面向向量DSP芯片的矩阵处理系统及方法
本发明涉及向量数字信号处理器芯片上层软件开发领域,更具体地说,涉及一种面向向量dsp芯片的矩阵处理系统及方法。
背景技术:
1、数字信号处理器(digital signal processing,dsp)是一种专用的嵌入式微处理器。而dsp芯片作为伴随着数字信号处理技术而诞生的微处理器,具有运算速度高、实时性强、处理能力强的特点,在人们的生产、生活领域中占据了重要的地位。
2、在数字信号处理技术中常用的算法,如矩阵运算、快速傅里叶变换等,都有一个基本特征,就是乘法和累加运算比较多,针对数字信号处理算法中的此类运算,dsp在其内核中设置硬件乘加器和乘累加指令,以提高运算速度,满足这些算法的应用。随着数字信号的不断发展,dsp的应用领域变得更加广泛,同时在这些领域对高性能计算的需求也变得更加迫切。
3、为了使矩阵处理运算、雷达信号处理、快速傅里叶变换、数字图像处理等计算密集型应用提升计算性能和效率,传统dsp架构不断往新的方向发展,数字信号处理器的体系结构不断更迭,出现了高性能向量数字信号处理器。片上多核、可重构阵列处理结构以及流体系结构是高性能dsp使用的主要结构,同时结合了超长指令字(very long instructionword,vliw)、单指令流多数据流(single instruction multiple data,simd)、专用指令集处理器(application specific instruction set processor,asip)等相关领域的众多新技术进一步提升dsp计算效率。目前主流向量dsp通常采用vliw技术和simd技术,在硬件层面通常包括多级存储结构体系、运算单元、寄存器、dma等模块。单指令流多数据流有效提高了数据计算的峰值性能,并且充分挖掘了指令和数据的并行度,向量数字信号处理器逐渐成为高性能dsp处理器的发展趋势。
4、矩阵处理是线性代数领域的重要组成部分,作为数据密集型计算,在高性能计算领域也扮演着重要的角色。矩阵处理不仅是评测微处理器性能的重要手段,亦是数学标准函数库中的核心组成部分。
5、随着高性能向量dsp的快速发展,应用于传统dsp芯片的矩阵处理程序移植在向量dsp芯片不能有效利用多级存储结构体系、向量运算单元和寄存器等,计算性能不理想,不能有效的发挥向量dsp芯片的体系结构优势。现有技术的方法中,存在如下技术问题:适用于传统dsp芯片的矩阵处理方法移植在向量dsp芯片,在数据运算过程不能以simd向量化的方式执行,不能充分调度向量dsp芯片向量运算功能部件和向量寄存器资源,指令级并行和数据级并行度不够高,不能发挥向量dsp芯片的计算能力。
