一种大区域滑坡危险性评价的并行DCNN分类方法
本发明涉及大数据挖掘和gis,特别是涉及一种大区域滑坡危险性评价的并行dcnn分类方法。
背景技术:
1、滑坡的频发威胁生命、财产安全,破坏自然环境和资源,其发生是指岩土体受到外界因素(降雨、地震、人为活动等)影响,沿一定的软弱面(带)做整体运动的现象,尤其雨季来临,降雨和人类工程活动诱发滑坡在许多点上同时或相续发生,其危害足以严重影响当地社会与经济发展。而区域滑坡危险性评价能减缓滑坡灾害造成的损失,它是滑坡防治工作的核心。
2、随着人工智能和地理信息技术的发展,许多研究者采用这些技术开展了大区域滑坡预测研究。早期,nadim等人、hong等人和cepeda等人以世界滑坡库中的滑坡为样本数据,分别采用加权线性组合的方法进行全球和印度尼西亚等地区的危险性评价;2013年,liu等人输入坡度、坡向、曲率等9个滑坡影响因子到神经网络算法中,进行中国地区滑坡危险性评价;2014年,gunther等人考虑坡度、地形、地质和土地覆盖为滑坡影响因子,采用层次分析法进行欧洲地区的危险性评价;kirschbaum和stanley等人分别于2016和2017年使用了不同的滑坡影响因子预测了中美洲和加勒比地区滑坡发生的可能性并描绘其危险性评价图。
3、综上所述,大区域滑坡危险性评价技术已经取得了许多成果,但这些方法仍存在一些问题:在arcgis软件中,根据1000×1000分辨率大小来提取斜坡单元的地质、地貌等数据,这显然不符合斜坡单元的地质、地貌特征,因为在实际应用中25×25左右的分辨率能很好映射一个斜坡的地质、地貌特征,1000×1000超大的分辨率将导致滑坡危险性评价精确度不高的问题;如果采用25×25左右的分辨率提取数据会产生数千万甚至更多的栅格单元数据,而单处理器系统的计算性能无法满足需求的处理速度,因此如何设计既能提高大区域滑坡危险性评价的预测精度,同时其处理速度满足实际应用的方法具有重大意义。
4、深度卷积神经网络(deep convolutional neural networks,dcnn)是深度学习算法中的一种重要分类算法,因其具有良好的平移不变性、泛化能力以及特征提取能力而被广泛用于滑坡小区域危险性评价、计算机视觉、图像分类、语音识别、语义分割、自然语言处理等领域。但是它的计算复杂度会随着数据量的增长呈指数级增加,且训练速度以及各种算法性能也会严重降低。因此,设计适用于处理大数据的dcnn方法才能适用于大区域滑坡危险性评价需求。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种大区域滑坡危险性评价的并行dcnn分类方法。
2、为了实现本发明的上述目的,本发明提供了一种大区域滑坡危险性评价的并行dcnn分类方法,括以下步骤:
3、s0,获取待处理的滑坡数据;
4、s1,对卷积层中的特征图进行分组合并,实现特征图压缩;解决了训练过程中冗余特征图过多的问题;
