粗粒度可重构阵列数据流处理器的高效执行方法及系统
本发明涉及计算机体系结构,并特别涉及一种高效的数据流处理器设计方法和系统。
背景技术:
1、冯诺依曼结构是当今大多数计算机芯片使用的架构。这种结构的特点在于将指令和数据都存储在内存当中,顺序读取,顺序执行。在冯诺依曼架构种,一个程序表现为一个指令序列,而冯诺依曼机器运行方式就是顺序地执行这串指令,这种执行模型被称为控制流模型(control flow model)。
2、而在19世纪70年代,一种全新的数据流模型被提出。其核心思想为:一个程序可以表示为一个有向数据流图(directed dataflow graph,dfg)。在这个图中,节点表示指令,其中的连线表示数据,连线的方向表示数据在指令之间的依赖关系。对于任何一个节点(也就是指令)来说,只要其依赖的操作数准备好了,其就可以开始执行。这种数据流模型相对于传统的控制流模型而言,有以下优点:
3、1.数据流模型让数据在指令节点之间流动,避免了频繁的存储和取用,在计算密集型应用场景下能够大大减少访存时间,提高程序运行的效率;
4、2.数据流模型让指令分散在多个处理单元当中,每条指令在其操作数准备好之后就可以发射执行。相对于冯诺依曼架构,大大增加了指令级并行;
5、3.数据流模型将程序建模成一个有向图数据流图,这意味相对于gpu的执行模型,数据流模型具有高效处理复杂依赖的程序的优势。
6、粗粒度可重构阵列(coarse-grained reconfigurable array,cgra)是一种可以以数据流模型执行程序的一种空间计算(spatial computing)架构。cgra一般由片上网络连接、pe(processing element)阵列、host、缓存(buffer)等组成。cgra拥有比fpga(fieldprogrammable gate array,现场可编程门阵列)更好的可编程性,有比gpu更优秀的功耗表现和更通用的并行能力。cgra在执行程序前,一般首先有一个指令映射的过程。即将代表整个程序的dfg映射到pe阵列上——这决定了每条指令会在哪个时间点,在哪个pe上执行。
7、传统的用cgra执行数据流程序的方式都是严格按照细粒度的指令为单位:即在指令映射的时候以指令为单位进行映射;在执行过程中,每执行完一条指令就需要将生成的数据通过片上网络传输到需要此数据的pe上。这种细粒度执行模式的优点在于:一方面,指令映射的建模更加简单与直接,优化粒度也更细;另一方面,pe的控制逻辑也比较简单。其缺点在于:每执行一次指令就要一次传输开销,开销较大。
8、codelet模型是高性能计算领域中的一种对程序的粗粒度的划分,其相对传统的以指令为单位的细粒度数据流模型而言,它是一个以代码段为单位的粗粒度数据流模型——其每个节点是一个代码段而非指令。这种模型带来的好处是节点数可以大大减少,指令映射的开销也大大减少。