技术实现思路
1、本发明要解决的技术问题在于,提供一种面向向量dsp芯片的矩阵处理系统及方法,其以充分利用dsp芯片的架构优势、发挥其计算性能,提高矩阵处理的并行度及效率,能够以优化矩阵处理的效率。
2、本发明解决其技术问题所采用的技术方案是:构造一种面向向量dsp芯片的矩阵处理系统,包括矩阵存储空间分配模块、矩阵循环并行优化模块、数据访存时延隐藏模块和数据保护模块;
3、所述矩阵存储空间分配模块用于对待处理矩阵数据设置相应的存储空间分配策略,为后续矩阵以simd向量化方式运算做铺垫;
4、所述矩阵循环并行优化模块为矩阵内层循环处理的数据分配寄存器,并调度向量dsp同构的功能部件,以对矩阵内层多次循环做并行化处理;
5、所述数据访存时延隐藏模块用于将矩阵数据处理过程中的访存延迟隐藏在数据运算的时隙中,减少矩阵处理过程中访存所引起的性能损失,提高程序执行的并行程度;
6、所述数据保护模块用于避免在向量数字信号处理器中矩阵数据处理过程时因数据写回时导致的错误。
7、本发明还通了一种面向向量dsp芯片的矩阵处理方法,包括以下步骤:
8、s1、将待处理数据进行存储:根据矩阵规模的大小,为待处理的矩阵数据设置相应的存储方案;
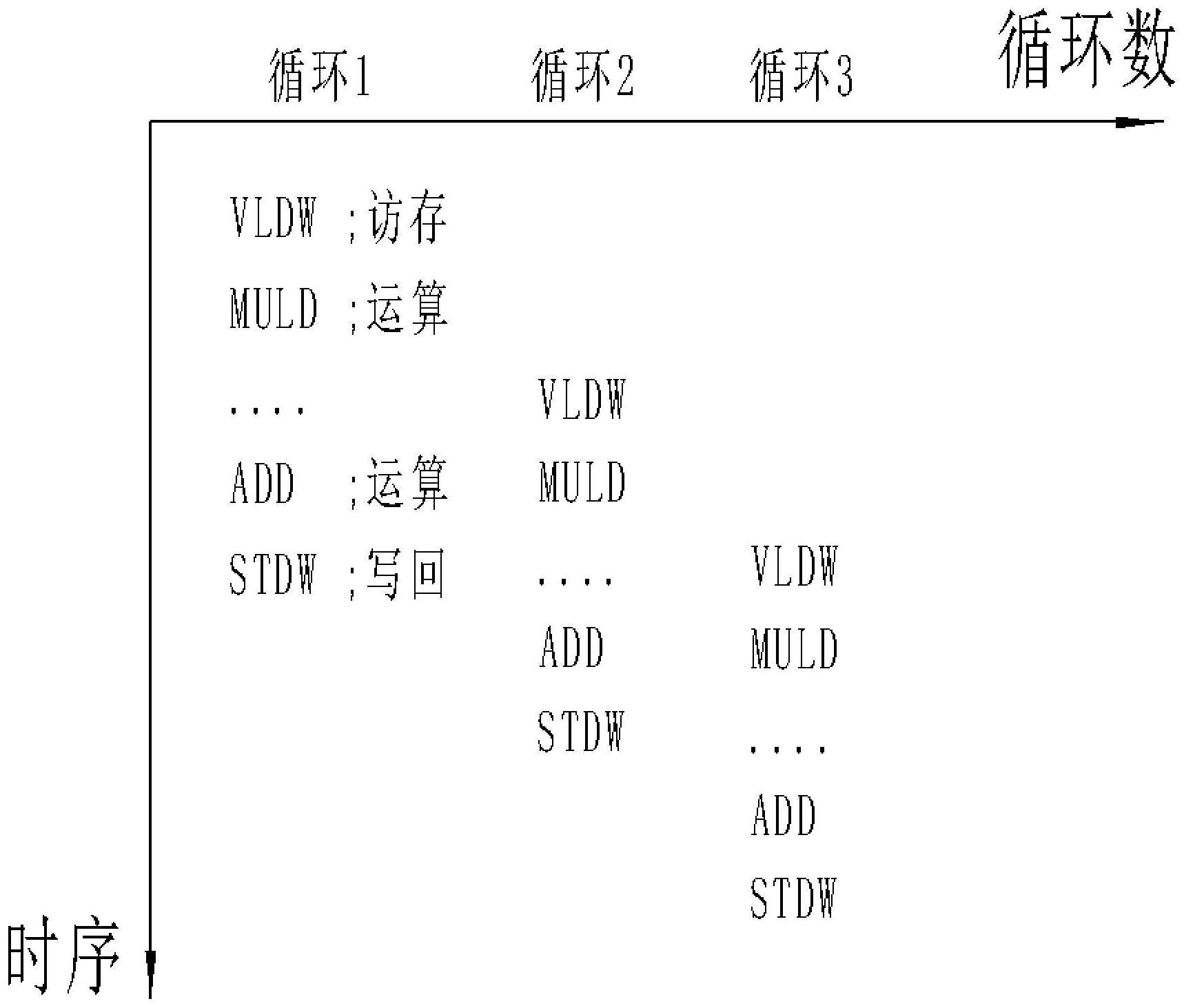
9、s2、将矩阵数据处理过程循环并行优化:对于矩阵运算过程中的内层循环,通过分配寄存器与调度dsp功能部件的策略合并执行k1次循环;
10、s3、数据访存时延进行隐藏:对于循环处理的矩阵数据,数据访存占据了全局处理的所耗时延的绝大部分;
11、s4、对数据进行保护:在矩阵运算过程中若按行循环处理,且当矩阵的规模不是向量数字信号处理器单指令流出数的整倍数时,第n次循环的写回操作会部分覆盖第n+1次循环的待处理数据,从而导致错误。
12、按上述方案,所述步骤s1中:
13、若待处理矩阵满足max{nrows,ncols}<n,则将全部待处理数据放入标量空间中,若nrows*ncols*sizeof(auto)≤vectormemory.size,则将全部待处理数据放入向量存储空间中。
14、按上述方案,所述nrow为待处理矩阵的行数,ncols为待处理矩阵的列数,n为向量dsp处理器的单指令数据流出数,sizeof(auto)为存储单个待处理数据所用的空间大小,vectormemory.size为向量存储器的总空间大小。
