一种结合信息分组的基于位置编码预测的自监督学习方法
本发明涉及计算机视觉的自监督学习领域,具体地说,是一种结合信息分组的基于位置编码预测的自监督学习方法。
背景技术:
1、目前,在计算机视觉的各种任务上,预训练-微调的框架思想被广泛采用,在各种下游的计算机视觉任务上进一步提升了最好方法的性能,这里的下游任务包括图像分类、目标检测和语义分割等等。预训练-微调框架的主要思路是先在大规模数据集上预训练,再在目标数据集上微调。预训练的方式可以是有监督学习也可以是自监督学习,目前的研究表明,采用自监督学习的预训练比采用有监督学习的预训练效果更好,所以自监督学习逐渐成为预训练的主要方式。
2、最近出现的一种基于vision transformer(vit)架构的掩码学习方法,成为了自监督学习领域另一个热门方向,不仅可以在性能上超过对比学习方法,还比对比学习方法更加简单,对比学习非常依赖数据增强技术,而且往往需要使用两个编码器,这使得对比学习的训练时间更长、所需存储空间更多,而掩码学习不依赖数据增强技术,且只使用一个编码器。掩码学习的主要思想是:掩码一部分输入信号,然后预测这些掩码信号。
3、但是,基于vit的掩码学习方向上的研究太过单一,除了现有的针对像素信号进行掩码的方法外,还没有针对其他视觉信号进行掩码的方法。
技术实现思路
1、本发明针对基于vision transformer架构的掩码学习方法研究多样性不足的情况,提出了一种新的基于vision transformer架构的针对位置视觉信号的掩码学习方法,方法提出了一种新的代理任务,提出了信息分组的思想,最终能够在图像分类和目标检测任务上取得良好的效果。
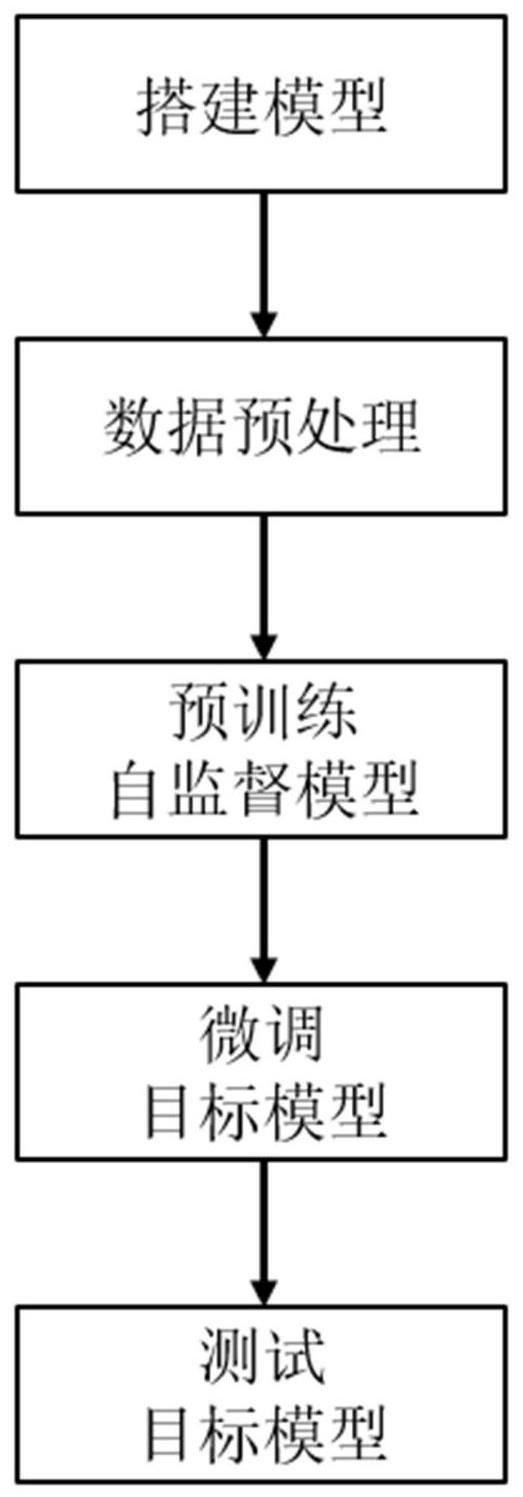
2、实现本发明目的的技术解决方案为:结合信息分组的基于位置编码预测的自监督学习方法,包括以下步骤:
3、1)搭建模型,根据代理任务的要求搭建合适的自监督模型,根据目标任务的要求搭建合适的目标模型;
4、2)数据预处理,对原始图像依次进行图像裁剪、移除间隔区域,划分patch和随机打乱操作;
5、3)预训练自监督模型,将预训练数据集中训练集的图像输入到自监督模型中,对自监督模型进行训练,称为预训练阶段;
6、4)微调目标模型,将微调数据集中训练集的图像输入到目标模型中,对目标模型进行训练,称为微调阶段;
7、5)测试目标模型,在微调数据集的测试集上测试目标模型的性能。
8、所述步骤1)搭建模型,具体实现如下:
9、自监督模型包括特征提取模块(编码器模块)和特定任务模块(解码器模块和相对位置预测模块),编码器模块是一个网络层数为12的vision transformer(vit),解码器模块是一个网络层数为1的vision transformer,vit的每层网络包括一个自注意力模块和一个前馈神经网络模块,vit使用已有的开源模型,但是不使用其中的位置编码模块,相对位置预测模块是一个使用卷积核大小为1×1、步长为1的卷积层、标准化层和激活层构建的多层感知机,目标模型可以在目前开源的图像分类模型和目标检测模型中选择能适配自监督模型中编码器模块的模型,也就是目标模型的特征提取模块必须与自监督模型的特征提取模块具有相同的网络架构(网络层数为12的vit)。
10、所述步骤2)数据预处理,具体实现如下:
11、将原始图像使用pytorch的randomresizedcrop方法裁剪成固定尺寸;从裁剪后的图像中移除间隔区域,移除间隔区域的方式是对裁剪后的图像从行和列两个维度上每隔pn个像素移除mn个像素,pn是patch的尺寸,mn是间隔的尺寸;将移除间隔区域后的图像划分成尺寸为pn×pn的若干个patch;将patch集合随机打乱;原始图像是预训练数据集中的图片,预训练数据集可以使用imagenet-1k数据集的训练集、imagenet-21k数据集的训练集以及计算机视觉领域的其它数据集的训练集,预训练数据集越大越好。
12、所述步骤3)预训练自监督模型,包括以下步骤:
13、(31)将随机打乱后的patch集合输入到模型中,模型使用信息分组的思想处理patch集合,输出预测结果,预测结果是patch之间在上、下、左、右、左上、左下、右上和右下相对位置关系上的概率分布图;
