一种基于大数据的地址分级及补齐的地址标准化方法与流程
本发明涉及大数据地址标准化信息处理,具体涉及一种基于大数据的地址分级及补齐的地址标准化方法。
背景技术:
1、进入信息时代以来,中国的互联网规模稳步攀升,现阶段互联网产生的数据信息也急速增长,面对数量巨大的互联网数据信息,应该最大限度地发挥海量数据的价值,特别是一些新型网上消费的模式并且需要依托地址进行的网购跑腿等服务业务的数据占有很大一部分比重,对于这些数据,可以通过其中的地址,对不同数据源中的数据进行关联,从而形成一个系统的信息网络,对于社会发展产生积极的作用。
2、然而现有的地址在标准制定上没有一个完善的体系,很多地址由于地址名字经过口语化翻译过来,在地址分级上存在困难,还有的地址存在记录偏差,也导致了地址标准化划分存在很大阻力,为了解决地址标准化缺失的问题,一些设计者也开始针对采集和地址录入质量进行研究,通过设计一些标准化方法来补齐地址缺失等问题,主要通过针对用户地址字段残缺、重复、混乱进行分析处理,系统自动将不统一、缺漏、错误的地址加以整理、规范、补全,矫正,并且通过地址查重后整理归一,形成规整有效的地址数据。
3、现有的针对地址匹配问题,通过双数组trie树进行多层级地址匹配,虽然在传统地址匹配方法上做出改进,一定程度提升了地址匹配效率;针对地址分词等地址处理方向,通过将apache lucene搜索引擎引入到地址匹配工作当中,一定程度上减少了地址匹配对于地址标准库的依赖,构建地址分级模型进行地址标准化,同时还构建了地址标准库,但目前这种方法对于缺少地址级别要素的地址匹配率非常低;以上都缺少保证地址匹配与地址分词统一化的标准化方法,会导致地址分词效果差,匹配成功率低等问题。
技术实现思路
1、本发明的目的在于提供一种基于大数据的地址分级及补齐的地址标准化方法,解决以下技术问题:
2、(1)怎样保证地址分级的准确性同时提高地址匹配率,进而实现大数据背景下的地址的准确分级和标准库的及时更新。
3、本发明的目的可以通过以下技术方案实现:
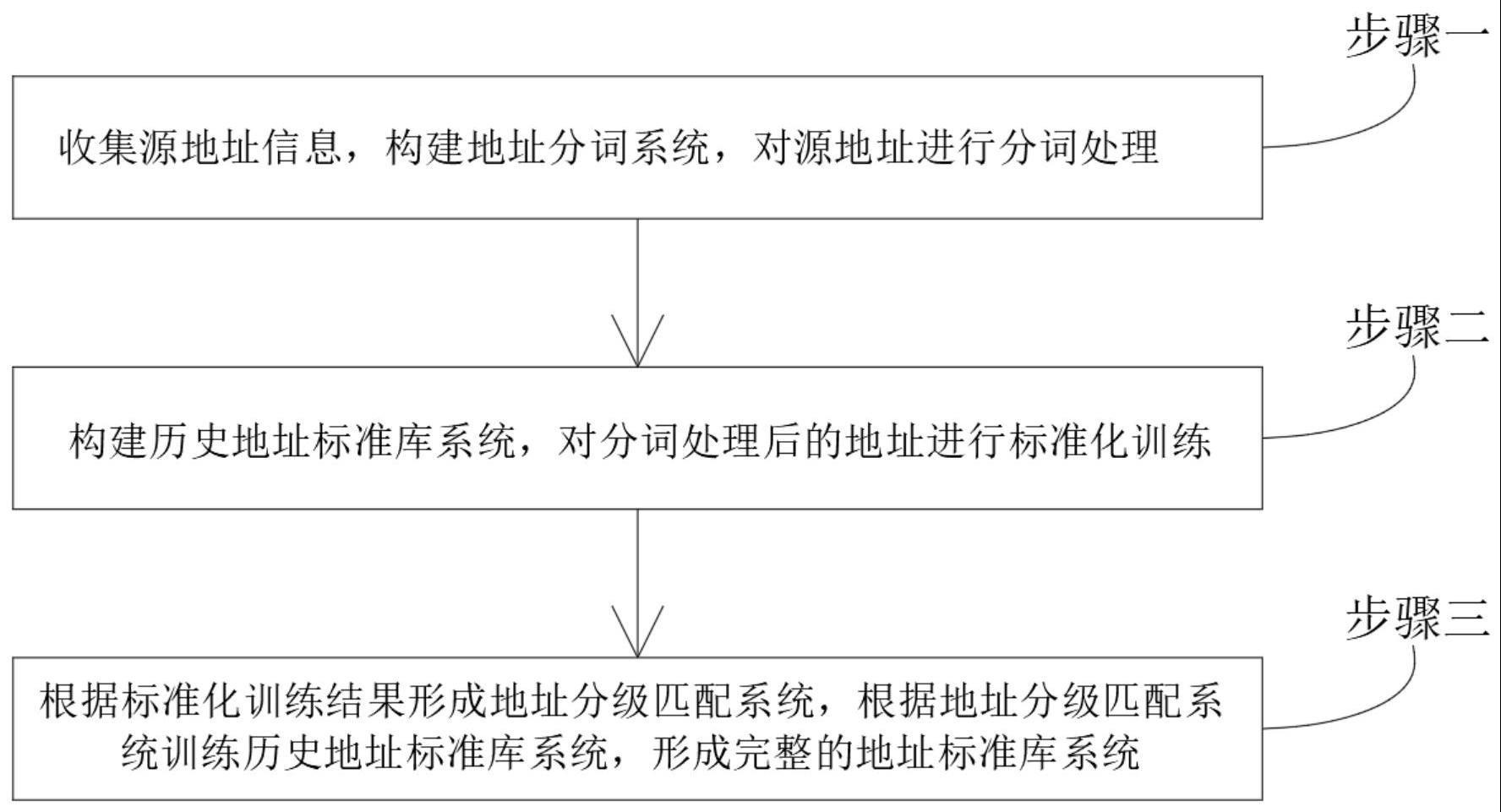
4、一种基于大数据的地址分级及补齐的地址标准化方法,包括:
5、步骤一、收集源地址信息,构建地址分词系统,对源地址进行分词处理;
6、步骤二、构建历史地址标准库系统,对分词处理后的地址进行标准化训练;
7、步骤三、根据标准化训练结果形成地址分级匹配系统,根据地址分级匹配系统训练历史地址标准库系统,形成完整的地址标准库系统。
8、进一步地,所述步骤一中所述地址分词系统的构建方法包括:
9、s1、获取源地址数据信息,根据源地址数据信息进行分词模型训练,形成最佳分词模型;
10、s2、将分词训练后的地址通过最佳分词模型进行地址预处理;
11、s3、输出地址分词结果。
12、进一步地,所述步骤二中所述历史地址标准库系统的构建过程包括:
13、ss1、根据历史标准化地址,通过将分词后的地址进行筛选和纠偏处理;