9、但是,如果直接将codelet模型运用到现有的cgra架构上,仍然是一次只执行一条指令。这种执行效率非常低下:在执行一条指令的过程中,pe中的所有部件都轮流处于空闲的状态,而其他指令也必须等待。
技术实现思路
1、本发明的目的是解决了现有cgra架构的运行模式不能充分利用codelet模型带来的优势,提出了一种能高效执行codelet模型的pe解耦合的设计以及具体cgra架构。
2、针对现有技术的不足,本发明提出一种粗粒度可重构阵列数据流处理器的高效执行方法,其中包括:
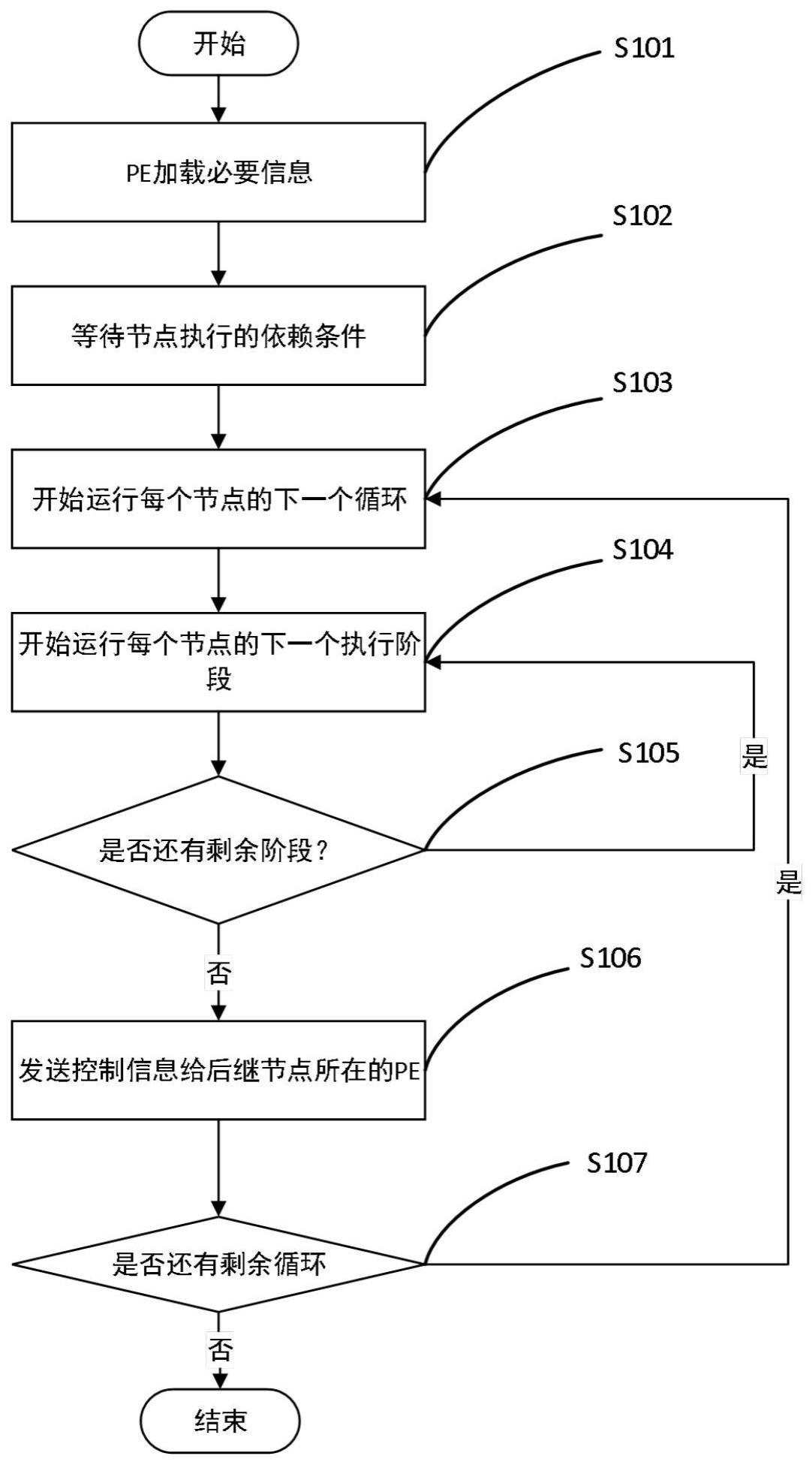
3、步骤1、获取以有向数据流图表示的待执行程序,且该有向数据流图中每个节点为一个代码段,节点间的连线方向表示数据在代码段之间的依赖关系;粗粒度可重构阵列数据流处理器的pe从其全局缓存中加载每个节点的配置信息、操作指令和操作数;
4、步骤2、调度前继依赖已满足的节点作为当前节点开始执行,并将当前节点的代码段分为多个执行阶段;
5、步骤3、调度该当前节点的下个循环开始执行,执行时监测当前节点的下个阶段对应的粗粒度可重构阵列数据流处理器部件已经空闲,则当前节点进入下一个执行阶段,并用粗粒度可重构阵列数据流处理器部件执行其下一个执行阶段;
6、步骤4、执行完当前循环,将当前循环的执行结果传输至该粗粒度可重构阵列数据流处理器中依赖当前节点的pe;
7、步骤5、判断是否运行完该有向数据流图中所有节点的循环,若是,则结束运行,从该粗粒度可重构阵列数据流处理器的全局缓存中输出当前运行结果,否则再次执行该步骤2。
8、所述的粗粒度可重构阵列数据流处理器的高效执行方法,其中该粗粒度可重构阵列数据流处理器的pe中具有分别对应读取阶段、计算阶段和存储阶段的读取部件、计算部件和存储部件。
9、所述的粗粒度可重构阵列数据流处理器的高效执行方法,其中该粗粒度可重构阵列数据流处理器的pe包括:
10、指令缓存,用于存储待执行的指令;
11、操作数寄存器,用于存储操作数;
12、路由,用于pe内数据的交换;
13、计算部件,包含算术和逻辑运算部件;
14、读取部件,从该粗粒度可重构阵列数据流处理器的该全局缓存中取数,存到pe内部的该操作数寄存器中;
15、存数部件,用于将该操作数寄存器中的数据存回到该全局缓存中;
16、传数部件,用于将数据传送到需要的pe;
17、控制器,用于控制整个pe的运行。
18、所述的粗粒度可重构阵列数据流处理器的高效执行方法,其中该控制器包括:
19、内核表,用于记录每个节点的配置信息,由编译器生成,包含了节点在各个执行阶段的基址信息、循环次数;
20、状态表,用于记录节点的状态信息,包括节点的依赖节点是否都已经执行完毕、节点当前所处的执行阶段;
21、调度部件,用于调度节点的执行;
22、消息处理部件,用于接收其他pe发送来的消息并做相应处理。
