基于OCR-NER的结构化电子病历构建方法和系统
本发明属于医疗文本处理,具体涉及一种基于ocr-ner的结构化电子病历构建方法和系统。
背景技术:
1、电子病历由于快捷、易于存储和管理的特点被广泛的应用于当前的医疗行业。现阶段大多数的医学病历报告是以非结构化的形式保存,其中包含大量未被利用的病历记录和专业知识。利用自然语言处理(nlp)可以充分的挖掘非结构化报告中包含的蕴藏的知识,提取关键信息并构建结构化病历报告,对提升医疗系统服务质量有非常重要的意义。
2、结构化电子病历是指从医生描述的自然语言文本抽取出多个关键字段,对医疗文本进行结构化提取,进而提高医护人员查阅病历的效率。命名实体识别(ner)作为nlp的一个基础任务,用于从电子病历中提取实体类别,并将结果进一步应用于后续智能化医疗服务。基于ner的结构化电子病历能够自动化地提取医疗文本数据中的关键信息,但这种方法处理的形式仅仅局限于文本格式。目前,医疗行业中,还有大量的电子病历是以图像格式进行保存的,现有的ner方法不能从电子病历图像中自动提取文本信息。
3、ocr文字识别是指通过检查待提取资料中包含的文字字符,对文本资料进行扫描后对图像文件进行分析处理。中国发明专利申请“cn202210645155.5一种基于ocr与ner技术的主数据智能识别方法”构建了一种利用ocr从图像中提取文字,并使用ner技术对提取到的文字进行结构化的技术方案。然而,电子病历的形式多种多样,并且很多医学专用名词在ocr过程中会被错误的识别为常用词,难以仅仅通过分词+匹配的方式有效提取。
技术实现思路
1、针对现有技术的上述问题,本发明提供一种基于ocr-ner的结构化电子病历构建方法和系统,目的在于实现将电子病历图像转化为格式化电子病历的目的。
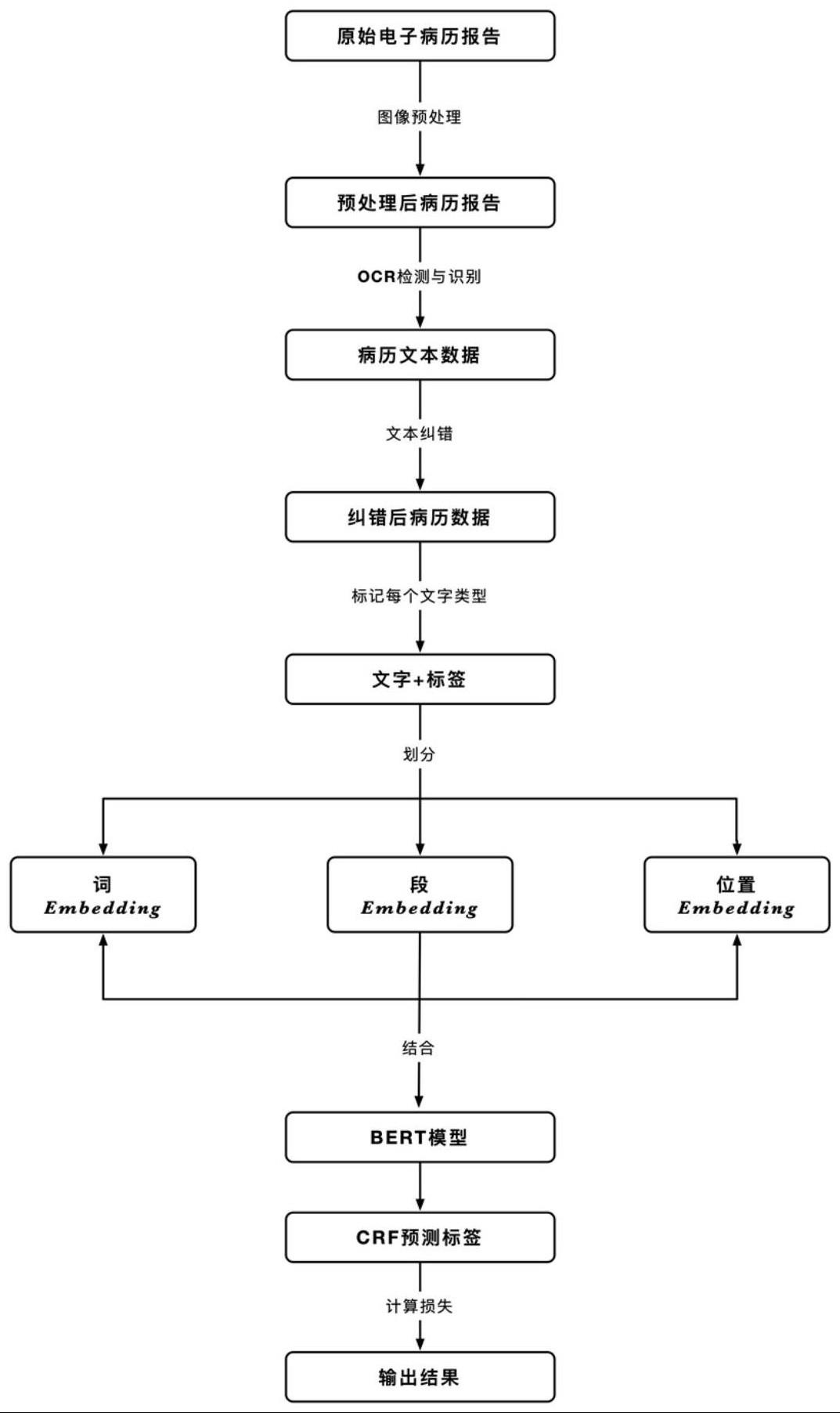
2、一种基于ocr-ner的结构化电子病历构建方法,包括如下步骤:
3、步骤1,输入电子病历图像,进行预处理;
4、步骤2,对预处理后的电子病历图像进行ocr检测和识别,提取病历文本数据;
5、步骤3,采用bert模型对提取到的文本数据执行文本纠错;
6、步骤4,对纠错后的文本数据分别做词、段和位置的embedding,得到词embedding、段embedding和位置embedding;
7、步骤5,采用bert-crf模型进行特征提取,预测,生成每一个文字的标签值,计算损失并输出结果。
8、优选的,步骤1中,所述预处理的过程包括如下方法中的至少一种:
9、(1)采用非局部均值滤波降噪算法去除图像中的椒盐噪声;
10、(2)采用自适应阈值算法进行图像二值化处理。
