场景文本识别方法、系统、存储介质及计算设备与流程
本发明涉及文本识别的,尤其是指一种基于知识蒸馏的场景文本识别方法、系统、存储介质及计算设备。
背景技术:
1、文字是信息的主要载体之一,对信息传播和交互具有重要意义。随着互联网技术的蓬勃发展,智能手机、平板电脑、数码相机等移动设备得到广泛应用。大量的场景图像,涌现在人们生活的方方面面。使用自动化的方式识别图像中的文本,提取内含的信息,可以服务于人类活动的方方面面,提高生活的质量和生产的效率。因此场景文本的识别作为计算机视觉领域的子课题,逐渐成为一大研究热点,被广泛应用于机器视觉、图像搜索、无人驾驶、自动翻译等领域。
2、不同于传统的扫描图像文本的背景单一、文本规则,场景文本中的文本因表现形式丰富,图像背景复杂,以及图像拍摄引入的干扰因素等的影响,使得对其的分析与处理难度远高于传统的扫描文档图像。近年来,随着深度学习技术的快速发展,国内外学者针对各种问题和挑战,在场景文本识别任务中尝试提出了相应的解决方案,极大地促进了场景文本识别技术的发展,但由于场景文字的复杂性与多样性和识别模型的庞大,在识别精度与轻量级模型部署方面仍具有挑战性。因此,如何进一步提高场景文本的识别精度与如何构建轻量级识别模型,非常有理论和实际意义。
技术实现思路
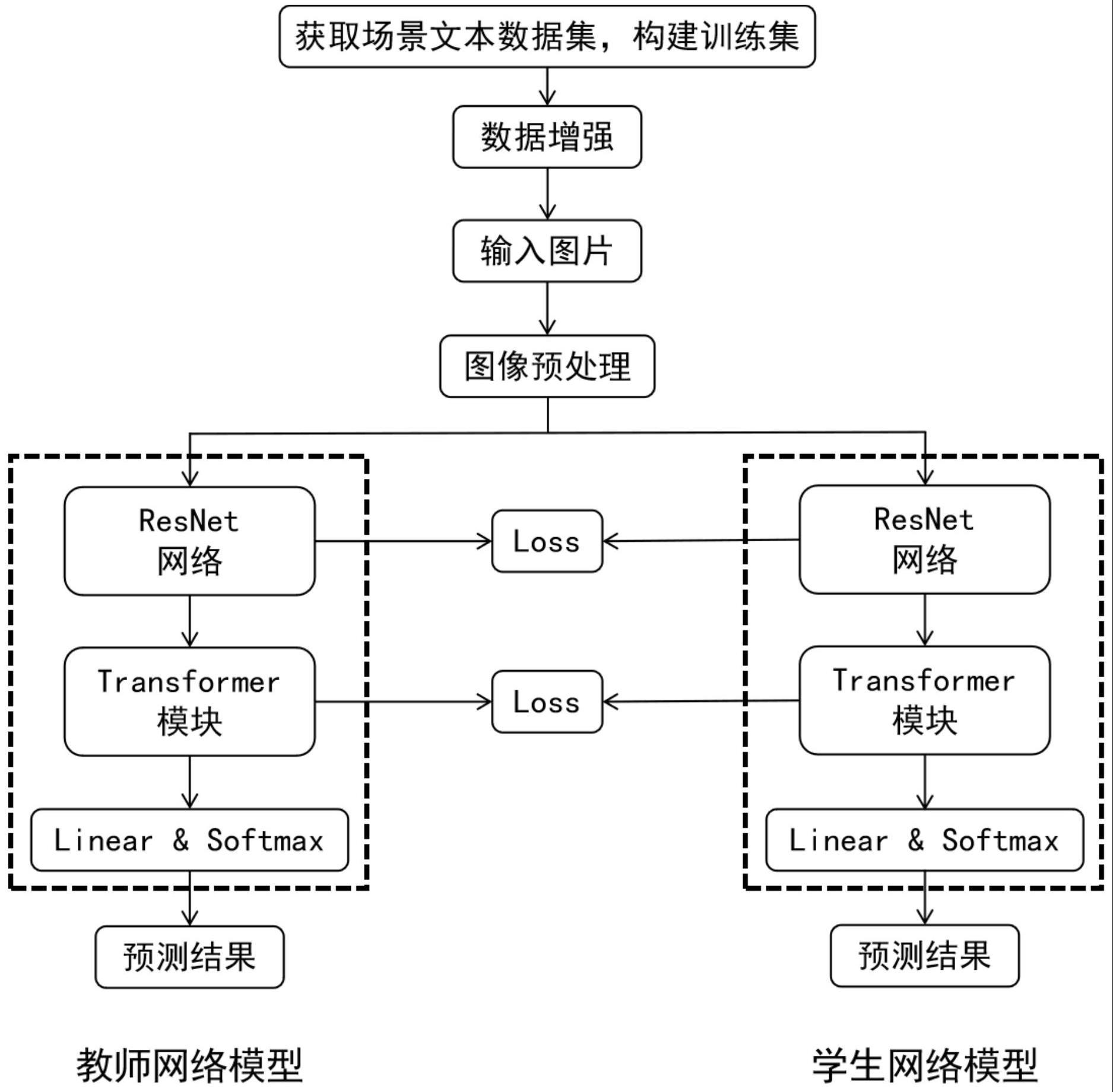
1、本发明的第一目的在于克服现有技术的缺点与不足,提出了一种基于知识蒸馏的场景文本识别方法,主要利用resnet架构来提取场景文本图像中的特征,利用transformer模块来防止长距离特征建模时的信息损失,提高场景文本识别的精确度,利用知识蒸馏的在保证识别准确率的情况下使得模型更轻量化,以便于在小型设备端的部署。
2、本发明的第二目的在于提供一种基于知识蒸馏的场景文本识别系统。
3、本发明的第三目的在于提供一种存储介质。
4、本发明的第四目的在于提供一种计算设备。
5、本发明的第一目的通过下述技术方案实现:基于知识蒸馏的场景文本识别方法,包括以下步骤:
6、1)获取场景文本数据集,对数据集中的图片进行数据增强处理,作为场景文本训练集;
7、2)构建基于注意力机制的场景文本识别模型,用于场景文本识别,该场景文本识别模型以大参数量的复杂网络模型作为教师网络模型,以参数量少的轻量级作为学生网络模型,为了在文本特征的序列建模中学习不同文本间的长距离依赖关系,该模型使用transformer模块来实现注意力机制;
8、3)将场景文本训练集中的图片输入到步骤2)构建的场景文本识别模型中进行模型训练,在训练过程中将参数量大的教师网络模型的知识迁移到参数量少的学生网络模型上,实现知识蒸馏;其中,对于特征提取部分,采用中间层特征蒸馏的方式监督学生网络模型的训练;对于序列建模部分,利用教师网络模型中的相似度矩阵和前馈网络的输出作为监督信号,训练学生网络模型;