23、本发明还提出了一种粗粒度可重构阵列数据流处理器的高效执行系统,其中包括:
24、初始模块,用于获取以有向数据流图表示的待执行程序,且该有向数据流图中每个节点为一个代码段,节点间的连线方向表示数据在代码段之间的依赖关系;粗粒度可重构阵列数据流处理器的pe从其全局缓存中加载每个节点的配置信息、操作指令和操作数;
25、执行模块,用于调度前继依赖已满足的节点作为当前节点开始执行,并将当前节点的代码段分为多个执行阶段;
26、监测模块,用于调度该当前节点的下个循环开始执行,执行时监测当前节点的下个阶段对应的粗粒度可重构阵列数据流处理器部件已经空闲,则当前节点进入下一个执行阶段,并用粗粒度可重构阵列数据流处理器部件执行其下一个执行阶段;
27、传输模块,用于执行完当前循环,将当前循环的执行结果传输至该粗粒度可重构阵列数据流处理器中依赖当前节点的pe;
28、判断模块,用于判断是否运行完该有向数据流图中所有节点的循环,若是,则结束运行,从该粗粒度可重构阵列数据流处理器的全局缓存中输出当前运行结果,否则再次调度该执行模块。
29、所述的粗粒度可重构阵列数据流处理器的高效执行系统,其中该粗粒度可重构阵列数据流处理器的pe中具有分别对应读取阶段、计算阶段和存储阶段的读取部件、计算部件和存储部件。
30、所述的粗粒度可重构阵列数据流处理器的高效执行系统,其中该粗粒度可重构阵列数据流处理器的pe包括:
31、指令缓存,用于存储待执行的指令;
32、操作数寄存器,用于存储操作数;
33、路由,用于pe内数据的交换;
34、计算部件,包含算术和逻辑运算部件;
35、读取部件,从该粗粒度可重构阵列数据流处理器的该全局缓存中取数,存到pe内部的该操作数寄存器中;
36、存数部件,用于将该操作数寄存器中的数据存回到该全局缓存中;
37、传数部件,用于将数据传送到需要的pe;
38、控制器,用于控制整个pe的运行。
39、所述的粗粒度可重构阵列数据流处理器的高效执行系统,其中该控制器包括:
40、内核表,用于记录每个节点的配置信息,由编译器生成,包含了节点在各个执行阶段的基址信息、循环次数;
41、状态表,用于记录节点的状态信息,包括节点的依赖节点是否都已经执行完毕、节点当前所处的执行阶段;
42、调度部件,用于调度节点的执行;
43、消息处理部件,用于接收其他pe发送来的消息并做相应处理。
44、本发明还提出了一种存储介质,用于存储执行所述任意一种粗粒度可重构阵列数据流处理器的高效执行方法的程序。
45、本发明还提出了一种客户端,用于任意一种粗粒度可重构阵列数据流处理器的高效执行系统。
46、由以上方案可知,本发明的优点在于:本发明相比于现有技术,能够提高程序在cgra上执行的节点、指令并行度,从而提高程序指令的效率,缩短程序执行时间。另一方面,本发明也能充分提高cgra的部件利用率。
- 还没有人留言评论。精彩留言会获得点赞!