融合激活扩散理论和艾宾浩斯遗忘理论的新闻推荐方法
本发明涉及数据分析与挖掘和深度学习,尤其是涉及一种利用了激活扩散理论和艾宾浩斯遗忘理论的基于知识图谱的新闻推荐方法。
背景技术:
1、推荐系统涉及到多个领域的交叉研究,是数据分析与挖掘、信息检索领域最重要的应用之一,推荐系统通常由三部分组成,即用户模型、物品模型和推荐算法,而推荐算法毫无疑问是其中的核心问题。根据推荐算法的不同,其大类可分为传统的基于机器学习的推荐系统和基于深度学习的推荐系统。
2、对于传统的推荐系统,可以分为基于内容的推荐、基于协同过滤的推荐和基于混合的推荐。基于内容的推荐通过用户的画像和物品的特征,从用户已经产生过交互的项目中获得用户的偏好,再将用户的偏好和项目内容特征进行匹配,最后为用户提供与偏好相似的推荐结果。基于协同过滤的推荐通过选择协同过滤算法来挖掘目标用户的历史数据记录从而预测用户对未交互的项目的感兴趣程度或者通过计算目标项目间的相似度,找到候选项目的邻居项目集合,并向目标用户推荐预测评分较高且无交互记录的项目。基于混合的推荐则是融合上述算法,在不同的领域进行组合。
3、根据选用的深度学习模型的不同,基于深度学习的推荐系统也有多种分类,其中基于知识图谱结合神经网络的推荐方法凭借知识图谱的结构特性,能够将用户历史记录和推荐过程连接起来,并且各种类型的项目所包含的语义关系都可以反映在知识图谱中,因此此类方法已经广泛地应用于各大通用及垂直领域的推荐系统中。根据思想的不同,主要可以分为三种,其一是基于连接的推荐,主要利用知识图谱的异构网络的特点,通过网络中边的不同关系来计算节点之间的相似度、挖掘用户的兴趣,进而完成推荐。其二是基于嵌入的推荐,主要对图谱中的实体和关系进行一个低维向量的映射,通过图嵌入的方法对实体和关系进行表征,进而扩充原有物品和用户表征的语义信息。其三是基于混合的推荐,在整个图谱上获取用户的兴趣,并通过图嵌入模块对用户的兴趣进行特征学习。
4、综上,当前基于知识图谱的推荐方法,主要解决推荐过程中由于语义信息不充分,无法捕捉用户的兴趣演进过程,使得推荐系统存在推荐不准确的问题。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种基于知识图谱的融合激活扩散理论和艾宾浩斯遗忘理论的新闻推荐方法。
2、本发明的目的可以通过以下技术方案来实现:
3、一种融合激活扩散理论和艾宾浩斯遗忘理论的新闻推荐方法,所述新闻推荐方法包括以下步骤:
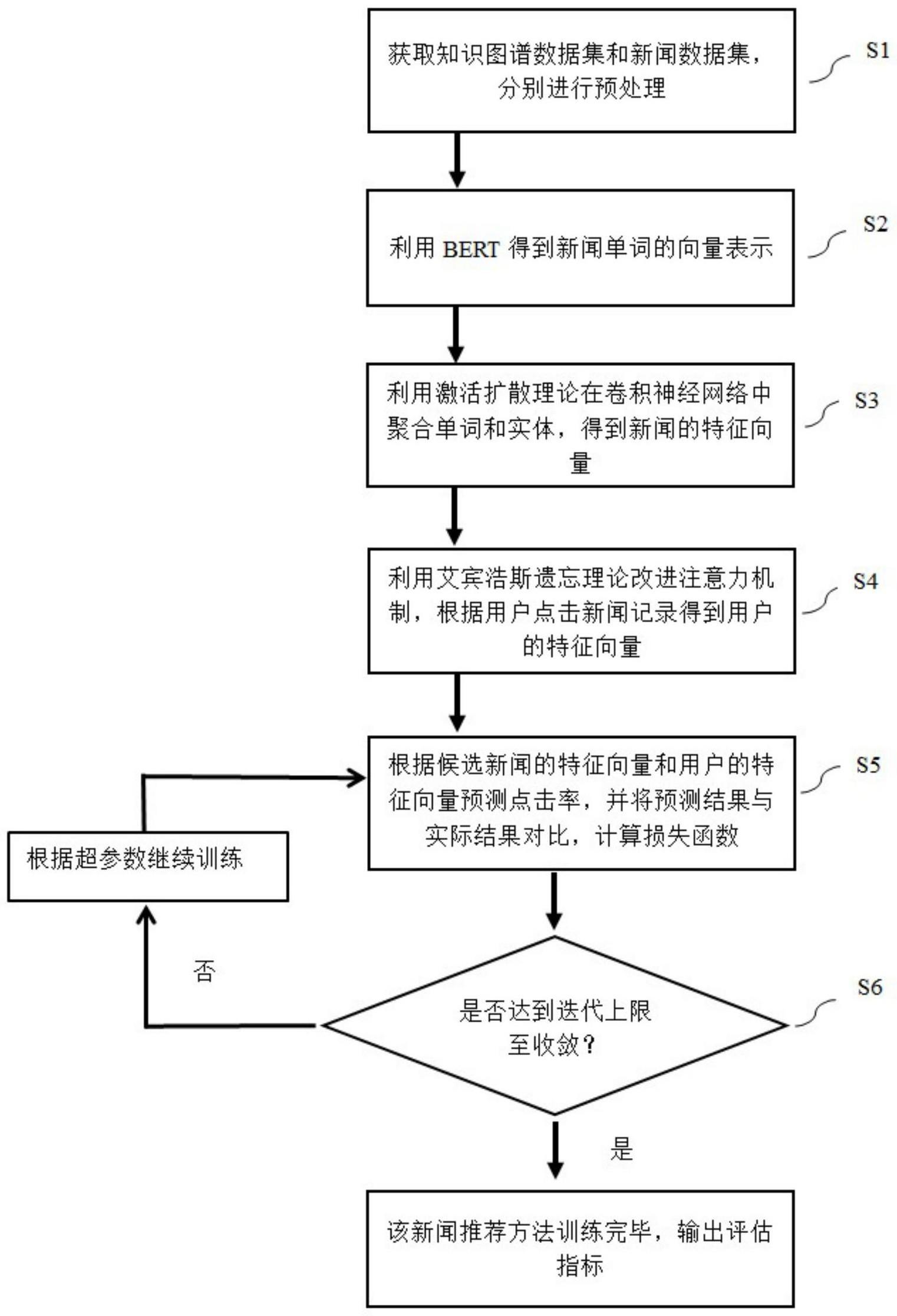
4、获取知识图谱数据集和新闻数据集,并对知识图谱和新闻数据集中的数据进行预处理;
5、获取新闻单词的向量表示;
6、利用激活扩散理论在卷积神经网络cnn里聚合单词与实体向量,得到新闻的特征向量;
