基于多模态信息融合的动态目标识别方法
本发明涉及无人驾驶,尤其涉及一种基于多模态信息融合的动态目标识别方法。
背景技术:
1、近年来随着互联网企业、造车新势力以及传统车企纷纷投入自动驾驶市场,自动驾驶领域呈现出火热的势态。目标识别作为自动驾驶车辆感知系统中最重要的一环,其直接决定了自动驾驶车辆是否能够按预期安全运行,这就使得目标识别正成为计算机视觉最活跃的研究领域之一。
2、传统目标识别方法主要由以下几个步骤构成:首先在图像上用滑动窗口的方式产生候选框并提取候选框中图像对应的特征;随后用支持向量机等分类器对候选框进行分类;最后进行非极大值抑制,从而输出结果。这种方法由于依赖手工设计的特征而具有较差的泛化能力,同时滑动窗口全局搜索也导致时间复杂度较高。
3、为克服传统目标识别方法的上述缺陷,基于深度学习的识别方法应运而生。但无论哪种识别方法,皆使用完全独立的方式来处理个别的模态信号或使用相同的方式平等对待所有模态信号,这就导致目标识别结果失真,准确性较差。
技术实现思路
1、为克服现有目标识别准确性差的技术缺陷,本发明提供了一种基于多模态信息融合的动态目标识别方法。
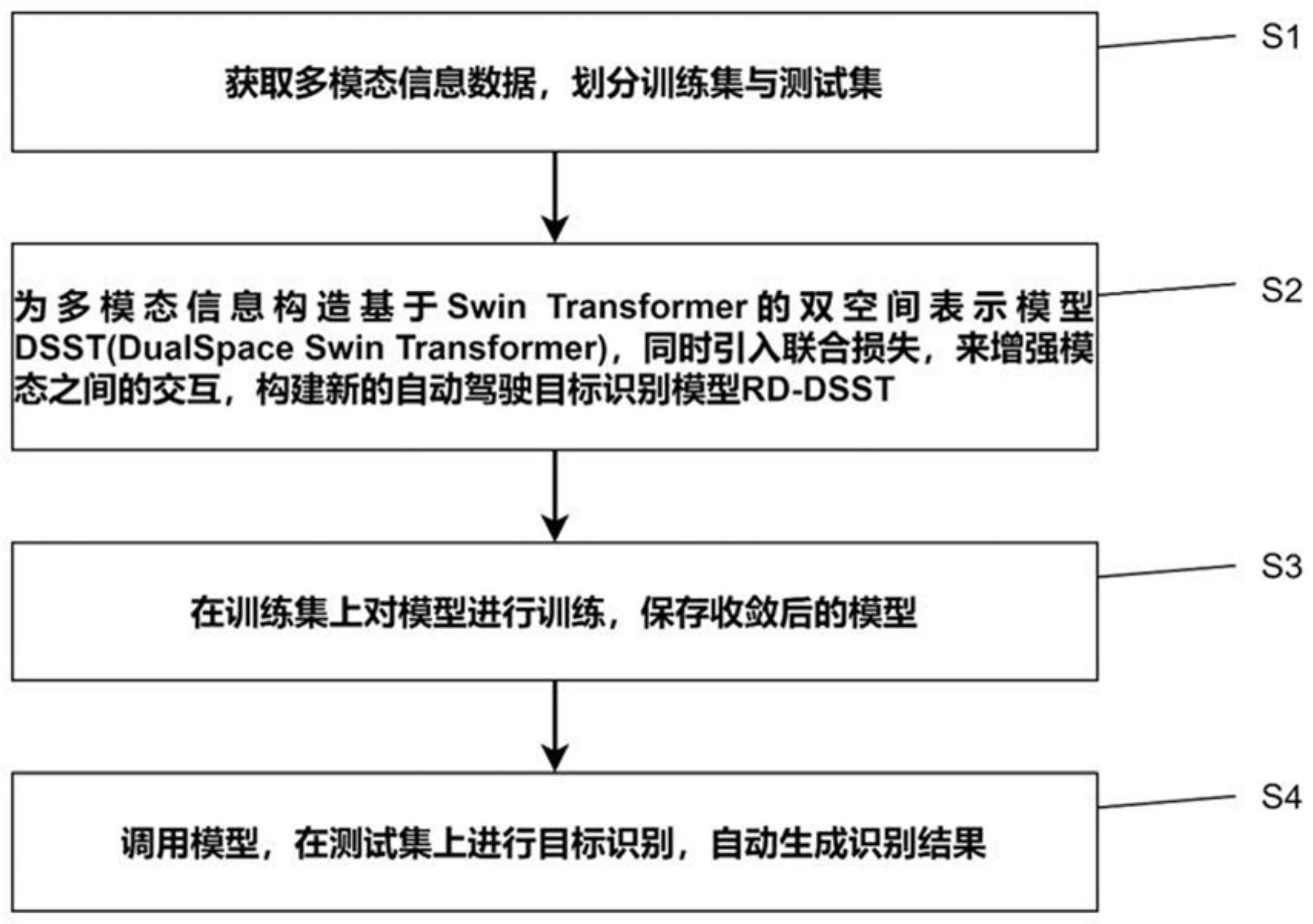
2、本发明提供了基于多模态信息融合的动态目标识别方法,包括如下步骤:
3、s1、获取多模态信息数据,划分训练集和测试集;
4、s2、为多模态信息数据构造基于swin transformer的双空间表示模型dsst,所述双空间表示模型dsst包括第一子空间和第二子空间,所述第一子空间模态不变,所述第二子空间模态特定,所述双空间表示模型dsst依次进行模态表示学习和模态融合;
5、s3、引入联合损失,构建自动驾驶目标识别模型rd-dsst;
6、s4、在所述训练集上对所述自动驾驶目标识别模型rd-dsst进行训练,保存收敛后的模型;
7、s5、调用步骤s4收敛后的模型,在所述测试集上进行目标识别,自动生成识别结果。
8、可选的,步骤s2分为如下分步骤:
9、s21、使用激光雷达传感器和可见光相机的视频数据作为语料,给定序列um∈{r,v},每个语料分别表示为和每个语料序列映射到一个固定大小的向量所述双空间表示模型dsst采取层次化的设计,逐层缩小输入特征图的分辨率从而扩大感受野,最终隐藏层状态表示加上一个全连接的密基层,得到所述第一子空间的隐藏模态不变性向量表示为所述第二子空间的模态特定向量表示为和用过编码函数实现:
10、
11、
12、则雷达传感器的隐藏模态不变性向量和模态特定向量如下:
13、
14、
15、视频数据隐藏模态不变性向量和模态特定向量如下:
16、
17、
18、s22、得到上述四个向量和后,将这些模态投射到各自的表示中,并且融合成一个联合向量。
19、可选的,步骤s22包括如下分步骤:
20、s221、基于transformer,利用注意力模块,对上述四个向量和进行串联,其被定义为的缩放函数如下所示:
21、
