基于LDA主题模型的主播形象分类与关键特质分析方法
本发明涉及数据分析,具体涉及一种基于lda主题模型的主播形象分类与关键特质分析方法。
背景技术:
1、主播介绍是指在当前直播购物环境中,主播通过直播购物平台的个人信息界面向消费者和公司展现自我特征,明确直播内容,发布声明并提醒观众与公司相关直播信息的重要文本。随着信息技术和电子商务的飞速发展,越来越多的观众通过主播介绍进一步了解主播信息与其直播内容,从而关注主播、实现购买等。主播介绍作为主播风格与品牌特质的重要呈现方式,被主播们极大使用从而突出自身,推销自己,指导观众进行购买。但是,在现有的主播群体中存在哪些主播人设或者主播画像?这些不同类型的主播究竟是如何介绍自己?除此以外,这些不同类型主播的直播效果是否有差异,同时,不同类主播之间影响其直播效果差异的特质有哪些,需要哪些资源或者行为来提升某类主播的直播效果?无法明确主播介绍的相关元素与其占比,就无法对主播介绍方式进行指导,从而导致主播自我呈现、内容发布与用户偏好产生偏差,最终无法实现精准营销与个人品牌构建。不结合直播效果进行主播特质的对比分析,更无法了解到不同人设主播的努力方向。目前对此问题的研究更多使用实验法和定性的研究方法,无法对大量的文本数据进行深入的研究。同时现有的可针对大数据的主播画像往往需要人工编码,对信息的处理和挖掘依赖于人工标签(如《一种基于主播画像的声音分类方法》等)。且利用自然语言处理个人介绍并研究直播效果的文献相对较少,数据采集的样本也偏少,对文本内容的挖掘也不够充分,令公司难以真实快速地了解主播及个人形象,主播也难以精确有效的自我介绍,后续根据主播介绍特征的相关研究也无法深入开展,对其直播效果及关键特质更无法挖掘。
2、通过自然语言处理和机器学习,针对大量文本数据(主播介绍)迅速提炼核心内容,提炼主播介绍的侧重点与类别,研究介绍内容与其分类,迅速挖掘主播介绍中不同话题点的比例,依据主播介绍中占比最大比例的主题分布对该类主播进行分类并依据主题词分布进行画像(即不同类型的主播会有哪些特征),同时对比不同类型主播的直播效果及独特特征进行分析。此方法对实现主播与观众的精准介绍与内容呈现,挖掘并对比关键特征,提升直播参与方的沟通效率和直播的沉浸体验,具有显著意义。
技术实现思路
1、本发明为解决现有技术存在的上述问题,提供一种基于lda主题模型的主播形象分类与关键特质分析方法,能够对主播的介绍内容进行分析和归类(即能对主播形象分类与关键特质分析)。
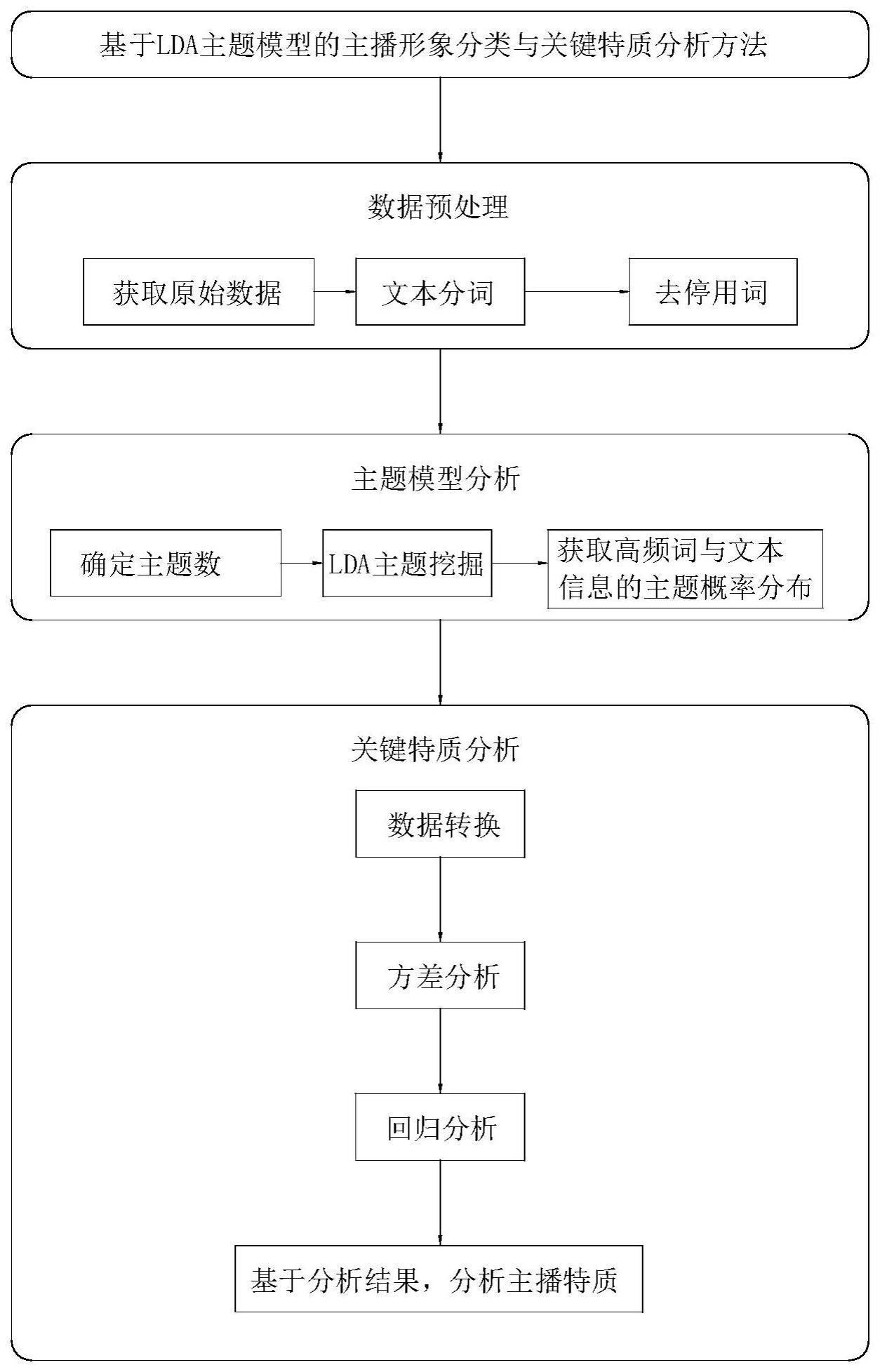
2、实现上述目的,本发明采取的技术方案如下:
3、基于lda主题模型的主播形象分类与关键特质分析方法,利用lda主题模型得到不同主题群体,了解不同主播群体的直播效果差异,挖掘影响该类群体直播效果的关键特质,所述方法包括以下步骤:
4、s1、在指示终端设备中获取每位主播的介绍文本,得到原始数据集;
5、s2、对原始数据集中的介绍文本进行数据预处理,得到初始数据集;
6、s3、根据初始数据集,构建lda主题模型;
