基于多尺度卷积的眼动事件检测方法
本发明属于眼动事件检测,具体涉及一种基于多尺度卷积的眼动事件检测方法。
背景技术:
1、眼动事件检测的目的是从眼动仪提取的原始眼球运动数据中准确鲁棒地提取注视、眼跳和眼跳后震荡等眼睛运动事件,其中关键挑战之一是学习到眼动序列中各个眼动事件的相关性,捕捉到与各个眼动事件相关的时间和空间信息。传统的基于模型的检测方法依赖于手工特征(眼睛位置、速度、加速度等),这些传统方法的检测效果不仅受限于特征提取方法的可靠性,而且难以处理多种类型的眼动事件检测,同时这类方法往往带有许多可调参数或硬编码参数,需要大量的经验知识进行调参。
2、新的发展是基于机器学习技术的事件检测方法的出现。tafaj等人(2012)提出了一种贝叶斯混合模型(bmm)的机器学习方法,使用瞬时速度来学习表示注视和眼跳的高斯分布的参数,该方法被开发用于驾驶过程中的辅助,并且使用驾驶数据进行测试。santini等人(2015)使用不同的方法将对平稳追踪事件的分类添加到bmm算法中,注视和眼跳的分类方法与bmm算法相同,而平稳追踪的概率通过速度和移动率来计算。以上方法采用的仍然是手工设计的特征,只不过在分类器设计上使用了机器学习方法。
3、近年来,深度学习的发展越来越迅速,其深层次和数据驱动的体系结构使许多任务取得了非常显著的性能提升,但对于眼动事件检测领域来说,其深度学习方法的应用相对来说较少。最早在眼动事件检测领域使用深度学习方法的是hoppe和bulling(2016)提出的眼动事件检测算法,该算法由端到端的单层卷积神经网络以及最大池化层和全连接层构成,用于检测注视、眼跳和平稳追踪这三种眼动事件。startsev等人(2018)提出了一个1d-cnn-blstm网络,将各种特征组合在gazecom数据集上与几种最先进的仅检测注视和眼跳的检测算法以及一些检测平稳追踪的检测算法进行了比较,大多数的特征组合要么具有竞争力,要么优于竞争对手。zemblys等人(2019)提出了一个名为gazenet的网络来进行序列到序列的分类。该网络由两个卷积核大小为2×11的卷积层、三个lstm层以及一个全连接层构成,来对注视、眼跳和眼跳后震荡三个眼动事件做事件分类。
4、目前基于深度学习的眼动事件检测方法普遍以卷积神经网络和lstm及其变体为主干网络,而由于眼动序列中不同事件的长短不一,注视的持续时间长,其包含的样本点多,眼跳和眼跳后震荡的持续时间短,其包含的样本点相对注视来说很少,所以使用单一尺度卷积核的卷积神经网络来提取特征无法对小样本事件进行有效的特征提取。
技术实现思路
1、本发明的目的是提供一种基于多尺度卷积的眼动事件检测方法,解决了单一尺度卷积核的卷积神经网络无法有效提取小样本事件的特征所造成的限制眼动事件检测方法性能的问题。
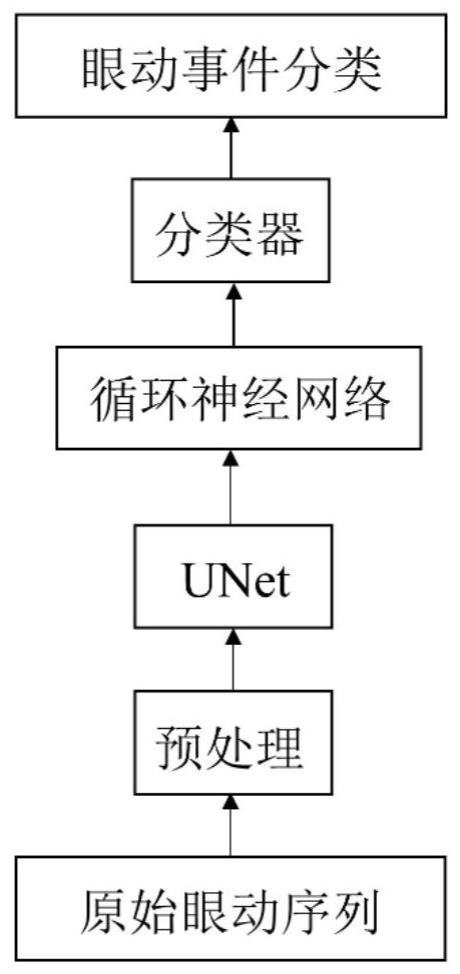
2、本发明所采用的技术方案是,基于多尺度卷积的眼动事件检测方法,包括以下步骤:
3、步骤1、眼动序列的预处理;
4、步骤2,利用unet模型对差分眼动序列进行多尺度特征提取与特征融合;
5、步骤3,使用循环神经网络模拟眼动事件序列;
6、步骤4、使用线性全连接层和softmax将眼动序列中每一时刻的样本点分类为注视、眼跳和眼跳后震荡,实现眼动事件检测;
7、步骤5、使用事件级cohen’s kappa来对分类后的三种眼动事件进行性能评估。
8、本发明的特征还在于,
9、步骤1具体按照以下步骤实施:
10、步骤1.1,选用公开的lund2013眼动事件检测数据集为原始眼动序列,对于原始眼动序列需要剔除平稳追踪、眨眼和未定义的眼动事件,使得眼动序列仅包含注视、眼跳和眼跳后震荡三个事件以进行训练和测试;