22、其中,q、k和v是查询矩阵、键矩阵和值矩阵,transformer计算多个这样的并行注意力,其中每个注意力的输出被称为头,第i头的计算方法如下所示:
23、headi=attention(qwiq,kwik,vwiv)
24、其中,wiq,wik和wiv是针对头的参数,用于将矩阵线性地投射到局部空间;
25、s222、将模态表示为矩阵堆叠而成,对于注意力机制,设定transformer生成一个新的矩阵最后利用transformer的输出,用拼接法构建一个联合向量任务预测通过生成函数
26、可选的,步骤s3包括如下分步骤:
27、s31、基于可见光相机的视频数据中的rgb和depth两种模态,构建损失函数:
28、
29、其中,wj表示单一模态学习的矩阵权重,wj表示联合学习的权重矩阵,yi表示样本;
30、s32、使用rgb的fc1024特征和depth的fc1024特征分别计算rgb-rgb的匹配得分值和depth-depth的匹配得分值,之后通过加权融合得到最后得分:
31、
32、其中p1和p2是每种模式单独观察到的视频数据的匹配精度。
33、可选的,步骤s5中,基于准确率和召回率自动识别结果,所述准确率是指对于某种类型检测结果中正确的数量占所有检测结果数量的比例,所述召回率是指对于某种检测结果正确的正样本数量占测试集中所有正样本数量的比例,所述准确率所述召回率其中,t和f分别表示检测结果正确和错误,p和n分别表示真值是正样本和负样本,tp表示检测结果为正样本,真值也为正样本;fp表示检测结果为正样本,真值为负样本;tn表示检测结果为负样本,真值也为负样本;fn表示检测结果为负样本,真值为正样本。
34、可选的,通过平均精度来综合准确率和召回率,所述平均精度表示某一类别在不同召回率下的准确率的平均值,所述平均精度其中,在[0-1]范围内将召回率按照等间隔取值,ri表示第i个召回率,n表示召回率的取值总数,p(ri)表示第i个召回率下的准确率。
35、可选的,对于不同类别的目标,需要计算平均精度均值,所述平均精度均值是所有类别的平均精度的平均值,所述平均精度均值其中,ap(j)表示第j个类别目标的平均精度,m表示类别总数。
36、可选的,采用f1-measure作为评价指标之一,
37、本发明提供的技术方案与现有技术相比具有如下优点:
38、本发明提供的基于多模态信息融合的动态目标识别方法,为多模态信息数据构造了双空间表示模型dsst,第一个子空间是模态不变的,跨模态的表示学习它们的共性,缩小模式差距;第二子空间是特定于模态的,对每种模态都是私有的,保证了它们的特征。如此,有效地解决了不同信号的异构性造成的分布式模态差距。另外,本方法引入联合损失,来增强模态之间的交互,充分考虑了模态差异并利用模态相关性,进而提出rd-dsst模型,能够学习多个不同模式之间的共同特征。基于上述优势,本方法能够直观地展示识别结果,并保证识别结果的准确率,使识别更加快捷高效,大大提高了自动驾驶领域目标识别的可操作性,提高了工作效率。
