一种中文上位词检索方法及装置
本发明涉及自然语言处理,尤其是指一种中文上位词检索方法及装置。
背景技术:
1、现有上位词检索技术多用于英文领域。crim使用两种方法的结合来获得候选上位词,一种是改良的基于hearst模式的无监督上-下位词挖掘方法;另一种是在词嵌入上进行的基于软聚类(soft clustering)和投影学习的有监督上-下位词投影方法。vte使用有监督数据学习一个基于词向量的变换矩阵(transformation matrix),通过变换矩阵作用来获得候选上位词。bai等人提出一个循环投影模型(recurrent mapping model),该模型学习一个投影矩阵,使用该投影矩阵从下位词的词嵌入开始不断往更高层级投影来获得候选上位词。parmar和narayan的工作使用框嵌入(box embeddings)技术进行上位词检索,其思想为在词嵌入基础上学习框嵌入表示,并通过超矩形来表示英文上下位关系。
2、在中文领域,仅有少数工作开展了上位词检索。luo等人同样采用了英文上位词检索方法中的投影学习来进行上位词检索,然而,在中、英文语料中,使用基于投影学习的方法各项指标普遍不高。fu等人开展了中文上位词检索研究,通过远程监督的方式使用多个数据源(如搜索引擎)来获取给定下位词的上位词,该设定受外部数据源返回的结果影响较大,泛化性存在局限。
3、综上,现有的基于投影学习的方法在中、英文语料上的效果普遍不高;基于远程监督的方式受外部数据源影响大,存在局限性。
技术实现思路
1、为此,本发明所要解决的技术问题在于克服现有技术中中文上位词检索效果差的问题。
2、为解决上述技术问题,本发明提供了一种中文上位词检索方法,包括:
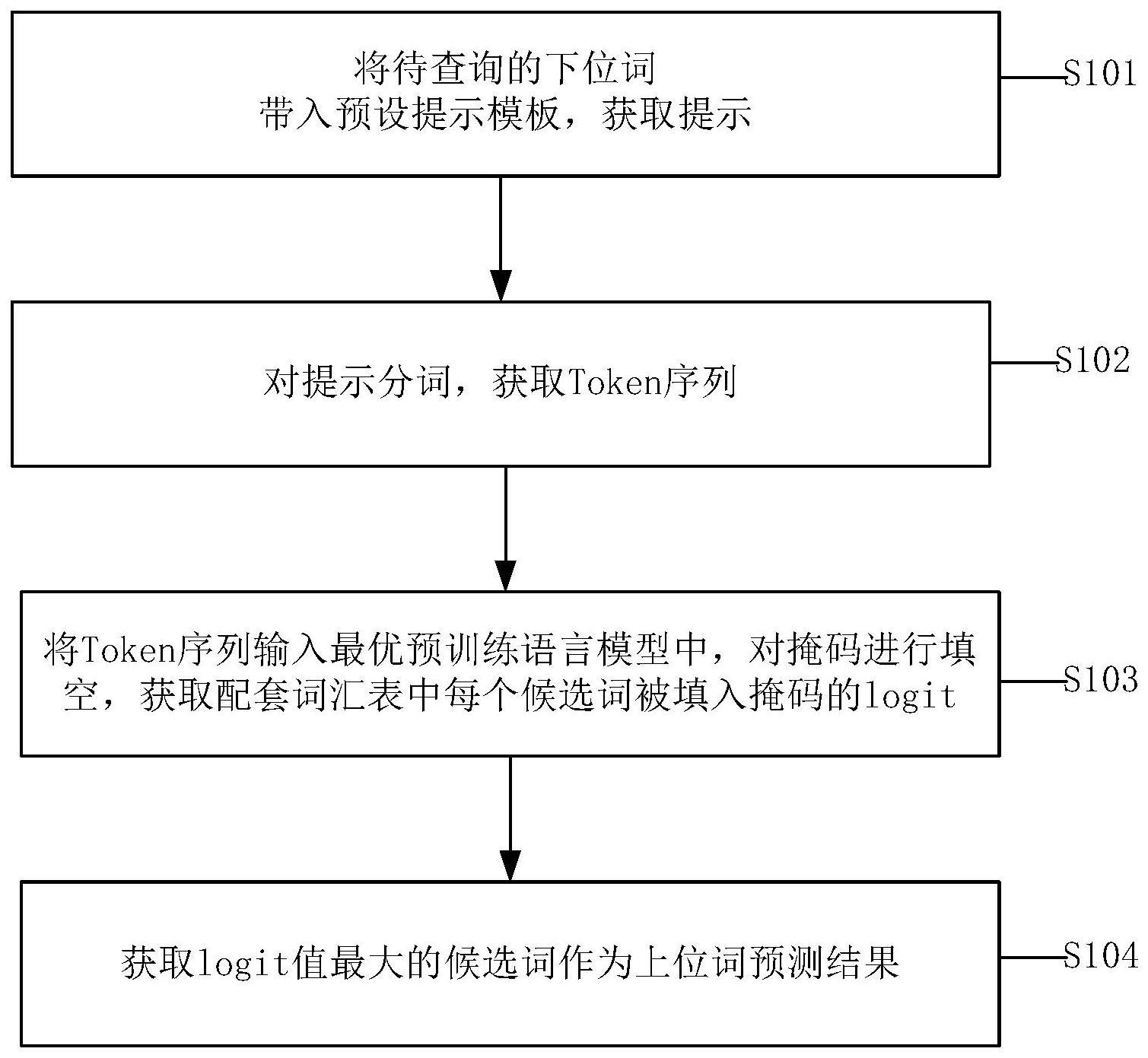
3、获取待查询下位词,带入预设提示模板中,得到含有掩码的待填空文本作为提示;
4、对所述提示进行分词,获取token序列;
5、将所述token序列输入最优预训练语言模型中,对所述掩码进行填空,计算所述预训练语言模型的配套词汇表中的每个候选词被填入掩码时的logit值;
6、获取logit值最大的候选词作为上位词预测结果。
7、在本发明的一个实施例中,所述计算所述预训练语言模型的配套词汇表中的每个候选词被填入掩码时的logit值后,还包括:
8、获取logit值最大的前k+1个候选词构建过渡候选词集;
9、若所述过渡候选词集中包含待查询下位词本身,则将该候选词舍弃,将后续位置处的候选词填补进所述过渡候选词集中;取过渡候选词集中的前k个候选词,作为候选上位词集。
10、在本发明的一个实施例中,所述获取logit值最大的前k+1个候选词构建过渡候选词集,还包括:
11、若所述过渡候选词集中不包含待查询下位词本身,则取过渡候选词集中的前k个候选词作为候选上位词集。
