一种基于联合建模的多粒度情感分析方法
本发明提供一种基于联合建模的多粒度情感分析方法,属于深度学习领域。
背景技术:
1、在数字化和信息化的当今社会,互联网已经成为了人们生活基础设施的一部分。伴随电子商务的快速发展,电子商务平台上海量的用户反馈已经沉淀为消费者和商家共同的宝贵数据资源。在线商家为了对反馈意见进行合理的组织和分析,以期能够精确了解用户使用体验,为后续提供改进方向;进一步可针对用户进行精准的细粒度情感分析,为其推荐量身定制推荐方案。
2、在自然语言处理领域中,情感分析也被称为意见挖掘,基于输入文本进行总体情感极性分类。情感分析的目的是根据文本的情感状态和主观信息,将文本分为积极的或消极的,有时甚至是中性的。在文档级规模的评论内容中,往往包含对多方面的情感观点,以上所述的粗粒度情感分析技术难以实现对每个细化方面的意见捕捉,从而实现更精准的用户画像。对此一些工作提出了面向方面词的情感分析方法,以判断针对某一方面的情感倾向。当前被提出的方法中,多是基于两种分析粒度分别建模,二者并无交互。然而在实际用户画像场景中,二者往往具有高度相关性,忽略之间的语义信息,可能会使模型性能进一步陷入瓶颈。因此,基于多粒度的分析方法既符合人类认知范式,也能得到更精确的画像结果。
3、目前的细粒度情感分析方法多采用预训练后微调的任务范式,借助bert预训练语言模型对方面词进行嵌入表示,辅以attention机制捕获与方面词相关度高的上下文词语,而后通过池化层输入softmax得出预测结果。其中比较典型的有联合注意力机制的情感分类,通过对lstm进行扩展,可将方面词表达、上下文嵌入连接作为网络输入;基于多头注意力机制的情感挖掘,分别利用全局和局部注意力模块捕获方面词和上下文之间的不同粒度的交互信息;结合注意力机制和bert的多重交互注意力网络,利用部分transformer并行计算获得隐藏态,捕获更多语义细节。
4、上述工作在数据表达和训练网络上进行了创新改造,但是在训练方法上忽略了粗粒度和细粒度之间的关联,无法达成用户精细画像的目标。此外,通用的表达计算会忽略与目标域相关的重点情感词。所以,为了实现融合多粒度情感分析的用户画像,需要先验知识的参与帮助进一步强化关键信息在用户画像中的作用。
技术实现思路
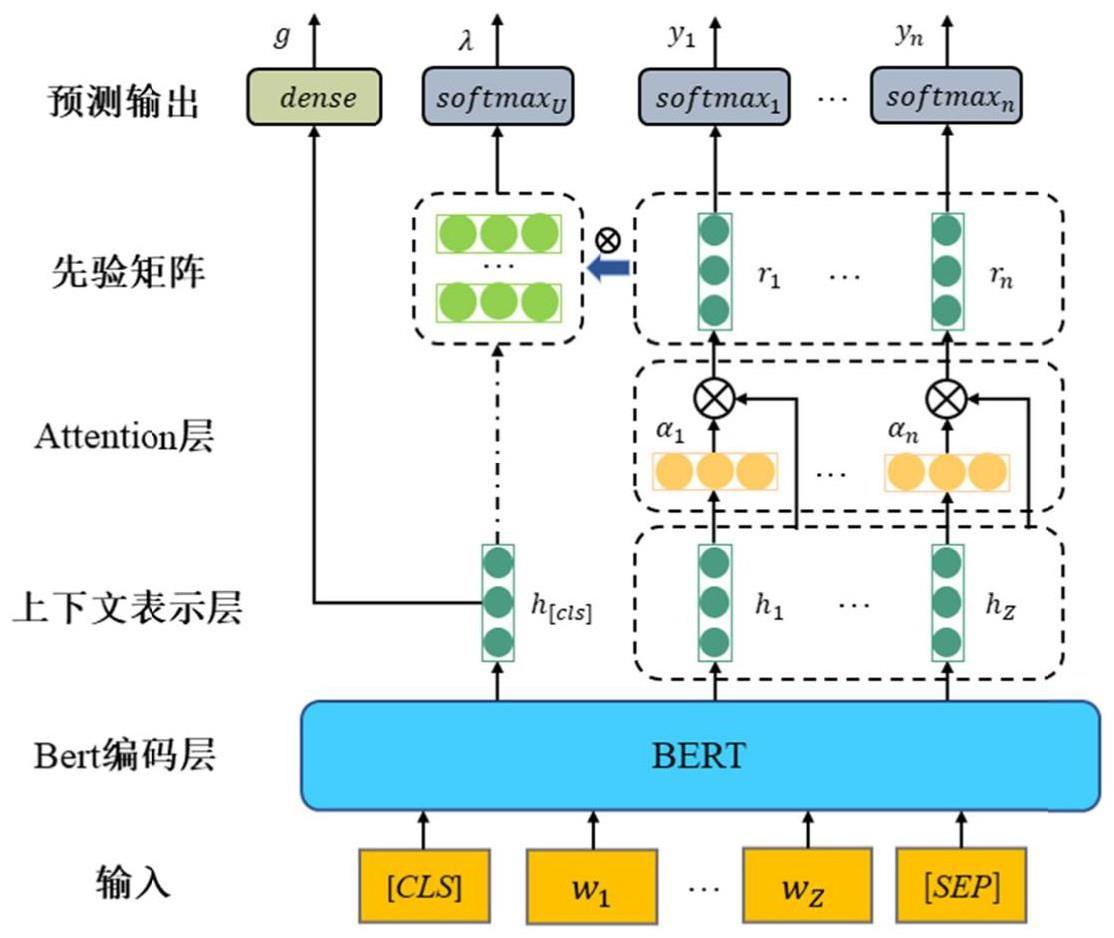
1、为了克服前文所述的挑战,本发明提出一种基于联合建模的多粒度情感分析方法,并依赖先验矩阵捕获关键信息实现用户精准画像。本专利涉及一种用于构建用户画像的方法,该方法使用bert作为公共编码层,为不同的情感分析提供文本嵌入表达。由于不同的方面类别信息分散在中评论r,为了动态聚合每个方面类别的相关词符的嵌入表达,模型增加了一个注意力池化层。注意力池化层可以帮助模型关注与目标方面类别相关性最高的词符。表示评论内容整体的[cls]表达,被用作总体情感预测任务的预测层输入;面向方面的情感极性判断依赖于经过注意力池化层重新聚合的信息方面文本表达;而其构成的整体还会通过由先验专家知识构成的降维矩阵计算后,被用作用户画像任务。
2、步骤1:加载待分析对象的评论文本数据集,并对数据集进行处理。
3、步骤1-1:对评论数据集采取去除英文、标点符号,并进行繁简转换统一为简体中文的操作;
4、步骤1-2:利用分词工具对评论文本进行分词;
5、步骤1-3:载入停用词词典,去除停用词。
6、步骤2:将处理过后的数据集输入bert得到文本表示。
7、步骤2-1:载入bert模型,表示维度设置为预训练模型缺省值;
