结合深度学习与语言逻辑推理的舆情分析方法与流程
本发明涉及工业控制,具体涉及一种结合深度学习与语言逻辑推理的舆情分析方法。
背景技术:
1、随着网络技术的快速发展,互联网已成为公众获取信息、表达观点的重要平台。网络舆情是公众对互联网上传播的热点问题所表现的具有一定影响力和倾向性的意见或言论的状态,它通过互联网对社会问题发表看法,或表达有较强影响力、倾向性的言论和观点。网络的舆情状况可以反映社会状态,有效的舆情监控与分析能够帮助锁定热点话题、快速通晓网民情绪发展、明确舆情现状,同时有助于引导舆情走向,避免舆情危机。针对舆情事件的描述,主要来自网络媒体上的新闻文本和类似新浪微博的社交平台,人们通过阅读、转发、评论等,直接告知他人或者从他人那里间接了解到舆情事件的相关信息。需要一种可针对这些事件信息从中提取特征并进一步准确地分析舆情当前的情况和传播趋势的舆情系统。
技术实现思路
1、本发明正是基于上述问题,提出了结合深度学习与语言逻辑推理的舆情分析方法,通过本发明的方案,利用深度学习技术和自然语言逻辑推理,可以准确地进行舆情分析。
2、有鉴于此,本发明的一方面提出了一种结合深度学习与语言逻辑推理的舆情分析方法,包括:
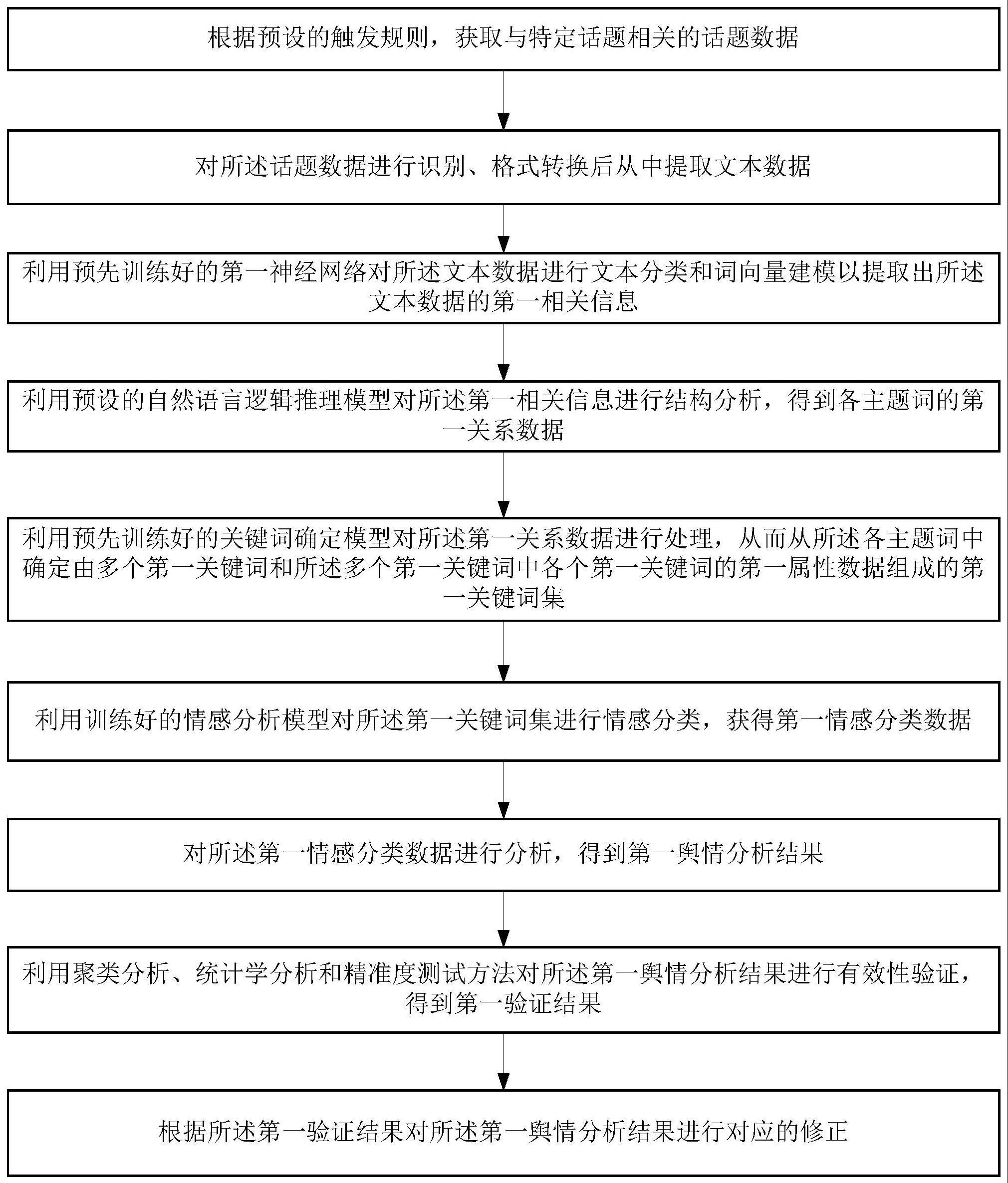
3、根据预设的触发规则,获取与特定话题相关的话题数据;
4、对所述话题数据进行识别、格式转换后从中提取文本数据;
5、利用预先训练好的第一神经网络对所述文本数据进行文本分类和词向量建模以提取出所述文本数据的第一相关信息;
6、利用预设的自然语言逻辑推理模型对所述第一相关信息进行结构分析,得到各主题词的第一关系数据;
7、利用预先训练好的关键词确定模型对所述第一关系数据进行处理,从而从所述各主题词中确定由多个第一关键词和所述多个第一关键词中各个第一关键词的第一属性数据组成的第一关键词集;
8、利用训练好的情感分析模型对所述第一关键词集进行情感分类,获得第一情感分类数据;
9、对所述第一情感分类数据进行分析,得到第一舆情分析结果;
10、利用聚类分析、统计学分析和精准度测试方法对所述第一舆情分析结果进行有效性验证,得到第一验证结果;
11、根据所述第一验证结果对所述第一舆情分析结果进行对应的修正。
12、可选地,所述预先训练好的第一神经网络是通过利用机器学习技术和深度神经网络,并结合语料库进行训练得到,以对所述文本数据进行文本分类,从而分析出与不同的舆情类别相关的第一相关信息。
13、可选地,所述利用预设的自然语言逻辑推理模型对所述第一相关信息进行结构分析,得到各主题词的第一关系数据的步骤,包括:
14、所述预设的自然语言逻辑推理模型利用自然语言处理技术,识别所述第一相关信息中的所述各主题词以对所述话题数据进行统计分析,从而获得准确的舆情分析结论。
15、可选地,所述根据预设的触发规则,获取与特定话题相关的话题数据的步骤,包括:
16、从所述预设的触发规则中提取所述特定话题的关联数据并从所述关联数据中提取关联词;
17、基于词向量技术进行语义相似度分析以获取与所述关联词的词向量相似的衍生关联词;
18、根据所述关联词和所述衍生关联词获取相关的文本、音频、图像和视频作为所述话题数据。
19、可选地,所述对所述话题数据进行识别、格式转换后从中提取文本数据的步骤,包括:
20、识别出所述音频中的第一语音数据和第一声调数据,并通过语音识别算法和语义识别算法得到音频描述文本数据;
21、识别出所述图像中的第一文字数据、第一人脸表情数据和第一表情符号数据,结合表情识别算法得到图像描述文本数据;