11、步骤1.2,将剔除多余事件后的原始眼动序列进行分段操作,使得每段眼动序列只包含100个样本点,这是由于原始眼动序列很长会导致模型训练起来有很大的计算量,将序列分段后降低模型训练难度,分段过程中以overlap的方式进行裁剪,得到分段眼动序列,每段分段眼动序列的段尾与下一段分段眼动序列的段首重叠10个样本点;
12、步骤1.3,对分段眼动序列进行差分操作得到差分眼动序列,差分眼动序列作为unet网络的输入,输入的分段眼动序列首先在序列最前端复制首位样本点,使得分段眼动序列包含101个样本点;其中,分段眼动序列表示为:[(xs0,ys0),(xs1,ys1),(xs2,ys2),…,(xs(m-1),ys(m-1)),(xsm,ysm)],差分后的差分眼动序列表示为:共100个样本点,其中差分计算公式为:
13、
14、
15、其中xsm和ysm表示分段眼动序列第m时刻样本点的坐标值,xs(m-1)和ys(m-1)表示分段眼动序列第m-1时刻样本点的坐标值,和表示差分眼动序列第m时刻样本点的坐标值。
16、步骤2中,unet模型由编码器和解码器组成,其中编码器模块负责特征提取,由4个下采样块组成,每个下采样块由两个3*5的卷积核进行卷积以及一个3*5的池化核进行最大池化构成;解码器模块负责恢复原始分辨率,由4个上采样块组成,每个上采样块由上采样产生的特征向量与左侧同一层级下采样块产生的特征向量进行特征融合操作以及两个3*5的卷积核进行的卷积操作构成,其中每个上采样块经过上采样之后得到的特征向量与同一层级下采样块产生的相同维度的特征向量进行特征融合,从而实现多尺度卷积的特征融合,使得模型对大样本和小样本具有相同的关注度。
17、步骤2中,下采样块中的卷积层使用padding补零,使得卷积前后序列的尺寸不变;每个下采样块经过两层卷积之后,感受野分别达到9、13、17、21,每个下采样块输出的特征向量的尺寸分别是[2,100,32](其中2表示眼动序列中的水平方向和垂直方向两个通道,100表示序列长度100个样本点,32表示特征向量的维度)、[2,96,64]、[2,92,128]、[2,88,256]。
18、步骤3中,使用的循环神经网络为3层,每层包含64个神经元。
19、步骤4中,使用的线性全连接层为1层,输出类别为3类,分别对应注视、眼跳和眼跳后震荡三个眼动事件,训练过程中使用的损失函数是加权交叉熵损失函数,训练集中注视、眼跳和眼跳后震荡的样本权重比为[0.8557,0.1045,0.0398],加权交叉熵损失函数的权重根据训练集中的样本权重比计算为[0.1443,0.8955,0.9602]。
20、步骤5中,评估过程中使用事件级cohen’s kappa来对检测结果进行性能评估,cohen’s kappa分数是两个评级者对同一信号的评级之间的度量,用于比较算法与手动评估之间的一致程度,其公式如下:
21、
22、其中po是评分者之间相对观察到的一致性,表示阳性的样本相对于样本总数的分数,pe表示随机打乱提交结果得到的概率,其公式如下:
23、
24、其中n是样本数量,k是类别数量,nk1是评分者1预测类别k的次数,nk2是评分者2预测类别k的次数。
25、本发明的有益效果是:
26、本发明方法采用了基于多尺度卷积的方法来对眼动事件进行检测,综合了unet和循环神经网络的优点,unet模型进行多尺度深层特征提取与特征融合,循环神经网络用于模拟眼动事件序列,负责检测注视、眼跳和眼跳后震荡样本点的开始和偏移。相比现有使用单一尺度卷积神经网络的方法,unet模型能够更好地学习到序列中小样本的特征信息,使模型能够对持续时间长的大样本事件和持续时间短的小样本事件具有相同的关注度,综合提升眼动事件检测的检测精度。
- 还没有人留言评论。精彩留言会获得点赞!