5、s2,模型并行训练中,在给定的分类准确度损失范围内寻找最优的近似卷积核替代原卷积核,以此来降低卷积核中的无效参数,进而克服了卷积运算效率低下的问题;
6、s3,对模型并行训练过程中产生的各种中间数据进行均匀分配,有效地解决了节点负载不均衡的问题。
7、s4,根据步骤s1~s3的处理得到其滑坡结果。
8、进一步地,所述s1包括:
9、s1-1,特征图重构:对输入特征图集合g进行重新排序,通过奇异值分解将特征图重构为含更多有效信息的两部分特征图集合;
10、s1-2,冗余特征图过滤:根据js散度过滤掉特征图中存在的冗余特征图;
11、s1-3,特征图合并:对两部分特征图集合执行合并操作,从而消除了卷积层中冗余特征图过多的问题。
12、进一步地,所述s1-1包括:
13、首先,采用基于奇异值分解的信息量权重wiq来得到各个特征图之间的关联性,计算特征图集合g中各个特征图对应的wiq数值,按照wiq数值的大小对特征图集合g中的各个特征图降序排序;
14、其次,把排序后的集合top作为特征图合并时的顶层特征图集合,top作为包含主要特征的顶层特征图集合,top复制后的集合bottom作为特征图合并时的底层特征图集合;然后,令top中的特征图xi=wiqi·xi+wiqn-i-1·xn-i-1,bottom中的特征图yi=yi·wiqn-i+1+yn-i+1·wiqi,得到重构后的两组特征图集合;
15、最后,分别将top和bottom中的加权特征图分为数量相等的上下两部分,将这两部分的特征图直接进行相加,最终得到的top和bottom的重构特征图,重构特征图中的有效特征含量大幅提升,并且参数数量减少为原来的一半。
16、进一步地,所述s1-2包括:
17、首先,计算集合top对应的均值特征图矩阵e;
18、然后,采用基于js散度的特征相关系数fcc,根据集合top中各特征图对应的fcc数值来评估当前特征图与其它特征图之间的相似程度;
19、最后,计算当前特征图与其它特征图之间的fcc差值,如果该值小于或等于阈值η则将当前特征图划入冗余特征图集合r中,否则保留在集合top中。
20、进一步地,所述s1-3包括:
21、首先,从底层特征图集合bottom和冗余特征图集合r中各取一张特征图x和y,分别求出它们对应特征矩阵的期望和方差;
22、接着,采用图像融合函数mf(x,y)来对冗余特征图y与底层特征图x进行加权融合;
23、最后,使用1×1卷积核将底层特征图集合bottom中特征图数量压缩为原来的一半,并将压缩后的底层特征图集合bottom与顶层特征图集合top合并为一组来作为输出特征图o。
24、进一步地,所述s2包括:
25、s2-1,参数初始化:对模型中的各项参数进行初始化,以便加快模型参数的收敛速度;
26、s2-2,并行cp分解:对各并行节点中的卷积核执行cp分解,用分解后的小卷积核替代原卷积核进行卷积操作;
27、s2-3,最优秩求解:通过自适应的蝴蝶优化算法来寻找cp分解的最优近似秩组合。