15、按上述方案,所述步骤s2中,为k1次循环的每个数据都分配相应的标向量寄存器,并调度同构的向量dsp硬件功能部件对已分配的寄存器进行运算,达到合并执行k次循环的目的,以减少反复访存操作,同时提高程序处理的并行性。
16、按上述方案,所述k1的数值按照如下公式来确定:
17、k1=min{freereg.num/currentreg.num,sparealu.num}
18、其中,freereg.num为全局未使用的寄存器数量,currentreg.num为本次循环所使用的寄存器数量,sparealu.num为当前时钟周期空闲的同构硬件功能单元数。
19、按上述方案,所述步骤s3中,在汇编语言层面排布循环体,设置两次相邻循环的时钟周期排布间隔相差数为k2,从而矩阵处理过程中第n次循环的计算指令与第n+1次循环的访存并行,第n+1次循环矩阵数据的计算过程则无需等待访存完成。
20、按上述方案,所述k2的数值按照如下公式来确定:
21、k2=max{alu.num/thisalu.num,longestcmd.cycle,mem.cycle+1}
22、其中alu.num为向量dsp芯片同构功能单元的数量,thisalu为单次循环所用到的功能单元数,longestcmd.cycle为单次循环中最长指令所用到的时钟周期数,mem.cycle为访存指令的时钟周期数。
23、按上述方案,所述步骤s4中,在第n次循环的数据写回操作之前,将第n+1次循环的待处理数据保存在寄存器中,在该部分数据处理之前将其写回,也可直接对寄存器中的数据进行处理,计算完成后写回。
24、实施本发明的面向向量dsp芯片的矩阵处理系统及方法,具有以下有益效果:
25、本发明提出了一种面向向量数字信号处理芯片的方法,根据矩阵处理本身的特点,以及向量数字信号处理器的体系结构特点,制定数据存储方案,为矩阵以标向量并行的方式运算做铺垫;引入矩阵数据处理循环并行优化方案,提高矩阵处理的并行化程度以及对向量dsp硬件资源的利用率;引入数据访存时延隐藏方案,减少矩阵处理过程中访存所引起的性能损失,提高了程序执行的并行程度;引入数据保护方案,避免了矩阵simd向量化循环处理过程中所引起的数据覆盖错误。采用以上方案,使矩阵处理过程更加贴合向量数字信号处理器架构特征,发挥向量数字信号处理器计算性能优势,提高矩阵处理过程的指令级并行与数据级并行程度以及效率。
- 还没有人留言评论。精彩留言会获得点赞!