoint结构。
5、于本发明的一实施例中,所述索引结构为三级索引结构,包括:位于第一级的模型表、位于第二级的模型元数据以及位于第三级的模型数据信息。
6、于本发明的一实施例中,所述当所述服务端模块在对应神经网络模型训练过程中接收到来自客户端模块的checkpoint请求时,基于该神经网络模型的索引结构直接将对应的模型数据由所述gpu显存读取到非易失内存上的方式包括:当所述客户端模块在对应神经网络模型训练过程中接收到用户checkpoint请求时,获取对应的gpu内存指针并向所述服务端模块发送生成的checkpoint请求;所述服务端模块基于来自客户端模块的checkpoint请求,控制对应的线程基于对应构建的索引结构通过rdma读操作直接将对应的模型数据由所述gpu显存读取到非易失内存上。
7、于本发明的一实施例中,当所述服务端模块接收到来自客户端模块的数据恢复请求时,基于该神经网络模型的索引结构主动将对应的模型数据从所述非易失内存写入所述gpu显存中。
8、于本发明的一实施例中,所述客户端模块通过ipoib协议或tcp协议与服务端模块通信。
9、于本发明的一实施例中,所述神经网络框架为pytorch软件库。
10、为实现上述目的及其他相关目的,本发明提供一种基于非易失内存的深度神经网络checkpoint优化方法,用于基于非易失内存的深度神经网络checkpoint优化系统,包括:位于装有gpu显存的计算节点内的客户端模块以及位于装有非易失内存的存储节点内的服务端模块,所述方法包括:在每个神经网络模型训练开始之前,所述客户端模块将对存储在所述gpu显存的对应神经网络模型进行初始化获得的网络结构发送给客户端模块构建该神经网络模型在所述非易失内存上的索引结构,以建立所述gpu显存到所述非易失内存之间的端到端通信;当所述服务端模块在对应神经网络模型训练过程中接收到来自客户端模块的checkpoint请求时,基于该神经网络模型的索引结构直接将对应的模型数据由所述gpu显存读取到非易失内存上。
11、于本发明的一实施例中,所述方法还包括:当所述服务端模块接收到来自客户端模块的数据恢复请求时,基于该神经网络模型的索引结构主动将对应的模型数据从所述非易失内存写入所述gpu显存中。
12、如上所述,本发明是一种基于非易失内存的深度神经网络checkpoint优化系统以及方法,具有以下有益效果:本发明通过客户端模块以及服务端模块在深度神经网络训练开始前将对应的网络结构注册在非易失内存中,并创建数据索引和基于远程直接内存访问(rdma)的数据通信协议;并且在神经网络训练过程中,本发明提供了零拷贝、异步、端到端的神经网络数据持久化,使得用户可以在不影响训练速度的前提下做细粒度的checkpointing以保证容错性和数据持久性。
技术特征:
1.一种基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述系统包括:
2.根据权利要求1中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述客户端模块对存储在所述gpu显存的对应神经网络模型进行初始化获得网络结构的方式包括:
3.根据权利要求2中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述客户端模块构建该神经网络模型在所述非易失内存上的索引结构的方式包括:
4.根据权利要求3中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述索引结构为三级索引结构,包括:位于第一级的模型表、位于第二级的模型元数据以及位于第三级的模型数据信息。
5.根据权利要求4中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述当所述服务端模块在对应神经网络模型训练过程中接收到来自客户端模块的checkpoint请求时,基于该神经网络模型的索引结构直接将对应的模型数据由所述gpu显存读取到非易失内存上的方式包括:
6.根据权利要求1中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,当所述服务端模块接收到来自客户端模块的数据恢复请求时,基于该神经网络模型的索引结构主动将对应的模型数据从所述非易失内存写入所述gpu显存中。
7.根据权利要求1中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述客户端模块通过tcp协议与服务端模块通信。
8.根据权利要求2中所述的基于非易失内存的深度神经网络checkpoint优化系统,其特征在于,所述神经网络框架为pytorch软件库。
9.一种基于非易失内存的深度神经网络checkpoint优化方法,其特征在于,应用于基于非易失内存的深度神经网络checkpoint优化系统,包括:位于装有gpu显存的计算节点内的客户端模块以及位于装有非易失内存的存储节点内的服务端模块,所述方法包括:
10.根据权利要求9中所述的基于非易失内存的深度神经网络checkpoint优化方法,其特征在于,所述方法还包括:
技术总结
本发明提供一种基于非易失内存的深度神经网络checkpoint优化系统以及方法,通过客户端模块以及服务端模块在深度神经网络训练开始前将对应的网络结构注册在非易失内存中,并创建数据索引和基于远程直接内存访问(RDMA)的数据通信协议;并且在神经网络训练过程中,本发明提供了零拷贝、异步、端到端的神经网络数据持久化,使得用户可以在不影响训练速度的前提下做细粒度的checkpointing以保证容错性和数据持久性。
技术研发人员:殷树,吴天元,李元皓
受保护的技术使用者:上海科技大学
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!