14、(32)根据代理任务自动生成伪标签;
15、(33)对于预测结果和伪标签,使用代理任务定义的损失函数计算损失。
16、所述步骤31)具体实现如下:
17、将随机打乱后的patch集合(patch的个数为n)划分成多组(组的个数为gn),则每组patch的个数为ng=n/gn,将各组patch单独输入到模型的编码器模块中提取特征,所以编码器每次输出ng个长度为c的特征向量,共输出gn组,将编码器模块输出的多组patch特征汇集起来,可以得到n个长度为c的特征向量;将汇集的所有patch特征一起输入到模型的解码器模块中再次提取特征,解码器输出n个长度为c的特征向量,将这n个特征向量两两相减,得到尺寸为n×n×c的关联特征图其中ri,j表示第i个patch的特征向量减去第j个patch的特征向量后的新特征向量,新特征向量表示的是两个patch在特征层面上的关联性;将关联特征图输入到模型的相对位置预测模块中得到n×n×8大小的预测结果其中是从ri,j映射而来,表示第i个patch和第j个patch在八种相对位置关系上存在关系的概率。
18、所述步骤32)具体实现如下:
19、使用pi(0≤i≤n-1)表示随机打乱后的patch集合中的第i个patch,n是集合中patch的个数;使用po(i)表示pi在移除间隔区域后的图像中的坐标,比如po(i)=(x,y)表示pi在移除间隔区域后的图像中的第x列第y行;使用来表示生成的伪标签,其中yi,j,k表示实际上pi和pj之间具有第k种相对位置关系的概率,8是相对位置关系的类型数(包括:上、下、左、右、左上、左下、右上、右下),伪标签的生成公式如下:
20、yi,j,k=sh(tg(i,j)×maski,j,k)#(1)
21、其中,tg表示经过归一化的二维标准高斯分布函数,即首先使用标准高斯分布函数来生成n×n范围内的概率分布图,然后对概率分布图采用min-max归一化,tgi,j表示在以po(i)为中心的二维高斯分布函数中po(j)对应的值;表示每种相对位置关系的有效涵盖范围,maski,j,k表示第i个patch和第j个patch是否存在第k种相对位置关系,值为0表示不存在,值为1表示存在,mask采用人为设定的方式来定义。
22、所述步骤33)具体实现如下:
23、使用二值交叉熵损失函数作为基础的损失函数,为了避免正负样本不均衡导致的训练问题,对正负样本分别计算损失再相加,使用来表示生成的伪标签,yi,j,k表示实际上pi和pj之间具有第k种相对位置关系的概率,使用来表示模型输出的预测结果,表示模型预测的pi和pj之间具有第k种相对位置关系的概率,具体的损失函数公式如下:
24、
25、l=l++l-
26、其中,l+是正样本的平均损失,l-是负样本的平均损失,l是总损失,mask的含义与公式(1)相同,bce表示二值交叉熵损失函数。
27、所述步骤4)微调目标模型,具体实现如下:
28、将目标模型的特征提取模块替换为经过预训练后的自监督模型中的特征提取模块(编码器模块),按照现有方法的训练策略在微调数据集的训练集上进行微调;具体来说,使用代理任务定义的损失函数和代理任务生成的伪标签,在预训练数据集上预训练自监督模型,预训练结束后将自监督模型中的特征提取模块迁移到目标模型中,所以目标模型的特征提取模块和自监督模型的特征提取模块具有相同的网络权重,微调数据集的训练集可以是分类任务中的imagenet-1k数据集的训练集或者目标检测任务中的coco数据集的训练集。
29、所述步骤5)测试目标模型,具体实现如下:
30、使用现有方法的测试策略,在微调数据集的测试集上测试目标模型在目标任务上的性能,如分类任务中的top-1准确率和目标检测任务中的平均准确率均值(mean averageprecision,map),微调数据集的测试集可以是分类任务中的imagenet-1k数据集的测试集或者目标检测任务中的coco数据集的测试集。
31、本发明与现有技术相比,其显著优点:本发明提出了一种新的掩码学习方法,在训练的时间成本和空间成本相似的情况下,实现了与现有掩码学习方法相当的性能,方法针对位置视觉信号进行掩码,丰富了基于vit的掩码学习方向上研究的多样性。
- 还没有人留言评论。精彩留言会获得点赞!