14、ss2、根据所述地址分级匹配系统对纠偏处理后的地址执行地址融合策略;
15、ss3、补充地址标准库系统。
16、进一步地,所述筛选和纠偏处理内容包括:
17、删除地址中无法进行准确地址定位的主要地址字符;
18、删除分词预处理过程中未筛选出的噪声地址。
19、进一步地,所述地址融合策略获得的方式为:
20、ss21、根据地理信息分类,按照地址范围从大到小对地址进行级别划分,依次分成a级别、b级别、c级别及其他级别,根据a级别和b级别字符串组合的方式进行分组,将分组中地址数量fi与阈值fith进行比对,将分组中地址数量小于阈值的组删除;
21、ss22、根据融合效果选择两个级别进行分组;
22、ss23、通过分布式搜索引擎对选取的两个级别有值情况进行判断,对情况不同的地址分别处理,与标准级别地址字符项匹配并合并所有地址;
23、其中,所述阈值fith是根据数据源获取的。
24、进一步地,所述地址预处理的方法包括:
25、采用正则表达式对数据源中的噪声数据进行去噪处理,所述去噪处理包括通过对源地址进行去重处理,根据数据来源情况对地址字母错误、乱码、空格及错误符号进行删除和统一处理。
26、进一步地,所述步骤三中地址分级匹配系统的形成过程包括:
27、sss1、根据历史地址标准库将已分词后的地址进行地址匹配,获得地址样本;
28、sss2、将匹配后的地址样本进行逆向分级处理;
29、sss3、将逆向分级处理后的地址样本进行标准化训练。
30、进一步地,所述步骤sss2中的逆向分级处理的方法为:
31、a.设定级别关键词,输入已分词地址进行逆向匹配,判断分词地址标准化程度;
32、b.将分级后的地址与源地址级别进行比对,匹配对应地址,输出标准化地址信息。
33、进一步地,所述源地址信息的收集方法为:通过gps定位系统结合3d影像获取地址地理信息,转化地理信息字符信息并转入地址库中储存。
34、本发明的有益效果:
35、(1)本发明通过收集源地址信息,构建地址分词系统,从而提高历史地址标准库中的地址分词准确度;通过构建历史地址标准库系统,采用预训练模型对分词后的地址进行标准化训练,更新了历史地址标准库系统的分词模型,在构建更新后的地址标准库之前对分词后的地址进行处理,保证了地址标准库的简洁性和正确性,最后根据标准化训练结构形成地址分级匹配系统,根据地址分级匹配系统训练历史地址标准库系统,形成完整的地址标准库系统;
36、(2)本发明通过将地址分词与地址分级匹配结合训练地址标准库,实现地址标准库的更新和完善,具体通过获取源地址信息中的级别信息数据,通过分词模型对不同级别地址进行打标处理,训练地址形成最佳分词模型,将经过分词处理后的地址信息通过最佳分词模型进行预处理可以更好的输出标准化地址信息,通过将输出的分次结果输入到历史地址标准库系统中进行筛选,筛选新的地址类型,分词梳理可以筛选出异常地址,提高了地址标准化程度。