7、s4、通过lda主题模型从初始数据集中挖掘出主题高频词和每位主播自我介绍的主题分布,确定主题数k,依据主题分布的最高值作为该主播形象分类;
8、s5、使用方差分析,得到不同主播群体之间的差异性特质,了解不同主播群体的直播效果差异;
9、s6、基于步骤s5中的不同主播群体之间的差异性特质和直播效果差异,使用回归分析,得到每个主播群体内的影响直播效果的关键特质。
10、进一步的是,所述步骤s2中,对原始数据集中的介绍文本进行数据预处理的具体步骤如下:
11、s21、筛选掉主播介绍内容为空的主播;
12、s22、在步骤s21基础上,对原始数据集进行文本分词,得到分词词汇集;
13、s23、根据停用词表收集停用词,去除分词词汇集中的停用词,得到初始数据集。
14、进一步的是,所述步骤s3中,构建lda主题模型的具体步骤如下:
15、s31、根据初始数据集,确定lda主题模型的主题数k,采用困惑度评价法求得最佳主题数k,困惑度计算公式为:
16、
17、其中,m为主播介绍的个数,ni为第i位主播的主播介绍中出现的词语总数,wi为构成第i位主播的主播介绍的词语,p(wi)表示基于主题数k的wi产生的概率;
18、为了保证聚类效果,得出主题数k为10以内的所有主题数k的困惑度;并依据手肘法,选择困惑度的拐点作为最佳主题数k;
19、s32、在先验参数为α和β的狄利克雷分布中,抽样生成基于最佳主题数k条件下的每位主播介绍的主题分布θ和所有主播介绍的主题词分布
20、α表示为每位主播介绍在主题上分布的狄利克雷先验参数;
21、β表示为所有主播介绍的主题词分布的狄利克雷先验参数;
22、s33、从每位主播介绍的主题分布θ中,抽样生成每位主播介绍的主题z,lda主题模型假设每位主播介绍都是由不同比例的词语组合组成的,反映了每位主播介绍的独特的主题,组合比例服从多项式分布,表示为:
23、z|θ=multinomial(θ)
24、从所有主播介绍的主题词分布中,抽样生成主题词w,每个主题k都是由主播介绍中的词语组成的,组合比例也服从多项式分布,表示为:
25、
26、其中,构成第i位主播的主播介绍的词语wi概率分布的计算公式为:
27、
28、其中,p(wi|z=s)表示词语wi属于第s个主题的概率;p(z=s|i)表示第i位主播介绍中第s个主题的概率;k为最佳主题数;p(wi|i)表示概率分布;
29、进一步的是,所述步骤s4中,通过lda主题模型从初始数据集中挖掘出主题高频词和每位主播自我介绍的主题分布,确定主题数k,依据主题分布的最高值作为该主播形象分类,具体步骤是:
30、s41、lda主题模型结果含有每个主题k下的高频词以及每位主播介绍的主题分布θ,分析最佳主题数k下,每个主题k的前20个高频词,同时对每个主题k进行定义与解释;
31、s42、为了避免不同主题k下相同高频词的出现,影响主题k的解释结果,采用主题-词语关联度,以控制显示某一主题k的不同的下位词项;
32、