11、优选的,所述非局部均值滤波降噪算法的计算公式如下:
12、
13、
14、
15、其中,v表示噪声图像,nlmeans[v]表示恢复图像,w(i,j)表示当前像素i和其余像素j的相似程度,a是高斯核的标准差,z(i)为像素i归一化常数,v(ni)和v(nj)分别为像素i、j的强度灰度向量。
16、优选的,所述自适应阈值算法的计算公式如下:
17、i(x,y)=f(x,y)+i(x-1,y)+i(x,y-1)-i(x-1,y-1)
18、
19、其中,i(x,y)表示坐标(x,y)处的积分值计算,表示两个对角点像素之和的计算,(x1,y1)和(x2,y2)分别为两个对角点的坐标。
20、优选的,步骤2中,所述ocr检测和识别的具体步骤包括:
21、步骤2.1采用可微二值化算法,根据db二值图拓展标签生成,形成文本框;
22、步骤2.2,对所述文本框内的文本信息,采用卷积循环神经网络生成对应的预测标签序列。
23、优选的,步骤2.2中,所述卷积循环神经网络选自crnn识别算法。
24、优选的,在训练所述bert-crf模型的过程中,训练数据采用采用bio标记方式进行标签类别标注。
25、本发明还提供一种用于实现上述基于ocr-ner的结构化电子病历构建方法的系统,包括:
26、数据预处理模块,用于进行电子病历图像的预处理;
27、ocr检测与识别模块,用于对预处理后的电子病历图像进行ocr检测和识别,提取病历文本数据;
28、文本纠错模块,用于采用bert模型对提取到的文本数据执行文本纠错;
29、embedding模块,用于对纠错后的文本数据分别做词、段和位置的embedding,得到词embedding、段embedding和位置embedding;
30、crf预测模块,用于采用bert-crf模型进行特征提取,预测,生成每一个文字的标签值,计算损失并输出结果。
31、优选的,还包括:
32、数据标记模块,用于在模型训练过程中标记文本纠错后的数据类别标签;
33、模型训练模块,用于将标记后的数据送入bert-crf模型中进行训练。
34、本发明还提供一种计算机可读存储介质,其上存储有用于实现上述基于ocr-ner的结构化电子病历构建方法的计算机程序。
35、本发明通过结合ocr与ner,可以很方便的从原始电子病历图像中提取文本信息。为了解决医学专用名词在ocr过程中会被错误的识别为常用词,难以仅仅通过分词+匹配的方式有效提取的问题。本发明同时结合文本纠错方案进一步提升识别结果准确率,通过利用训练后的模型提取出病历报告中的实体关系并构建结构化电子病历,推动智能化医疗服务的发展。