7、利用艾宾浩斯遗忘理论改进注意力机制,根据用户点击新闻记录得到用户的特征向量;
8、根据候选新闻的特征向量和用户的特征向量,预测点击率并进行新闻推荐。
9、进一步的,所述获取知识图谱和新闻推荐的数据集,并对知识图谱和新闻数据集中的数据进行预处理过程如下:
10、知识图谱预处理:获取知识图谱数据集,实体ei利用transd知识图谱表示学习算法训练后,得到实体特征向量
11、新闻数据集预处理:将用户点击的新闻记录逐条统一处理为:用户id、采样时间、具体新闻标题、实际点击情况。
12、进一步的,所述获取新闻单词的向量表示,其过程如下:
13、对于一条新闻中出现的单词wi使用bert完成向量化表示,得到的单词的特征向量再将所有单词的特征向量拼成单词的特征向量矩阵
14、其中,m为词向量维度,表示w1的词向量,表示矩阵,n为单词总数。
15、进一步的,所述实体向量的获得过程如下:
16、计算语义距离:定位新闻单词在知识图谱中对应的实体,根据激活扩散理论,计算实体与其n阶邻居节点的语义关联距离,构建该实体的上下文邻居节点集合;
17、表示上下文向量:将根据激活扩散得到的实体ei的上下文邻居节点集合的特征向量表示为将新闻中所有单词所对应的实体的上下文向量拼接成上下文特征向量矩阵
18、其中,neighbor(ei)表示实体ei的全部经过激活扩散后的邻居节点集合,l为当前实体的邻居总数,为知识图谱中实体el经过transd图嵌入训练后的实体特征向量,表示矩阵,n为单词总数,m为向量维度,如果单词在知识图谱中没有对应的实体,取0。
19、进一步的,所述计算语义距离,其过程如下:
20、将实体的一阶邻居作为初始上下文集合,并在一阶邻居节点的基础上向外扩散2阶邻居,将扩散过程中语义关联距离更小的新节点代替原一阶邻居,更新该实体的上下文集合,不断迭代此过程,如果没有语义关联距离更小的新节点,那么停止扩散,语义关联距离的计算公式为:
21、
22、其中,tik和tjk分别是实体ei和ej的向量在第k维的取值,和是实体ei和ej的向量的平均值,m为向量维度。
23、进一步的,所述在卷积神经网络cnn里聚合单词与实体向量,得到新闻的特征向量,其过程如下:
24、将得到的n×m维单词的特征向量矩阵hw和n×m维实体的上下文特征向量矩阵hc堆叠成n×m×2维的向量矩阵,作为输入r:
25、
26、其中,表示w1的词向量,表示实体e1的上下文邻居节点集合的特征向量;
27、在卷积层使用多个长度为l的滑动窗口,其步长设置为1,卷积核的初始权重矩阵为卷积核权重矩阵在子矩阵ri:i+l-1上以步长移动滑动窗口,卷积核的数量为k,子矩阵关于卷积核的局部相应的特征向量ci计算公式为:
28、ci=[h*ri:i+l-1+b]
