应用于城市大脑自然语言处理的文本标注方法及装置与流程
本发明涉及人工智能,且特别涉及一种应用于城市大脑自然语言处理的文本标注方法、装置及电子设备。
背景技术:
1、城市大脑是互联网大脑架构与智慧城市建设结合的产物,是城市级的类脑复杂智能巨系统,在人类智慧和机器智能的共同参与下,在物联网,大数据,人工智能,边缘计算,5g、云机器人、数字孪生等前沿技术的支撑下,城市神经元网络和城市云反射弧将是城市大脑建设的重点,城市大脑的作用是提高城市的运行效率,解决城市运行中面临的复杂问题,更好的满足城市各成员的不同需求。
2、城市大脑是基于城市运行所产生的信息作为输入的智能系统,城市运行不仅会产生海量数据且数据格式不统一,故如何从杂乱的信息中获取有效信息已成为业界的研究热点。文本分类任务是自然语言处理(nlp)领域中最基础的任务之一,其不仅能有效的筛选信息,而且在信息检索和自动文摘等方面有着重要的应用。当前基于文本的分类主要聚焦于文本业务类型的分类,涉及情感分类的极少且情感分类和业务分类之间是独立的。
3、随着物联网技术的不断普及,与人们日常相关的舆情信息也逐渐以数据的形式汇集到相关部门。对于此类信息,其在反馈相关业务的同时也包含着反馈者对于该业务的情感和迫切度,因此亟需分析这类文本的业务类别和情感类别以更好地指导相关部门快速且有序地解决相关问题。但由于这类舆情信息通常会包含无意义冗余词,若直接采用原始文本作为语料进行模型训练以进行业务分类,忽略了冗余词对分类准确性的影响将会导致分类准确性差或无法分类的问题。此外,大量的无意义冗余词也会给情感分类带来很大的困难,且情感标注和业务标注的分离也使得信息接收者很难识别海量信息的重要程度。故当前与人们日常相关的舆情信息主要还是通过人工的方式进行标注,耗费大量人力资源。
技术实现思路
1、本发明为了克服现有技术的不足,提供一种应用于城市大脑自然语言处理的文本标注方法、装置及电子设备。
2、为了实现上述目的,本发明提供一种应用于城市大脑自然语言处理的文本标注方法,其包括:
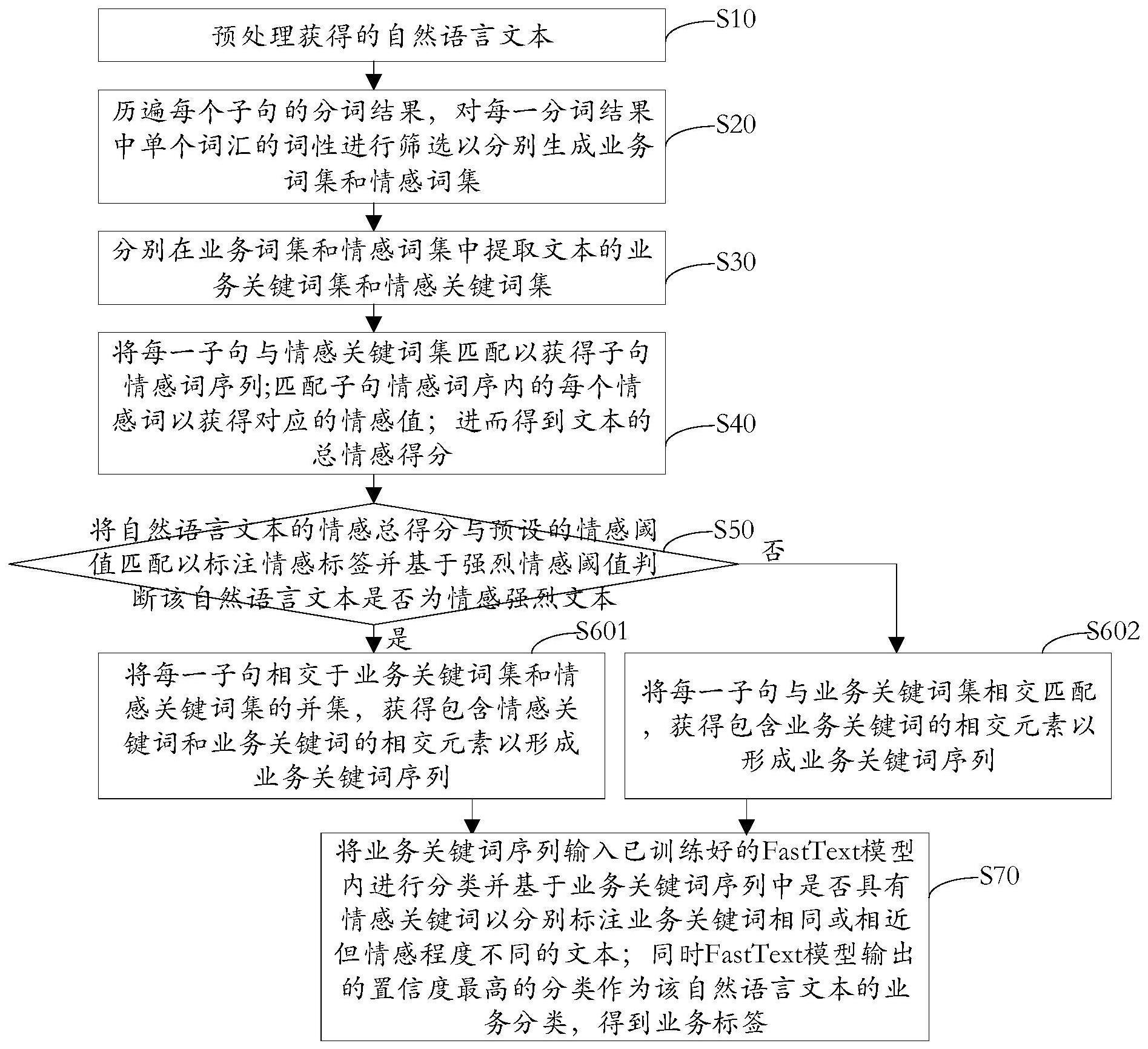
3、预处理获得的自然语言文本,包括子句切分和每一子句的分词处理;
4、基于预设的词性集合历遍每个子句的分词结果,对每一分词结果中单个词汇的词性进行筛选以分别生成业务词集和情感词集;
5、分别在业务词集和情感词集中提取文本的业务关键词集和情感关键词集;
6、将每一子句与情感关键词集匹配以获得每个子句所对应的子句情感词序列,将子句情感词序内的每个情感词与情感词典匹配以获得每个情感词所对应的情感值;基于多个情感词的情感值得到自然语言文本的情感总得分;
7、将自然语言文本的情感总得分与预设的情感阈值匹配以标注情感标签并基于强烈情感阈值判断该自然语言文本是否为情感强烈文本;
8、若判断表明当前自然语言文本为情感强烈文本,则认为情感词会影响业务标签标注,将每一子句相交于业务关键词集和情感关键词集的并集,获得包含情感关键词和业务关键词的相交元素以形成业务关键词序列;若判断表明当前自然语言文本为非情感强烈文本,则认为情感词不会影响业务标签标注,将每一子句与业务关键词集相交匹配,获得包含业务关键词的相交元素以形成业务关键词序列;