36、显然,根据本发明的上述内容,按照本领域的普通技术知识和惯用手段,在不脱离本发明上述基本技术思想前提下,还可以做出其它多种形式的修改、替换或变更。
37、以下通过实施例形式的具体实施方式,对本发明的上述内容再作进一步的详细说明。但不应将此理解为本发明上述主题的范围仅限于以下的实例。凡基于本发明上述内容所实现的技术均属于本发明的范围。
技术特征:
1.一种基于ocr-ner的结构化电子病历构建方法,其特征在于,包括如下步骤:
2.按照权利要求1所述的结构化电子病历构建方法,其特征在于,步骤1中,所述预处理的过程包括如下方法中的至少一种:
3.按照权利要求2所述的结构化电子病历构建方法,其特征在于,所述非局部均值滤波降噪算法的计算公式如下:
4.按照权利要求2所述的结构化电子病历构建方法,其特征在于,所述自适应阈值算法的计算公式如下:
5.按照权利要求1所述的结构化电子病历构建方法,其特征在于,步骤2中,所述ocr检测和识别的具体步骤包括:
6.按照权利要求5所述的结构化电子病历构建方法,其特征在于,步骤2.2中,所述卷积循环神经网络选自crnn识别算法。
7.按照权利要求1所述的结构化电子病历构建方法,其特征在于,在训练所述bert-crf模型的过程中,训练数据采用采用bio标记方式进行标签类别标注。
8.一种用于实现权利要求1-7任一项所述基于ocr-ner的结构化电子病历构建方法的系统,其特征在于,包括:
9.按照权利要求8所述的系统,其特征在于,还包括:
10.一种计算机可读存储介质,其特征在于:其上存储有用于实现权利要求1-7任一项所述基于ocr-ner的结构化电子病历构建方法的计算机程序。
技术总结
本发明属于医疗文本处理技术领域,具体涉及一种基于OCR‑NER的结构化电子病历构建方法和系统。本发明的方法包括如下步骤:步骤1,输入电子病历图像,进行预处理;步骤2,对预处理后的电子病历图像进行OCR检测和识别,提取病历文本数据;步骤3,采用BERT模型对提取到的文本数据执行文本纠错;步骤4,对纠错后的文本数据分别做词、段和位置的Embedding,得到词Embedding、段Embedding和位置Embedding;步骤5,采用BERT‑CRF模型进行特征提取,预测,生成每一个文字的标签值,计算损失并输出结果。本发明进一步提供了实现上述方法的系统。本发明可对图像格式的电子病历进行结构化处理,为后续的患者随访和医疗服务带来更多便利,具有很好的应用前景。
技术研发人员:吕青,张思洲,刘德建,宿启晨,徐浩
受保护的技术使用者:四川大学华西医院
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!