12、在本发明的一个实施例中,利用分词工具对所述提示进行分词;所述分词工具包括ltp、ictclas、jieba与thulac。
13、在本发明的一个实施例中,所述预训练语言模型包括roformer与wobert。
14、在本发明的一个实施例中,所述预训练语言模型的训练过程包括:
15、将样本数据中的下位词带入预设提示模板,获取提示;对所述提示进行分词,得到token序列;将所述token序列输入预训练语言模型中,计算配套词汇表中每个候选词被填入掩码的logit,获取logit值最大的候选词作为上位词预测结果;
16、计算所述上位词预测结果与真实上位词的交叉熵损失,最小化所述交叉熵损失,对所述预训练语言模型进行反向传播,获取最优预训练语言模型。
17、在本发明的一个实施例中,所述交叉熵损失的计算表达式为:
18、
19、其中,所述样本数据表示为(x,y1,…,yn),x表示待查询下位词,{y1,…,yn}为x的真实上位词集;i()表示指示函数,当变量表达式为真时,值为1,反之,值为0;表示最优预测结果,y表示真实上位词,x'表示提示。
20、本发明实施例还提供了一种中文上位词检索装置,包括:
21、提示构建模块,将数据样本的待查询下位词,带入预设提示模板中,获取含有掩码的待填空文本作为提示;
22、token序列生成模块,利用分词工具对所述提示进行分词,获取token序列;
23、掩码填空模块,将所述token序列输入预设的预训练语言模型中,对所述掩码进行填空,获取配套词汇表中每个候选词被填入掩码的logit;
24、上位词预测模块,获取配套词汇表中logit值最大的候选词作为上位词预测结果。
25、在本发明的一个实施例中,还包括:
26、提示调优模块,将上位词预测结果,与真实上位词计算交叉熵损失,最小化损失,对预训练语言模型进行反向传播,获取最优预训练语言模型。
27、在本发明的一个实施例中,还包括:
28、模型推理模块,用于获取logit值最大的前k+1个位置的候选词构建过渡候选词集;若所述过渡候选词集中包含待查询下位词本身,则将该候选词舍弃,将后续位置处的候选词填补进所述过渡候选词集中;取过渡候选词集中的前k个候选词,作为候选上位词集;若所述过渡候选词集中不包含待查询下位词本身,则取过渡候选词集中的前k个候选词作为候选上位词集。
29、本发明的上述技术方案相比现有技术具有以下优点:
30、本发明所述的中文上位词检索方法首次将提示调优引入中文上位词检索领域,上位词检索效果显著提升;基于任务适应性强的提示调优技术,利用一个预设的固定提示模板来训练预训练语言模型的中文上位词检索能力,由于预训练语言模型本身具备结合上下文对掩码进行填空的能力,通过设计恰当的提示模板来引导模型,可将预训练语言模型的填空能力转化成求解上位词的能力,从而提升预训练语言模型的上位词检索能力。本发明通过提示模板获取提示,进而引导预训练语言模型的推理过程,利用固定的提示模板,不断约束和规范模型的输出,使模型在遇到同样的提示时,能够激活学习到的推理规范,从而产生期望的预测结果,显著提升了中文上位词检索效果。