37、(3)本发明通过将历史地址标准库中分词处理后的地址进行地址匹配,获得地址样本信息,对匹配后的地址样本信息进行逆向分级处理,这里逆向分级为根据地理范围从小到大的地址分级,与传统正向分级相比进行了优化,保证了缩小地址匹配范围,且匹配准确性较好,通过精确匹配处理后的数据输入历史地址标准库中进行训练,最终得到完善后的标准地址库。
38、当然,实施本发明的任一产品并不一定需要同时达到以上所述的所有优点。
技术特征:
1.一种基于大数据的地址分级及补齐的地址标准化方法,其特征在于,包括:
2.根据权利要求1所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述步骤一中所述地址分词系统的构建方法包括:
3.根据权利要求1所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述步骤二中所述历史地址标准库系统的构建过程包括:
4.根据权利要求3所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述筛选和纠偏处理内容包括:
5.根据权利要求3所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述地址融合策略获得的方式为:
6.根据权利要求2所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述地址预处理的方法包括:
7.根据权利要求1所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述步骤三中地址分级匹配系统的形成过程包括:
8.根据权利要求7所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述步骤sss2中的逆向分级处理的方法为:
9.根据权利要求1所述的基于大数据的地址分级及补齐的地址标准化方法,其特征在于,所述源地址信息的收集方法为:通过gps定位系统结合3d影像获取地址地理信息,转化地理信息字符信息并转入地址库中储存。
技术总结
本发明涉及大数据地址标准化信息处理技术领域,具体公开了一种基于大数据的地址分级及补齐的地址标准化方法,包括:步骤一、收集源地址信息,构建地址分词系统,对源地址进行分词处理;步骤二、构建历史地址标准库系统,对分词处理后的地址进行标准化训练;步骤三、根据标准化训练结果形成地址分级匹配系统,根据地址分级匹配系统训练历史地址标准库系统,形成完整的地址标准库系统;本发明通过构建地址分词系统,优化模型分词能力,通过构建地址标准库系统,经过分词训练后形成分级匹配系统,提高了地址标准化的匹配准确率,实现大数据背景下的地址的准确分级和标准库的及时更新。
技术研发人员:李维,刘生元,杨超,汤永喜
受保护的技术使用者:南京华控创为信息技术有限公司
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!