8、步骤2-1:将分词结果句首添加[cls],该符号用于总体并将该符号对应的输出向量作为整篇文本的语义表示h[],用于下游文本分类任务,也由该表示构成先验矩阵;
9、步骤2-2:将每个词的文本表示结果输入上下文表示层,设置表示向量默认维度,得到的文本表示为hi;
10、步骤3:将h[]和hi针对不同的下游任务进行处理。
11、步骤3-1:文本表示层对所得的分词嵌入表达向量{h1,h2,…,hz}构成矩阵其中d代表向量的维度,z代表该句中词语的数量;
12、步骤4:将文本表达通过注意力池化层,为每个方面类别相关词符表达聚合上下文信息;
13、步骤4-1:注意力池化层的输入为表达矩阵依赖注意力机制可以聚焦与目标方面类别相关性最高的词符,从而将文本表达转化为针对具体方面的表达;
14、步骤4-1-1:将表达输入带参注意力池化层,通过网络实现参数学习,并利用激活函数将结果映射到所需空间中,其过程如下公式所示:
15、
16、其中是通过激活函数映射过后的中间参数,wia是需要被训练网络学习的参数;
17、步骤4-1-2:计算注意力权重,将前步骤的中间参数输入softmax激活函数后可以得到每个词符的注意力权重,该步骤的目的是更加准确的关注与方面类别词语相关性高的部分,计算过程如下公式所示:
18、
19、其中αi是通过注意力权重,是训练参数;
20、步骤4-1-3:基于注意力权重,重新对上下文表示层得到的结果进行加权计算,通过激活函数可以得到经过关于信息聚合后某一方面的表示结果,计算过程如下公式所示:
21、
22、其中ri是与第i个方面ai相关的评论文本表示,gi是门控函数,用于过滤掉没有提到第i个方面ai的值;
23、步骤5:基于先验知识构造先验矩阵,再利用先验矩阵对方面类别相关的文本表示进行变换。
24、步骤5-1:对于用户画像任务的先验矩阵,将特殊场景下的画像类标签为lk评论的h[cls]表示进行加和平均,对k个标签重复此步骤,构造先验矩阵p,其维度为d*k;
25、步骤5-2:将步骤4-1-3得到的ri所构成的矩阵mr与先验矩阵p进行计算并通过双曲正切激活函数tanh,得到mk:
26、mk=tanh(pt*mr)
27、步骤6:将计算得到的表达h[cls]、ri、mk分别用作下游预测任务的输入,如图1所示,可以被输入到三个下游任务,分别是总体评价预测任务、多方面情感预测任务,基于二者的用户画像任务。
28、步骤6-1:对面向方面的情感预测任务提供输入,并得到所需的预测值:
29、
30、是需要的得到的预测值,wiq和都是参数,是增强模型泛化能力的扰动;
31、步骤6-2:对特殊场景下先验知识参与计算的表示结果进行用户画像的预测:
32、
33、是预测参数,是增强泛化能力的扰动,是步骤5-2所得的全维度的文本表达。
34、步骤6-3:该任务的目标是利用步骤2-1中的h[cls]进行总体情感分析预测,其过程如下所示:
35、
36、表示预测的总体评分,βt为模型训练学习参数,wr表示关于评论r的参数,br是关于评论r偏差,这个分类任务依赖bert额外的隐藏层,通过激活函数tanh实现情感分类预测。
37、有益效果:
38、本发明能够作用于中文互联网商业平台和社交媒体平台。本发明提出多粒度情感联合建模分析方法,通过预训练语言模型和注意力机制相结合的方式,对文本表示效果进行优化。其计算结果经过多任务学习网络获得增益,方面词相对上下文关联性获得提高,从而显著提高了多方面情感分析和总体情感分析的预测准确率。本发明在以上创新应用于基于社交媒体的用户画像任务,利用总体情感表达词符所构造的先验矩阵,使得用户画像预测任务的预测准确度得到了大幅提升。
- 还没有人留言评论。精彩留言会获得点赞!