9、4)保存训练完成的场景文本识别模型作为最优模型,后续将待测数据输入该最优模型中,即可得到精准的场景文本识别结果。
10、进一步,在步骤1)中,将获取到的数据集进行图片增强处理,根据场景文本图片的采集极易受到外界光照及噪声的影响,对场景文本训练集中的图片进行数据增强,包括随机对场景文本训练集中的图片进行亮度调整、对比度调整和饱和度调整,随机对场景文本训练集中的图片进行旋转,随机添加高斯噪声来扩充数据量,提高模型的泛化能力。
11、进一步,在步骤2)中,基于注意力机制的场景文本识别模型使用resnet架构与transformer模块实现,transformer模块分为三部分:位置编码、多头注意力模块和前馈网络;其中,多头注意力模块和前馈网络能够堆叠多层,以得到更加丰富的全局信息;输入场景文本图片经过resnet网络提取得到的特征输入到transformer模块中,首先经过位置编码标示不同时间单元的位置,然后多头注意力模块对编码后的特征并行地建模全局的依赖关系,最后经过前馈网络和线性层得到最终的输出;多头注意力模块由8个单头注意力模块组成,每个单头注意力模块有四个输入,分别是q、k、v、m,q代表查询矩阵,k与v分别代表键值,m代表注意力掩码矩阵,其中的每个查询向量qi∈q先与所有的键向量ki∈k进行相似度计算,得到相似度矩阵,并加入注意力掩码矩阵;然后利用softmax函数对相似度矩阵进行归一化;最后,将相似度矩阵与v进行加权求和,得到当前查询向量的注意力结果,单头注意力模块计算公式如公式(1)所示:
12、
13、式中,c表示向量qi的维度;
14、多个单头注意力模块构成一个多头注意力模块,首先将q、k、v、m送入线性变换层,然后把得到的输出分别送入单头注意力模块,最后将每个单头注意力模块的注意力头部输出级联起来送入线性变换层得到多头注意力模块的最终输出,多头注意力模块计算公式如公式(2)所示:
15、multihead(q,k,v,m)=concat(head1,head2,...,headh)wo(2)
16、式中,wo表示线性变换的参数矩阵,head1到headh代表每个单头注意力模块的注意力头部输出,h代表单头注意力模块的数量,其公式如公式(3)所示:
17、
18、式中,headj代表第j个单头注意力模块的注意力头部输出,和分别代表在输入第j个单头注意力模块前分别对q、k、v、m进行线性变换的参数矩阵;
19、前馈网络由两个线性变换层组成,其计算公式如公式(4)所示:
20、ffn(x)=max(0,xw1+b1)w2+b2 (4)
21、式中,x代表经多头注意力模块输出的特征,w1和w2分别代表线性变换层的权重矩阵,b1和b2分别代表线性变换层的偏置;