技术特征:
1.一种基于多模态信息融合的动态目标识别方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的基于多模态信息融合的动态目标识别方法,其特征在于,步骤s2分为如下分步骤:
3.根据权利要求2所述的基于多模态信息融合的动态目标识别方法,其特征在于,步骤s22包括如下分步骤:
4.根据权利要求3所述的基于多模态信息融合的动态目标识别方法,其特征在于,步骤s3包括如下分步骤:
5.根据权利要求4所述的基于多模态信息融合的动态目标识别方法,其特征在于,步骤s5中,基于准确率和召回率自动识别结果,所述准确率是指对于某种类型检测结果中正确的数量占所有检测结果数量的比例,所述召回率是指对于某种检测结果正确的正样本数量占测试集中所有正样本数量的比例,所述准确率所述召回率其中,t和f分别表示检测结果正确和错误,p和n分别表示真值是正样本和负样本,tp表示检测结果为正样本,真值也为正样本;fp表示检测结果为正样本,真值为负样本;tn表示检测结果为负样本,真值也为负样本;fn表示检测结果为负样本,真值为正样本。
6.根据权利要求5所述的基于多模态信息融合的动态目标识别方法,其特征在于,通过平均精度来综合准确率和召回率,所述平均精度表示某一类别在不同召回率下的准确率的平均值,所述平均精度其中,在[0-1]范围内将召回率按照等间隔取值,ri表示第i个召回率,n表示召回率的取值总数,p(ri)表示第i个召回率下的准确率。
7.根据权利要求6所述的基于多模态信息融合的动态目标识别方法,其特征在于,对于不同类别的目标,需要计算平均精度均值,所述平均精度均值是所有类别的平均精度的平均值,所述平均精度均值其中,ap(j)表示第j个类别目标的平均精度,m表示类别总数。
8.根据权利要求6所述的基于多模态信息融合的动态目标识别方法,其特征在于,采用f1-measure作为评价指标之一,
技术总结
本发明涉及无人驾驶技术领域,具体涉及一种基于多模态信息融合的动态目标识别方法,包括:S1、获取多模态信息数据,划分训练集和测试集;S2、为多模态信息数据构造基于Swin Transformer的双空间表示模型DSST,双空间表示模型DSST依次进行模态表示学习和模态融合;S3、引入联合损失,构建自动驾驶目标识别模型RD‑DSST;S4、在训练集上对自动驾驶目标识别模型RD‑DSST进行训练,保存收敛后的模型;S5、调用步骤S4收敛后的模型,在测试集上进行目标识别,自动生成识别结果。本发明提供的动态目标识别方法,既能减少不同信号的异构性造成的分布式模态差距,又能充分考虑模态差异并利用模态相关性,为无人驾驶的决策规划和控制提供可靠保证。
技术研发人员:张喆,桑艺昱,续欣莹,冯州
受保护的技术使用者:太原理工大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!