22、识别出所述视频中的第二语音数据、第二声调数据、第二文字数据、第二人脸表情数据和第二表情符号数据,结合语音识别算法、语义识别算法和表情识别算法得到视频描述文本数据;
23、将所述文本、所述音频描述文本数据、所述图像描述文本数据和所述视频描述文本数据转换为统一的标准化格式得到初始文本数据;
24、从所述初始文本数据中提取所述文本数据。
25、可选地,所述将所述文本、所述音频描述文本数据、所述图像描述文本数据和所述视频描述文本数据转换为统一的标准化格式得到初始文本数据的步骤,包括:
26、利用分词模型、表情符号识别模型和停用词识别模型对所述文本、所述音频描述文本数据、所述图像描述文本数据和所述视频描述文本数据进行分词、表情符号识别以及去除无意义符号、停用词的操作,得到待处理文本数据;
27、对所述待处理文本数据进行标准化处理得到所述初始文本数据。
28、可选地,所述根据预设的触发规则,获取与特定话题相关的话题数据的步骤之后,还包括:
29、获取所述话题数据对应的网络地址、用户账号和用户身份特征信息以生成所述话题数据对应的唯一的来源标识。
30、可选地,所述对所述待处理文本数据进行标准化处理得到所述初始文本数据的步骤包括:
31、根据所述来源标识对所述待处理文本数据进行分组,得到分组后的多个文本数据小组;
32、对所述多个文本数据小组按原始产生时间、语种、地域和来源人信息各个维度进行分类得到多个文本数据群组;
33、对所述多个文本数据群组进行标准化处理得到所述初始文本数据。
34、可选地,所述对所述待处理文本数据进行标准化处理得到所述初始文本数据的步骤包括:
35、对所述多个文本数据小组中的任意一个第一文本数据小组,将所述第一文本数据小组的分词后的第一个单独词作为基准词;
36、建立分词后每个单独词的描述结构,具体是:
37、创建描述结构文件;
38、获取所述每个单独词的起始字、中间字、结束字、与所述基准词的间隔距离以及出现次数,并将其记录至所述描述结构文件中;
39、重复上述步骤,直至迭代完所有的所述多个文本数据小组。
40、可选地,所述对所述待处理文本数据进行标准化处理得到所述初始文本数据的步骤包括:
41、对于每一个所述第一文本数据小组,根据所述出现次数和所述间隔距离对所有所述单独词进行统计分析,并以“‘单独词’、出现次数、间隔距离”构建出所述第一文本数据小组的特征结构数据。
42、采用本发明的技术方案,结合深度学习与语言逻辑推理的舆情分析方法包括:根据预设的触发规则,获取与特定话题相关的话题数据;对所述话题数据进行识别、格式转换后从中提取文本数据;利用预先训练好的第一神经网络对所述文本数据进行文本分类和词向量建模以提取出所述文本数据的第一相关信息;利用预设的自然语言逻辑推理模型对所述第一相关信息进行结构分析,得到各主题词的第一关系数据;利用预先训练好的关键词确定模型对所述第一关系数据进行处理,从而从所述各主题词中确定由多个第一关键词和所述多个第一关键词中各个第一关键词的第一属性数据组成的第一关键词集;利用训练好的情感分析模型对所述第一关键词集进行情感分类,获得第一情感分类数据;对所述第一情感分类数据进行分析,得到第一舆情分析结果;利用聚类分析、统计学分析和精准度测试方法对所述第一舆情分析结果进行有效性验证,得到第一验证结果;根据所述第一验证结果对所述第一舆情分析结果进行对应的修正。通过本发明的方案,利用深度学习技术和自然语言逻辑推理,可以准确地进行舆情分析。
- 还没有人留言评论。精彩留言会获得点赞!