28、进一步地,所述s2-1包括:
29、首先采用权重初始化函数kwi(x)来初始化各层卷积核的权值矩阵l表示卷积层序号,ω表示卷积层的总数;
30、然后将特征图和其对应的卷积核映射为键值对存储到hdfs中;
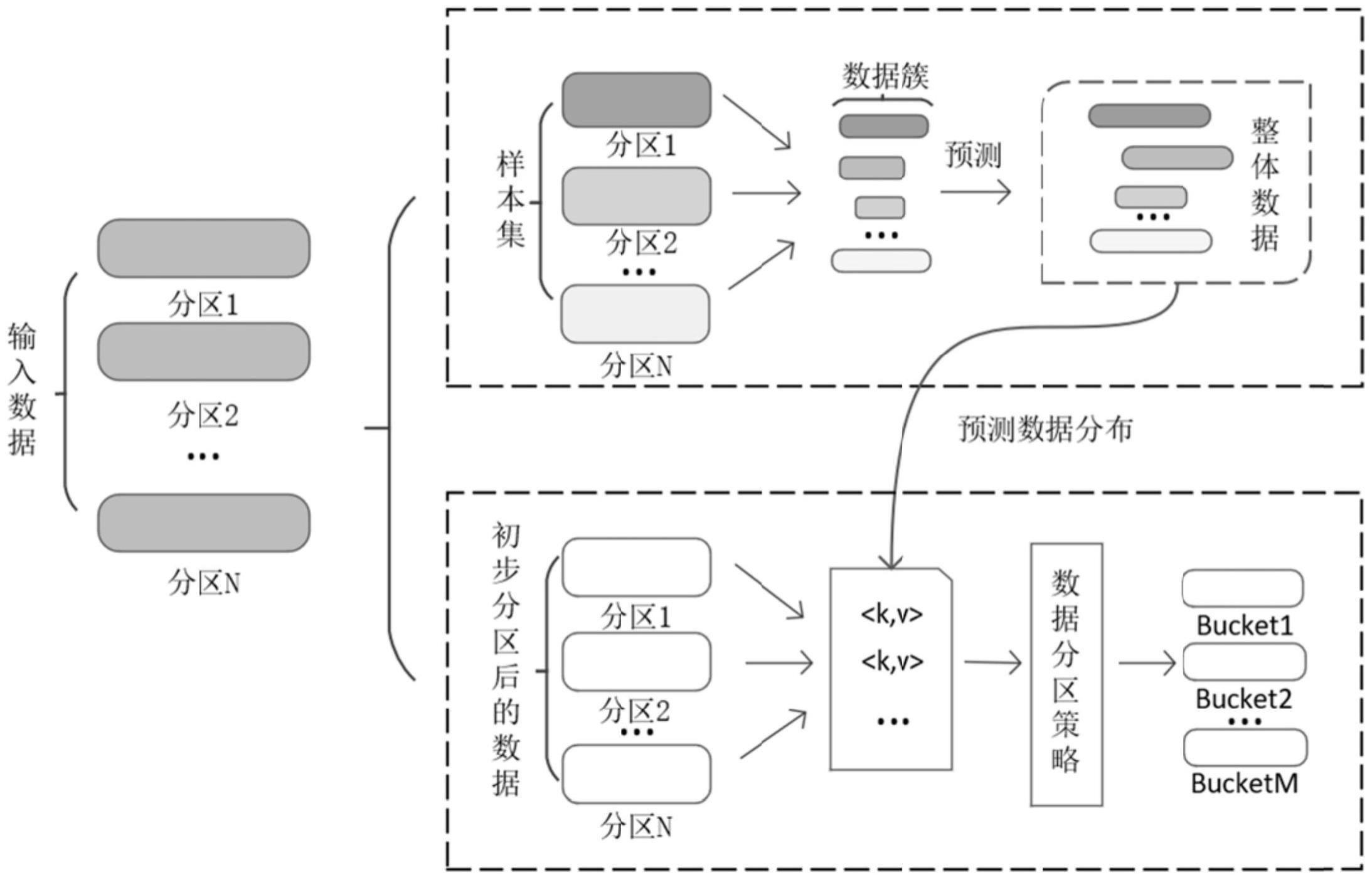
31、最后对权值更新公式中的学习率μ进行初始化赋值,并采用准确率最大损失比η来表示cp分解带来的精度损失;
32、在使用cp分解对dcnn模型进行并行训练之前,通过对模型的卷积核以及其它一些变量进行初始化,提高了各节点模型训练的收敛速度。
33、进一步地,所述s2-2包括:
34、s2-2-1,cp分解:首先将当前批次的输入图像数据xl等大小切块为子图像并将这些子图像转化为文件块存储到hdfs中;然后通过parallelcollectionrdd算子对子图像进行分区,并将它们均匀地分布到集群的各个节点中;最后选取近似秩ranki对各个节点的卷积核执行cp分解,对分解所得到的因子矩阵进行缺失维度的补充后便可得到近似的小卷积核k1,k2,k3,k4;通过对卷积核kl进行cp分解能减少卷积核的冗余参数;
35、s2-2-2,并行卷积运算:通过mappatitionsrdd算子在各个分区中执行并行卷积运算,首先将待处理的图像块依次与卷积核k1,k2,k3,k4进行卷积运算得到对应的卷积结果接着调用shuffledrdd算子对各分区中得到的中间结果进行重排以便后续的合并;最后调用reducebykey算子对各分区中所得到的中间结果进行合并从而得到输出特征图nyl,再将其存入内存中以便参数更新时进行使用;
36、s2-2-3,参数更新:首先计算当前节点的第l层的权值对应的梯度值然后通过reducebykey算子合并各节点中的的梯度值得到合并后的梯度gl;最后通过反向传播的权值更新公式对第l-1层的卷积核权值进行更新,更新后的结果全部存储到rdd中。
37、进一步地,所述s3包括:
38、s3-1,评估数据状态:通过采样的方法估算中间数据中不同簇所含键值对的数量;
39、s3-2,数据倾斜修正:使用簇分割方法来将中间数据均匀地分配到各个节点的桶中;
40、s3-3,节点参数合并:估算各节点的计算能力,将桶分配到适合的节点中进行数据处理。
41、进一步地,所述s3-1包括:
42、首先,获取模型并行训练阶段的中间输出数据中所包含的键值对<keyi,valuej>集合;接着计算经过当前数据分区后对应的数据偏差系数dcf,当dcf小于设定的阈值时认为当前数据分区较为合理,可以执行reducebykey操作来合并节点参数,反之认为中间数据严重倾斜,需要重新对数据进行分区;
43、采用数据偏差系数dcf来获取每个桶中数据量对应的倾斜度,有助于度量数据分区的总体偏差。
44、进一步地,所述s3-2包括:
