强化学习框架下场景图骨架构建方法
本发明属于强化学习,尤其涉及强化学习框架下场景图骨架构建方法。
背景技术:
1、图像场景图是由节点和边组成的有向图,图中节点分为三种类型,分别为图像中的对象类别、对象属性和对象间的关系,有向边表示节点间的作用方向。通过建立图像场景图,就可以用结构化的方式准确表示图像中的高层语义信息,能够使得计算机直接存储和分析。与图像描述相比,场景图的构建是图像描述方法的升级,具体表现在两个方面:一方面,场景图由许多候选区域组成,每个区域包含了对象类别和属性的高层语义,而不同的对象之间存在相互关系,这种关系是场景图中不可或缺的节点。与图像描述中对象间关系表征欠拟合不同,场景图能够对图像中对象间的关系进行密集表示。另一方面,场景图是结构化数据,其解决了图像描述只能得到半结构化文本的问题。
2、目前场景图的构建方法通常是预先建立全连接场景图骨架,然后再进一步的进行对象和关系分类,而骨架的全连接特性决定了其包含了大量冗余信息,特别是在真实复杂的场景中,这些冗余信息不仅会增加整个算法的复杂度,还会影响对象和关系分类的准确度。如何建立高信息度低复杂度的稀疏场景图骨架,是在理论和工程实践上建立高效、精确场景图构建模型的基础。因此高信息度低复杂度的稀疏场景图骨架的构建,是本领域要解决的一个关键科学问题。
技术实现思路
1、有鉴于此,本发明提出了利用强化学习框架得到稀疏场景图骨架的问题,尝试将场景图骨架的建立过程作为马尔科夫决策过程,利用强化学习得到一个稀疏的场景图骨架,为精确场景图骨架构建提供理论依据。
2、本发明公开的强化学习框架下场景图骨架构建方法,包括以下步骤:
3、生成基于马尔科夫决策过程的图结构;
4、构建图结构生成环境;
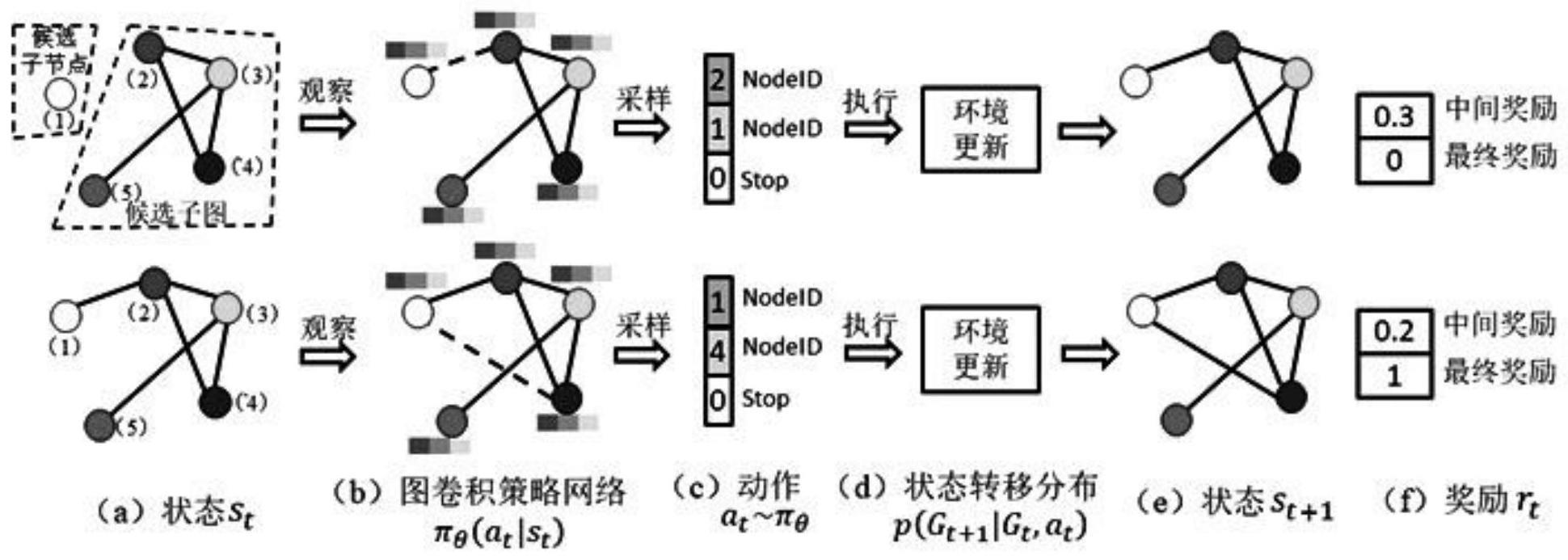
5、构建图卷积策略网络,并对图卷积策略网络进行训练,在关系感知环境下以迭代的方式不断向候选子图中添加节点和边,最终形成图像的场景图骨架。
6、进一步的,所述生成基于马尔科夫决策过程的图结构,包括:
7、将图结构的生成过程表述为一个通用决策过程m=(s,a,p,r,γ),其中s={si}是由所有可能的中间图和最终图组成的状态集,a={ai}是一组动作,描述在每个时刻对当前图结构的修改,p=p(st+1|st,st-1,…,s0,at)为状态转移分布,表示执行一项行动可能产生结果的概率,其中s0,…st,st+1为第0,…t,t+1时刻的图结构,at为第t时刻的动作,r(st)为所设计的奖励函数,表示图结构达到状态st后的奖励,γ为折扣因子,用于减少未来的回报的对当前动作的影响;
