商品的多标签自动分类方法及系统与流程
本发明涉及电商信息,具体地,涉及一种商品的多标签自动分类方法及系统。
背景技术:
1、通常情况下,商品的属性划分是存在交叉的,不同的分类考虑角度会造成不同的分类结果,例如从用途的分类和从材质的分类,而常见的商品分类方法只能分到唯一的类别下,与实际情况不符,进而会造成下游任务的失效,如基于商品类别的搜索结果缺失等问题。
2、专利文献cn113792786a(申请号:cn202111073371.9)公开了一种商品对象自动分类方法及其装置、设备、介质、产品,所述方法包括:获取商品对象,提取其相对应的摘要文本及商品图片;分别对所述摘要文本及所述商品图片进行特征提取,相应获得文本特征向量及图片特征向量,将文本特征向量与图片特征向量拼接为综合特征向量;基于所述综合特征向量进行多层次分类处理,获得所述商品对象相对应的标签集,所述标签集包括多层次分类结构中多个构成层次隶属关系的分类标签;为所述商品对象标记所述标签集中的各个分类标签。但该发明没有解决商品信息与类别不正交的情况。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种商品的多标签自动分类方法及系统。
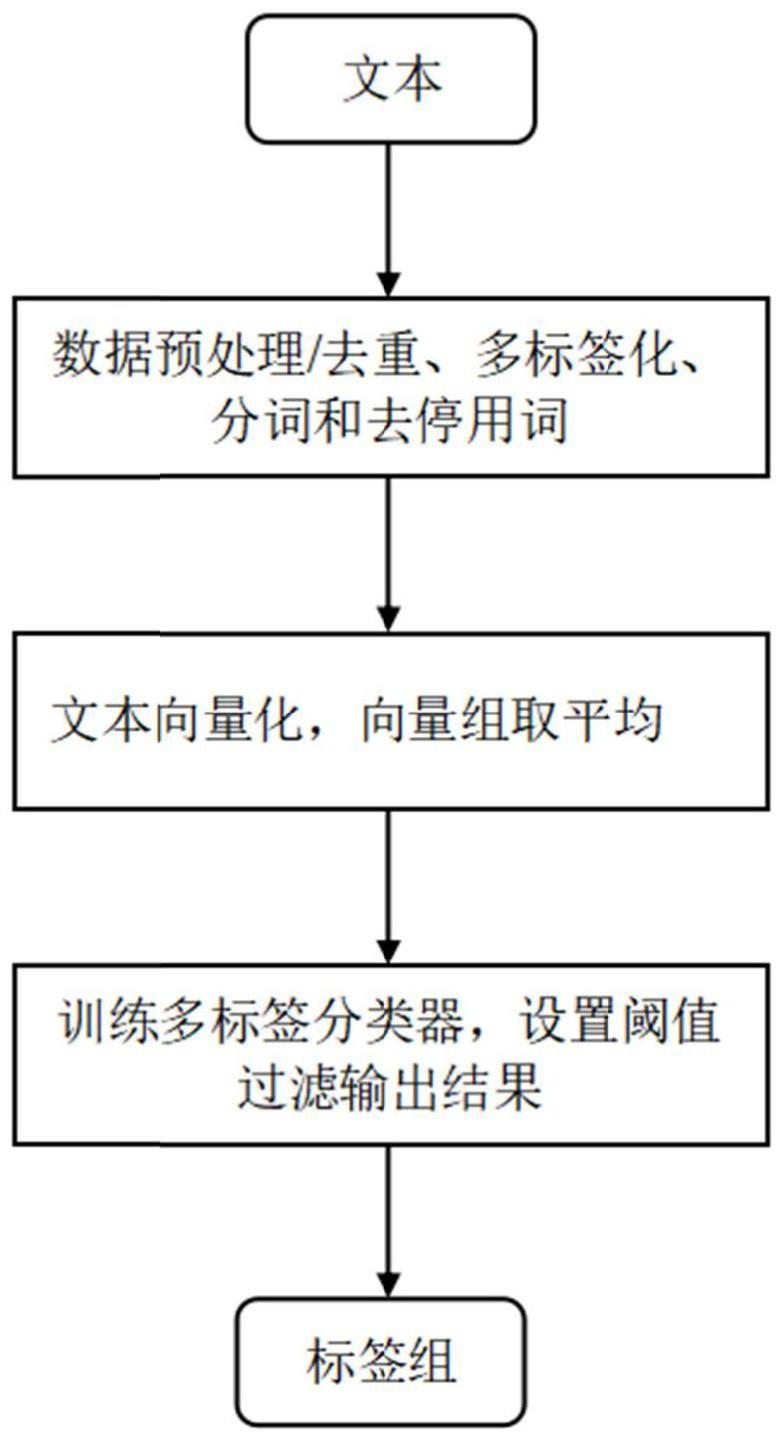
2、根据本发明提供的一种商品的多标签自动分类方法,包括:
3、步骤s1:进行数据预处理,对数据进行去重,形成多标签数据,对描述信息进行分词和去停用词,保留与分类相关性高于预设标准的有效词组;
4、步骤s2:将有效词组转化为向量,对向量组计算平均值,得到特征向量;
5、步骤s3:将特征向量及其所属的多标签数据作为学习样本,训练多标签分类器,设置阈值过滤输出结果。
6、优选地,在所述步骤s1中:
7、对描述信息和类别完全重复的数据进行去重,保留一条数据,将相同描述信息对应不同类别的数据进行标签合并,形成多标签数据;对描述信息进行分词和去停用词操作,保留与分类相关性高于预设标准的有效词组;
8、去重:对于商品描述信息和所属类别完全相同的商品数据,只保留一条,其余删除;
9、标签合并:对于商品描述信息相同,但所属类别不同的数据,合并为一条,类别信息为该商品所属的全部类别的集合;
10、分词:将连续的字序列按照预设规范重新组合成词序列;
11、去停用词:加载本地的停用词词典,停用词词典的内容是与商品描述信息无关的字词,扫描分词结果中的词组,若是停用词表中的内容,则从分词结果中删除该词。
12、优选地,在所述步骤s2中:
13、将有效词转化为向量表示,对由词组得到的向量组进行平均处理,得到能够进行机器计算的特征向量;
14、采用word2vec编码方式里的cbow模式,cbow根据上下文预测目标词训练得到词向量,cbow的学习过程如下:
15、输入层:目标单词上下文的t个单词,每个单词用one-hot编码表示,为1×v大小的矩阵,v表示词汇大小;
16、将t个词的one-hot矩阵乘以输入权重矩阵w;其中,w是v*n大小的共享矩阵,n是指输出的词的向量维数;将目标单词上下文的单词经过特征向量按维度求平均值,作为隐层向量h,h大小为1×n;将隐层向量h乘以输出权重矩阵w′得到向量y,其中,w′是n×v大小的共享矩阵,y大小为1×v,利用softmax激活函数处理向量y,得到v-dim概率分布;v-dim概率分布中,概率最大的指标所指代的单词为预测出的目标词;将结果与真实标签的one-hot进行比较。
17、优选地,在所述步骤s3中:
18、采用有监督的学习方式,将特征向量及特征向量所属的多标签作为学习样本,对于多标签的学习任务,x=rd表示d维特征向量的输入空间,r表示集合中的数都属于实数,y={y1,y1,…,yn}表示有n种标签空间;训练集d=(xi,yi)|1≤i≤m,m表示训练集的样本数量,通过学习多标签分类器h(·),预测作为x的正确标签集;先学习分类器f(x,yj),其中,1≤j≤n,使得f(x,yj1)>f(x,yj2),其中yj1∈ytrue,
19、h(x)={yj|f(x,yj)>t(x),yj∈ytrue}
20、t(x)则为阈值函数,把标签空间分为相关标签集和不相关标签集,阈值函数通过训练集产生,阈值函数为常数,输出概率高于阈值函数的类别,使用基于bert的网络结构实现分类。
21、优选地,在模型训练阶段采用五折交叉验证,将数据平分成5个部分,每个部分为1折,共进行5轮训练,每轮训练拿1折数据做为验证样本,其余4折数据用做训练,求5轮验证结果的平均值作为最终的验证结果。
22、根据本发明提供的一种商品的多标签自动分类系统,包括:
23、模块m1:进行数据预处理,对数据进行去重,形成多标签数据,对描述信息进行分词和去停用词,保留与分类相关性高于预设标准的有效词组;
24、模块m2:将有效词组转化为向量,对向量组计算平均值,得到特征向量;
25、模块m3:将特征向量及其所属的多标签数据作为学习样本,训练多标签分类器,设置阈值过滤输出结果。
26、优选地,在所述模块m1中:
27、对描述信息和类别完全重复的数据进行去重,保留一条数据,将相同描述信息对应不同类别的数据进行标签合并,形成多标签数据;对描述信息进行分词和去停用词操作,保留与分类相关性高于预设标准的有效词组;
28、去重:对于商品描述信息和所属类别完全相同的商品数据,只保留一条,其余删除;
29、标签合并:对于商品描述信息相同,但所属类别不同的数据,合并为一条,类别信息为该商品所属的全部类别的集合;
30、分词:将连续的字序列按照预设规范重新组合成词序列;