22、多头注意力模块在计算时没有不同输入特征的位置信息,如果对输入特征直接进行多头注意力建模会丢失位置信息,从而造成识别性能的下降,因此,在进行多头注意力建模时,需要首先对输入数据进行位置编码。
23、进一步,在步骤3)中,对步骤2)构建的场景文本识别模型进行知识蒸馏,具体是将大模型学习到的知识迁移到小模型中,该场景文本识别模型的蒸馏方案是基于resnet架构与transformer模块构建的,从特征提取模块与序列建模模块进行蒸馏,总的蒸馏损失函数公式如公式(5)所示:
24、ldistill=λflf+λsls (5)
25、式中,ldistill为总的蒸馏损失函数,lf为特征提取模块的蒸馏损失,ls为序列建模模块的蒸馏损失,λf和λs分别为对应的损失函数的权重;
26、教师网络模型和学生网络模型的特征提取部分都采用了resnet架构,其中教师网络模型是一个34层的resnet网络,学生网络模型是一个15层的resnet网络,场景文本识别模型对resnet架构中的四个阶段输出的特征进行蒸馏,特征提取模块的蒸馏损失lf的公式如公式(6)所示:
27、
28、式中,和分别代表教师网络模型和学生网络模型在第n个阶段输出的特征,n代表特征提取模块进行蒸馏的阶段数量,mse为均方误差函数;
29、教师网络模型的序列建模部分采用了6层的transformer架构,学生网络模型则采用了2层的transformer架构,且其中的多头注意力模块的头部数量设置为8;场景文本识别模型在教师网络模型的第三个transformer模块的输出蒸馏学生网络模型的第一个transformer模块的输出,教师网络模型的第六个transformer模块的输出蒸馏学生网络模型的第二个transformer模块的输出,序列建模模块的蒸馏损失ls的公式如公式(7)所示:
30、
31、式中,代表教师网络模型的第a层序列特征,1≤a≤y,代表学生的第b层序列特征,1≤b≤y,y代表教师网络模型和学生网络模型第y层知识蒸馏,y代表序列建模模块进行蒸馏的阶段数量;序列建模模块在多头注意力模块与前馈网络分别进行蒸馏操作,l为其加权和,其公式如公式(8)所示:
32、
33、式中,lattention代表对注意力模块知识蒸馏的损失函数,lffn代表对前馈网络知识蒸馏的损失函数,具体损失函数公式分别如公式(9)、(10)所示:
34、lattention=ce(at,as) (9)
35、lffn=ce(ft,fs) (10)
36、式中,at和as分别代表教师网络模型的注意力矩阵与学生网络模型的注意力矩阵,ft和fs分别代表教师网络模型和学生网络模型前馈网络的输出;ce代表对二者进行交叉熵损失函数计算。