8、图结构生成的过程表示为一个迭代轨迹(s0,a0,r0,…,sn,an,rn),其中sn为最终生成的图结构,an为最终生成的动作,rn为最终生成的奖励;
9、图结构在每次迭代中会进行节点间边的增加,增加边后图结构的状态转移分布表示为:
10、
11、其中,p(at|st,…,s0)为策略网络πθ,πθ为一种图卷积策略网络,采用马尔可夫决策过程的图结构生成过程,在这个过程中要求状态转移分布满足马尔可夫性质,即p(st+1|st,st-1,…,s0,at)=p(st+1|st,at);在此性质下,策略网络πθ以当前时刻的图结构st为输入来生成下一步的执行动作,即确定哪两个节点应该连接或者确定整个生成过程停止。
12、进一步的,所述构建图结构生成环境,包括:
13、在基于马尔科夫决策过程的图结构生成策略下,环境通过策略网络给出的动作以迭代的方式逐步建立场景图骨架,在每次迭代步骤中有五个组成部分,即状态表示、策略网络、动作、状态转移分布和奖励;
14、所述状态空间将环境的状态st定义为第t次迭代后生成的图结构gt,每一次图结构的更新都受强化学习智能体的控制;
15、动作空间:首先,定义一个候选子节点集合c={c1,c2,…,cs},集合中的节点在图生成的过程中不断被添加到候选子图中;然后,在第t次迭代过程中,定义扩展图为候选子图与候选子节点集合的并集,表示为gt∪c,其中gt为候选子图,c为候选子节点;动作分为三种类型:1)候选子图中在上一次迭代时未存在连接的两个节点进行连接,在此动作后候选子节点集合不发生变化;2)候选子图中的特定节点与候选子节点集合中的节点进行连接,此时将候选子节点中存在连接的节点移除;3)候选子节点集合中特定两个节点进行连接;此时将存在连接的两节点从候选子节点结合中移除;
16、状态转移分布:将特定领域的动作规则纳入到状态转移分布中,对于场景图骨架生成任务,环境结合了数据集中对象间的连接规则,此连接规则是在对数据集中所有连接统计后得出,如果在数据集中对象与对象之间没有存在连接,那么这种结果被当作连接规则的一种;
17、奖励函数:在场景图骨架生成环境中,强化学习智能体的动作被两类奖励函数指导,分别是中间奖励和最终奖励;其中,所述中间奖励包括特定领域规则奖励和对抗性奖励,如果动作不违反图构建规则,则根据数据集中的关系统计分配少量的正面奖励,否则分配少量的负面奖励;所述最终奖励定义为对抗性奖励和场景图正确率奖励的总和,其中,场景图正确率奖励从场景图分类任务中评价指标的召回率获得,采用生成性对抗网络来定义对抗性奖励v(πθ,dφ)。
18、进一步的,其中,所述生成性对抗网络的构建过程表示为:
19、