45、(1)采用并行的水池抽样算法来估算整体数据的分布,获取数据分布:首先将样本集sample的容量设置为r,对待处理键值对执行单次扫描操作,将扫描到的前r个元素加入sample中;然后对剩余的k个数据(k>r)按照概率r/k来替换到s的元素;最后获取输入数据中键值对的总量w并计算其与样本集的容量r之间的比值η,再统计样本集中各数据簇scj所包含键值对的数量,将cj=scj×η作为总体数据簇中的每一个元素的估计值,cj表示中间数据中的第j个数据簇,scj表示sample中各数据簇包含的数据量,m表示总体数据簇个数;
46、(2)在得到数据分布的估计值之后,对数据重新分区:首先令数据总量w除以设定的桶数n作为各个桶中可以容纳的平均数据量wavg,依次将每个桶bi的初始容量设置为wavg;然后将待分配数据簇按照所含数据量从大到小进行排序,从第一个桶b1开始依次遍历排序之后的数据簇cj,如果数据簇cj对应的数据量n(cj)大于当前桶的容量n(bi),则将cj中未超出桶容量的部分全部存入桶中,而超出的部分则将数据量设置为n(cj)=n(cj)-n(bi)并重新作为一个簇放入簇队列中,否则将数据簇cj中的数据全部存入桶中,此时桶的容量更新为n(bi)=n(bi)-n(ci),n(·)表示数据簇对应的数据量;;最后,依次对集群中的每一个桶执行上述步骤,直到各个数据簇cj全部存入对应的桶中便可输出最终的分区结果;通过将各个簇合理地分配到对应的桶中,从而修正数据倾斜的情况。
47、进一步地,所述s3-3包括:
48、1)首先,规定前λ-1轮依次分配t个数据桶,第λ轮分配n-t×(λ-1)个数据桶,将所有桶按照容纳数据量的大小顺序排序;n表示设定的桶数。
49、2)其次,采用节点计算能力ncp来评估各节点的数据处理能力,将所有节点按照ncp值从小到大重新排序,将容纳数据量较少的桶分配给ncp值较小的reducer(归约器,负责合并key值相同的<keyi,valuei>),将容纳数据量较多的桶分配给ncp值较大的reducer;
50、3)最后,使用reducebykey算子来将各个节点输出的键值对并行合并,并将合并后的参数作为dcnn模型的经过训练后的最终参数值。
51、综上所述,由于采用了上述技术方案,本发明能够显著提升dcnn模型在大数据环境下的训练效率,同时在大型图像数据集上表现出良好的可扩展性。具有以下优点:
52、(1)通过基于奇异值分解与js散度的特征压缩策略fc-svdjs来对卷积层中的特征图进行分组合并,从而解决了训练过程中冗余特征图过多的问题;
53、(2)结合spark提出了基于自适应蝴蝶优化的并行cp分解策略pcp-aboa,在给定的分类准确度损失范围内寻找最优的近似卷积核替代原卷积核,以此来降低卷积核中的无效参数,进而克服了卷积运算效率低下的问题;
54、(3)通过基于簇分割的数据分区策略dp-cs,将中间数据合理地分配到各节点的桶中,有效地解决了节点负载不均衡的问题。
55、本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!