29、其中,b为偏置矩阵,所有的ci组合成了由一个卷积核卷积得到的特征矩阵,将relu函数作为激活函数;
30、在池化层对矩阵进行特征降维,获得固定大小的向量,使用最大池化筛选得到特征向量ct;
31、在输出层将经过最大池化得到的特征向量ct拼接起来,可以得到固定长度的新闻特征向量t(c)的最终表示。
32、进一步的,所述利用艾宾浩斯遗忘理论改进注意力机制,根据历史新闻记录得到用户的特征向量表示,其过程如下:
33、通过艾宾浩斯遗忘曲线组成遗忘矩阵:基于艾宾浩斯遗忘曲线得到公式为:
34、f(x)=e(x-1)[0.0123×1n(x-1)]-0.0639
35、其中,x表示最近的第x次点击,f(x)表示记忆保持比率;
36、根据用户实际点击新闻次数,得到每次点击的记忆保持比率,并归一化为遗忘矩阵:
37、
38、其中,为f(x)经过softmax归一化后的记忆保持比率,将其作为遗忘权重,m为用户实际点击新闻次数;
39、改进注意力机制:将候选新闻ck和用户u的历史新闻记录通过内积并归一化后得到注意力权重系数,具体公式为:
40、
41、其中,方法ρ代表接收两个特性向量作为输入,沿着指定维度进行内积并求和的操作,和t(ck)表示用户记录和候选新闻ck向量表示;
42、将对应的权重相加并进行softmax归一化得到用户u的历史记录所对应向量的最终权重点数
43、计算用户向量:将最终权重点数与用户点击过的新闻向量相乘并叠加得到用户的向量表示t(u)。
44、进一步的,所述点击率预测为:根据所得到的用户向量t(u)和候选新闻向量t(ck)做点击率预测,计算公式为:
45、
46、其中,方法p为tensorflow库中的reduce_sum函数和矩阵内积操作的结合,通过接收两个特性向量作为输入,沿着指定维度进行内积并求和。
47、进一步的,所述新闻推荐方法的训练过程具体如下:
48、设置迭代上限η,输入数据集对所述新闻推荐方法进行训练;
49、将新闻推荐预测结果与实际结果对比,计算损失函数;
50、若达到迭代上限至收敛,则训练完毕,对于全部点击率预测情况与真实点击情况进行准确性评估并输出结果;否则根据超参数继续训练。
51、进一步的,所述计算损失函数计算具体如下:
52、根据实际结果和预测结果p,通过使用tensorflow库中的交叉熵函数和l2正则化计算损失,并用tensorflow库中的adam optimizer进行优化。
53、与现有技术相比,本发明具有以下有益效果:
54、本发明所述方法与其他新闻推荐方法相比,通过激活扩散理论获得新闻的特征向量,能够充分地利用知识图谱中的上下文信息,通过艾宾浩斯遗忘理论获得用户的特征向量,能够精确地挖掘用户和候选新闻的关系,从而提高推荐的准确性。
- 还没有人留言评论。精彩留言会获得点赞!