技术特征:
1.一种中文上位词检索方法,其特征在于,包括:
2.根据权利要求1所述的中文上位词检索方法,其特征在于,所述计算所述预训练语言模型的配套词汇表中的每个候选词被填入掩码时的logit值后,还包括:
3.根据权利要求2所述的中文上位词检索方法,其特征在于,所述获取logit值最大的前k+1个候选词构建过渡候选词集,还包括:
4.根据权利要求1所述的中文上位词检索方法,其特征在于,利用分词工具对所述提示进行分词;所述分词工具包括ltp、ictclas、jieba与thulac。
5.根据权利要求1所述的中文上位词检索方法,其特征在于,所述预训练语言模型包括roformer与wobert。
6.根据权利要求1所述的中文上位词检索方法,其特征在于,所述预训练语言模型的训练过程包括:
7.根据权利要求6所述的中文上位词检索方法,其特征在于,所述交叉熵损失的计算表达式为:
8.一种基于如权利要求1至7任一项所述的中文上位词检索方法的装置,其特征在于,包括:
9.根据权利要求8所述的中文上位词检索装置,其特征在于,还包括:
10.根据权利要求8所述的中文上位词检索装置,其特征在于,还包括模型推理模块,用于获取logit值最大的前k+1个位置的候选词构建过渡候选词集;若所述过渡候选词集中包含待查询下位词本身,则将该候选词舍弃,将后续位置处的候选词填补进所述过渡候选词集中;取过渡候选词集中的前k个候选词,作为候选上位词集;若所述过渡候选词集中不包含待查询下位词本身,则取过渡候选词集中的前k个候选词作为候选上位词集。
技术总结
本发明涉及一种中文上位词检索方法,包括获取待查询数据样本中的下位词,带入预设提示模板中,得到含有掩码的待填空文本作为提示;对所述提示进行分词,获取Token序列;将所述Token序列输入预设预训练语言模型中,对所述掩码进行填空,获取预设配套词汇表中每个候选词被填入掩码的logit;获取logit值最高的候选词作为所述预训练语言模型的上位词最优预测结果。本发明首次将提示调优引入中文上位词检索领域,基于任务适应性强的提示调优技术,利用一个预设的固定提示模板来训练预训练语言模型的中文上位词检索能力;通过提示模板获取提示,进而引导预训练语言模型的推理过程,利用固定的提示模板,不断约束和规范模型的输出,从而产生期望的预测结果,获取上位词。
技术研发人员:陆恒杨,周俊康,刘哲,方伟,孙俊,吴小俊
受保护的技术使用者:江南大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!