37、进一步,在步骤3)中,将场景文本训练集中的图片输入到场景文本识别模型中进行训练,经大量数据的输入训练得到知识蒸馏后的场景文本识别模型,最终总的损失函数ltotal公式如公式(11)所示:
38、ltotal=ldistill+lpre (11)
39、式中,lpre代表学生网络模型最终预测结果与真实值计算得到的损失。
40、本发明的第二目的通过下述技术方案实现:基于知识蒸馏的场景文本识别系统,用于实现上述的基于知识蒸馏的场景文本识别方法,其包括:
41、数据获取与增强模块,用于获取场景文本数据集,对数据集中的图片进行数据增强处理,作为场景文本训练集;
42、识别模型构建模块,用于构建基于注意力机制的场景文本识别模型,该场景文本识别模型以大参数量的复杂网络模型作为教师网络模型,以参数量少的轻量级作为学生网络模型,为了在文本特征的序列建模中学习不同文本间的长距离依赖关系,该模型使用transformer模块来实现注意力机制;
43、知识蒸馏训练模块,用于将场景文本训练集中的图片输入到识别模型构建模块构建的场景文本识别模型中进行模型训练,在训练过程中将参数量大的教师网络模型的知识迁移到参数量少的学生网络模型上,实现知识蒸馏,保存训练完成的场景文本识别模型作为最优模型,后续将待测数据输入该最优模型中,即可得到精准的场景文本识别结果;其中,对于特征提取部分,采用中间层特征蒸馏的方式监督学生网络模型的训练;对于序列建模部分,利用教师网络模型中的相似度矩阵和前馈网络的输出作为监督信号,训练学生网络模型。
44、本发明的第三目的通过下述技术方案实现:一种存储介质,存储有程序,所述程序被处理器执行时,实现上述的基于知识蒸馏的场景文本识别方法。
45、本发明的第四目的通过下述技术方案实现:一种计算设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现上述的基于知识蒸馏的场景文本识别方法。
46、本发明与现有技术相比,具有如下优点与有益效果:
47、1、本发明利用了transformer进行序列特征建模,相较于传统的基于注意力的序列特征建模方法,该方法能够并行地计算不同特征之间的依赖关系,在建模长距离特征的依赖关系时不会因为距离的增加而产生信息损失,因此可以提高场景文本识别的准确率。
48、2、本发明具有广泛的应用前景,随着技术的发展,场景文本识别任务广泛的应用于各个方面,如:图像搜索、实时翻译、工业自动化和机器人导航等。但同时模型的识别准确率的提高往往伴随着复杂度的增加,因此将场景文本识别模型进行轻量化以满足移动端部署的需求非常重要。本发明可以在保证场景文本识别准确率的同时对识别模型进行轻量化,可以部署在计算能力较低的小型或移动设备上,具有一定的市场与前景,值得推广。
- 还没有人留言评论。精彩留言会获得点赞!