31、去停用词:加载本地的停用词词典,停用词词典的内容是与商品描述信息无关的字词,扫描分词结果中的词组,若是停用词表中的内容,则从分词结果中删除该词。
32、优选地,在所述模块m2中:
33、将有效词转化为向量表示,对由词组得到的向量组进行平均处理,得到能够进行机器计算的特征向量;
34、采用word2vec编码方式里的cbow模式,cbow根据上下文预测目标词训练得到词向量,cbow的学习过程如下:
35、输入层:目标单词上下文的t个单词,每个单词用one-hot编码表示,为1×v大小的矩阵,v表示词汇大小;
36、将t个词的one-hot矩阵乘以输入权重矩阵w;其中,w是v*n大小的共享矩阵,n是指输出的词的向量维数;将目标单词上下文的单词经过特征向量按维度求平均值,作为隐层向量h,h大小为1×n;将隐层向量h乘以输出权重矩阵w′得到向量y,其中,w′是n×v大小的共享矩阵,y大小为1×v,利用softmax激活函数处理向量y,得到v-dim概率分布;v-dim概率分布中,概率最大的指标所指代的单词为预测出的目标词;将结果与真实标签的one-hot进行比较。
37、优选地,在所述模块m3中:
38、采用有监督的学习方式,将特征向量及特征向量所属的多标签作为学习样本,对于多标签的学习任务,x=rd表示d维特征向量的输入空间,r表示集合中的数都属于实数,y={y1,y1,…,yn}表示有n种标签空间;训练集d=(xi,yi)|1≤i≤m,m表示训练集的样本数量,通过学习多标签分类器h(·),预测作为x的正确标签集;先学习分类器f(x,yj),其中,1≤j≤n,使得f(x,yj1)>f(x,yj2),其中yj1∈ytrue,
39、h(x)={yj|f(x,yj)>t(x),yj∈ytrue}
40、t(x)则为阈值函数,把标签空间分为相关标签集和不相关标签集,阈值函数通过训练集产生,阈值函数为常数,输出概率高于阈值函数的类别,使用基于bert的网络结构实现分类。
41、优选地,在模型训练阶段采用五折交叉验证,将数据平分成5个部分,每个部分为1折,共进行5轮训练,每轮训练拿1折数据做为验证样本,其余4折数据用做训练,求5轮验证结果的平均值作为最终的验证结果。
42、与现有技术相比,本发明具有如下的有益效果:
43、1、本发明提出了一种多标签分类方法,允许商品被划分到多个相关类别下,具有更高的使用价值;
44、2、本发明通过多标签分类的方法,解决了商品信息与类别不正交的情况,使分类结果具有多样性,更能满足实际应用需求;
45、3、本发明考虑到商品数据分布不均匀问题,采用数据增强和五折交叉验证的方式,提升模型泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!