20、其中,πθ为策略网络;pdata定义了最终图或中间图的数据分布情况,所述最终图用于最终奖励,所述中间图用于中间奖励;dφ为判别器网络,x表示输入的图结构,dφ(x)∈[0,1]是判别模型的输出结果,用来判断图结构的合理程度;e表示数学期望;由于x是一个对参数φ不可微的图数据,因此只有判别器dφ用随机梯度下降来训练,而对于策略网络,引入策略梯度方法对其进行训练。
21、进一步的,在场景图骨架生成环境中,采用图卷积策略网络计算动作引起的状态转移概率,图卷积策略网络包括:
22、图卷积策略网络的输入是候选子图和候选子节点集,输出为当前迭代步骤将要发生的动作,网络最终的结构和参数是强化学习智能体学习的目标;
23、节点嵌入特征计算:为了能够在扩展图gt∪c中预测当前迭代步骤的动作,利用图卷积网络来计算节点的嵌入特征;通过l层的图卷积网络,对图中的每个连接执行共l层的消息传递;在网络的第l层,节点的嵌入过程如下:
24、
25、其中,a为图结构的邻接矩阵,i是对角线为1其余值为0的单位矩阵,d为图结构的度矩阵,w(l)为图卷积网络第l层训练的参数,h(0)为对象节点的深度特征,此为faster r-cnn网络roi池化层的输出,x=h(l),h(l),h(l+1)分别是第l层和l+1层神经网络结点输出的深度特征;
26、动作预测:在第t次迭代步骤中,动作的预测是三个组件的串联:即两个节点的选择和终止的预测,表示为at=concat(astart,aend,astop),astart和aend是选择的两个节点,astop是终止节点,每个组件通过基于神经网络表示的预测分布进行采样,当astop=1时,强化学习环境下图结构的迭代过程结束,当前图结构为生成的初始场景图骨架。
27、进一步的,策略梯度训练包括:
28、采用近端策略优化ppo来训练图卷积策略网络,ppo的目标函数定义如下:
29、
30、其中,πθold(at|st)为更新前的策略网络,πθ(at|st)为更新后的策略网络,rt(θ)为网络更新前后策略网络输出的比值,且被截断到[1-ε,1+ε]区间,作用是将lclip(θ)成为保守策略迭代目标的下限,clip为操作符,表示如果第一项小于第二项,最终值取第二项,如果第一项值大于第三项,最终值取第三项,如果在二者之间,则保持自己的值;ε是训练中需要调整的超参数,at为优势函数,描述了在状态st下所采取的动作随机采取一个动作的优势,评价动作的值函数是生成对抗网络中的判别函数,其原理为先将图嵌入,然后利用多层感知器进行评分。
31、本发明的有益效果如下:
32、本发明利用强化学习框架得到稀疏场景图骨架的问题,将场景图骨架的建立过程作为马尔科夫决策过程,利用强化学习得到一个稀疏的场景图骨架,构建了高信息度低复杂度的稀疏场景图骨架,为精确场景图骨架构建提供依据。
- 还没有人留言评论。精彩留言会获得点赞!