33、其中,w表示语料库中的词语;k表示主题;p(w)表示词语w在所有主播介绍的主题词分布中的边际概率;表示词语w与主题k的相关度,λ=0时,显示主题k下特有的、相对独立的下位词项,即这些词项往往只出现在该主题;λ=1时,显示分布概率更高的下位词项,但是这些高分布概率的词项往往不单独属于该主题,也会同时属于其它主题,用户通过给定λ值,调节词语w与主题k的相关程度,即r(w,k|λ);
34、s43、依据主题分布的最高值,作为该主播形象分类,并依据步骤s42结果中的相对独立的下位词项和分布概率高的下位词项解释该主播的分类。
35、进一步的是,所述步骤s5中,使用方差分析,得到不同主播群体之间的差异性特质,了解不同主播群体的直播效果差异;具体步骤是:
36、s51、对主播的特征和效果数据进行对数处理,以避免极端值的影响,同时将偏态数据转换成正态数据;
37、s52、使用方差分析不同主播群体之间的直播特质和效果差异,方差分析用于定类数据与定量数据之间的差异分析,定类数据为主播分组,定量数据为直播效果;
38、进一步的是,所述步骤s6中,使用回归分析,得到每个主播群体内的影响直播效果的关键特质;具体步骤是:
39、s61、在每个主播群体内,以主播特质为自变量,直播效果为因变量,建立回归方程,
40、yi=k1xi1+k2xi2+k3xi3+...knxin+b+c
41、其中,yi表示第i位主播的销量;xi1....xin表示第i位主播的n个特质相关的变量;b表示主播的截距项;c表示主播的残差项;ki....kn表示n个特质对应的系数;
42、s62、对于每位主播而言,选择最大的k值,即为该主播最大影响因素,并依据不同的主播特质所对应的k值大小进一步分析变量的重要性。
43、与现有技术相比,本发明的有益效果是:本发明提出的一种基于lda主题模型的主播形象分类与关键特质分析方法,首先运用lda主题模型挖掘主播介绍,以此为语料库展开分析,并提取出高频特征词与不同主题所占比例。该方法使用的lda主题模型是一种无监督模型,仅需要主播介绍数据(即介绍文本)作为语料并且指定主题数量,无须标签即可完成训练,易于实现;依据结果,本方法能明确主播介绍内容的不同维度以及其所占比例(依据每位主播的主播介绍的主题分布与主题词分布分析得出),弥补了现有基于个人介绍的分析方法的不足,可以快速、高效、精确的对主播介绍内容展开分析。本发明中,lda主题模型能够依据所有主播的介绍文本,将每位主播的介绍匹配到最相关的主题,即在每位主播介绍中的不同主题的概率分布,从而深入理解直播电商与观众互动、品牌宣传的内在模式,并为进一步地探索不同介绍重点下的对于主播直播业绩的影响打好基础,为直播间的主播提供有效的支撑服务。本发明具有识别速度快、准确率高且易于实现等特点,成功为主播介绍的语义解析(即主播的文本数据分析)提供了可靠的保障,可广泛用于直播效果分析,从而为主播提供建议。本发明的方法解决了现有对于文本分类的方法往往采用主观定性的视角,通过机器学习将主播介绍进行分类,提高了分类的准确率,也充分考虑到了每位主播的异质性。这种分析方法可以广泛运用在主播介绍中,并适用于各类直播。
- 还没有人留言评论。精彩留言会获得点赞!