9、将业务关键词序列输入已训练好的fasttext模型内进行分类并基于业务关键词序列中是否具有情感关键词以分别标注业务关键词相同或相近但情感程度不同的文本;同时fasttext模型输出的置信度最高的分类作为该自然语言文本的业务分类,得到业务标签。
10、根据本发明的一实施例,在计算子句情感词序列内的每个情感词的情感值时:
11、判断子句情感词序列内每一情感词的词性以确定当前子句是否包含情感程度词,所述情感程度词包括助词、动副词以及副词;
12、若判断表明当前子句仅包括一个或多个单形容词且无情感程度词时,根据预设的仅与单形容词相关的第一计算规则计算其情感值;若判断表明当前子句包含情感程度词,则在一个或多个单形容词的基础上结合情感程度词权重以第二计算规则计算情感值。
13、根据本发明的一实施例,当判断表明当前子句包含情感程度词,基于词空间距离获取与每一情感程度词距离最近且出现在情感程度词后侧的单形容词并根据该情感程度词的权重更新距离最近且位于其后侧的单形容词的情感值。
14、根据本发明的一实施例,以子句中的一个单形容词为节点,相邻节点之间采用滑动窗口m对子句进行开窗划分,以滑动窗口m为度量单位将情感程度词匹配至与其最接近且出现在情感程度词后侧的单形容词,根据该情感程度词的权重更新位于其后侧的单形容词的情感值。
15、根据本发明的一实施例,计算子句情感词序列内的每个情感词的情感值时,判断子句情感词序列内的情感词是否包含连词;若是,则在第一计算规则或第二计算规则的基础上融合连词权重。
16、根据本发明的一实施例,预处理获得的自然语言文本包括:
17、将获得的自然语言文本切分成多个子句并构建子句集合t={s1,s2,…,sn};
18、对子句集合内的每个子句si进行分词以得到多个分词结果si={w1={w1,p1},w2,…,wn},每一分词结果均包括分词后的单个词汇wi和该词汇的词性pi;
19、通过预设的停用词集合st过滤每一子句si中无意义的停用词。
20、根据本发明的一实施例,在获得情感词集采用如下步骤提取相应的情感关键词集:
21、根据情感词之间的共现关系,以情感词汇wi为节点并基于滑动窗口h中出现的同类词汇构建候选情感关键词无向有权图;
22、根据以下公式迭代传播各节点权重直至收敛以得到候选情感关键词权重值集tre:
23、
24、其中,tre(wi)为词汇wi的权重;d代表阻尼系数,设置为0.85;in(wi)代表指向wi节点的集合;out(wi)代表wi所指向的节点集合;weji代表节点wj到节点wi的连接权重;wejk代表节点wj到节点wk的连接权重;tre(wj)为词汇wj的权重;
25、对得到的候选情感关键词权重值集tre按权重值进行降序排序并得到情感关键词集kwe;
26、采用相同的步骤在业务词集中提取情感关键词集keb。
27、另一方面,本发明还提供一种应用于城市大脑自然语言处理的文本标注装置,其包括预处理单元、词集筛选单元、关键词提取单元、情感值计算单元、情感标注单元、业务参数提取单元以及模型输出单元。预处理单元预处理获得的自然语言文本,包括子句切分和每一子句的分词处理。词集筛选单元基于预设的词性集合历遍每个子句的分词结果,对每一分词结果中单个词汇的词性进行筛选以分别生成业务词集和情感词集。关键词提取单元,分别在业务词集和情感词集中提取文本的业务关键词集和情感关键词集。情感值计算单元将每一子句与情感关键词集匹配以获得每个子句所对应的子句情感词序列,将子句情感词序内的每个情感词与情感词典匹配以获得每个情感词所对应的情感值;基于多个情感词的情感值得到自然语言文本的情感总得分。情感标注单元将自然语言文本的情感总得分与预设的情感阈值匹配以标注情感标签并基于强烈情感阈值判断该自然语言文本是否为情感强烈文本。若情感标注单元判断表明当前自然语言文本为情感强烈文本,则认为情感词会影响业务标签标注;业务参数提取单元将每一子句相交于业务关键词集和情感关键词集的并集,获得包含情感关键词和业务关键词的相交元素以形成业务关键词序列;若判断表明当前自然语言文本为非情感强烈文本,则认为情感词不会影响业务标签标注,业务参数提取单元将每一子句与业务关键词集相交匹配,获得包含业务关键词的相交元素以形成业务关键词序列。模型输出单元将业务关键词序列输入已训练好的fasttext模型内以进行分类并基于业务关键词序列中是否具有情感关键词以分别标注业务关键词相同或相近但情感程度不同的文本;同时fasttext模型输出的置信度最高的分类作为该自然语言文本的业务分类,得到业务标签。
28、另一方面,本发明还提供一种电子设备,其包括一个或多个处理器和存储装置。存储装置用于存储一个或多个程序。当一个或多个程序被一个或多个处理器执行,使得一个或多个处理器实现上述应用于城市大脑自然语言处理的文本标注方法。
29、综上所述,本发明提供的应用于城市大脑自然语言处理的文本标注方法对每一自然语言文本分别进行业务标注和情感标注以实现文本信息的多维度展示。进一步的,业务标注以业务关键词为基础标注业务标签;而对于事件相同,但情感程度不同的事件,譬如对某不文明事件的建议和投诉,只采用业务关键词会导致标注相同标签的问题出现,为此本发明保留情感强烈文本的情感关键词并作为业务关键词辅助业务分类,有助于提高分类的准确性,便于对事态严重事件快速筛选,提升事件处理能力。进一步的,在计算情感值时提出基于情感程度词和连词的情感值计算方式,该计算方式从词性的多维度上考虑情感值以实现复杂民情文本情绪标签的准确提取。此外,通过构建业务关键词集和情感关键词集来对每个句子进行筛选匹配,去除冗余词来分别形成子句情感词序列和业务关键词序列,从而有效地解决多冗余词对分类标注的影响,提高分类的准确性;同时又避免了语料过于庞大而造成的计算资源浪费。
30、为让本发明的上述和其它目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!