一种模型训练方法及其相关设备与流程
本技术实施例涉及人工智能(artificial intelligence,ai),尤其涉及一种模型训练方法及其相关设备。
背景技术:
1、随着ai技术的飞速发展,生成流模型被广泛应用于描述和解决智能体(agent)在与环境的交互过程中的动作策略选择,从而令智能体在执行相应的动作后能够实现回报最大化或实现特定目标。
2、目前,相关技术提供的生成流模型,在确定某个智能体处于目标状态后,可对与该智能体所处的目标状态相关联的信息进行处理,从而预测出该智能体的一个或多个动作的发生概率,这些智能体的动作用于令该智能体从目标状态进入目标状态的一个或多个下一状态。如此一来,该智能体可执行神经网络模型预测得到的发生概率最大的动作,从而进入目标状态的某个下一状态。
3、上述生成流模型通常采用的是在线训练模式,也就是说,在对模型进行训练的过程中,对于智能体的任意一个状态,模型可在环境仿真器中,将预测得到的动作应用于该状态,从而随机生成智能体的下一状态。这样的训练模式虽然能够令模型尽可能地学习到智能体的所有状态,但是有些状态不够贴合智能体所在的实际环境,导致训练得到的生成流模型的性能较为一般。
技术实现思路
1、本技术实施例提供了一种模型训练方法及其相关设备,以离线训练模式来训练得到生成流模型,这样可以使得生成流模型具备更优秀的性能。
2、本技术实施例的第一方面提供了一种模型训练方法,该方法包括:
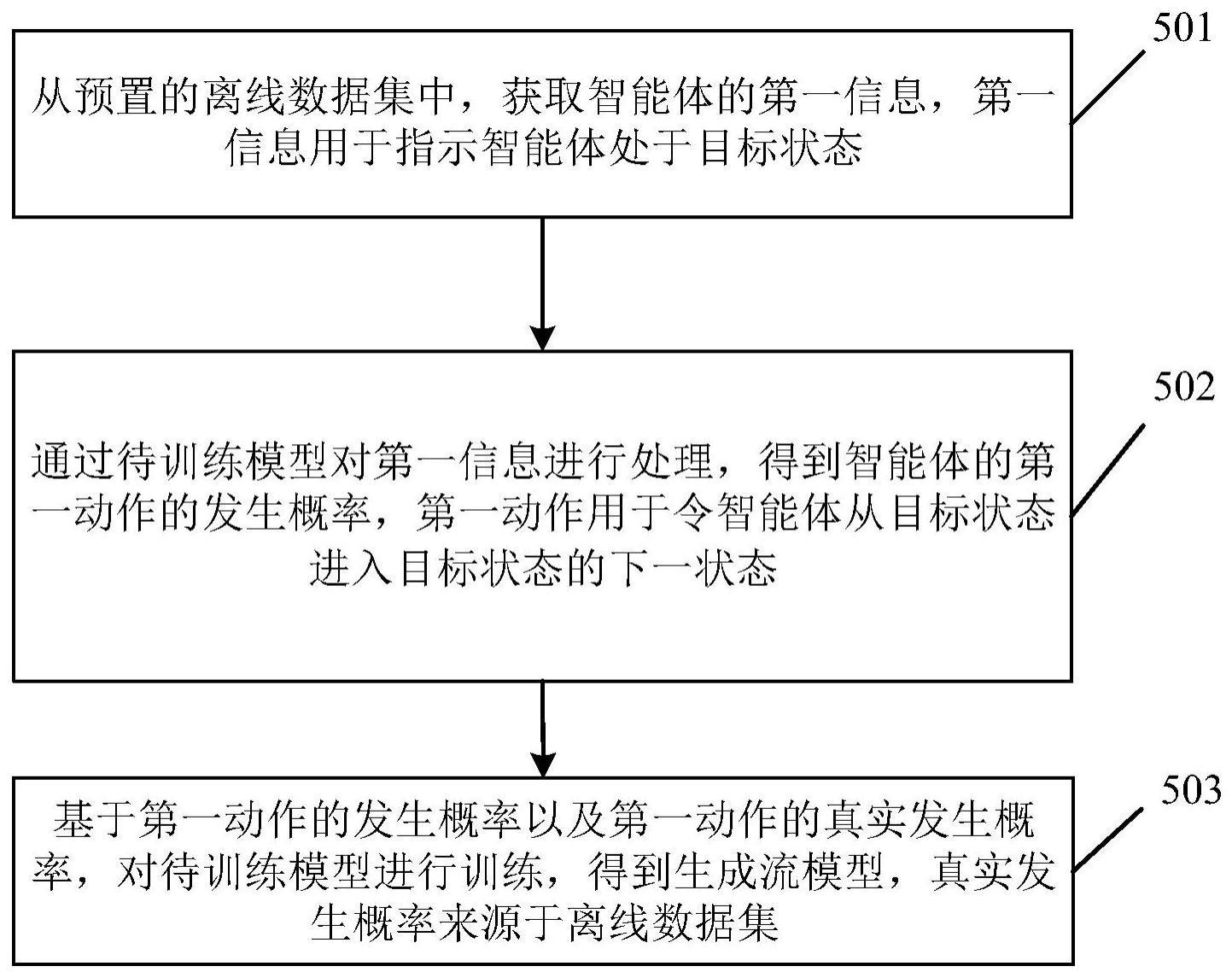
3、当需要对待训练模型进行训练时,可先获取预置的离线数据集,并从离线数据集中提取第一信息,第一信息用于指示智能体处于目标状态。
4、得到第一信息后,可将第一信息输入至待训练模型,以通过待训练模型对第一信息进行处理,从而得到智能体的第一动作的(预测)发生概率,第一动作用于令智能体从目标状态进入目标状态的下一状态。至此,待训练模型则完成了针对目标状态的动作预测。在一种可能实现的方式中,待训练模型在获取智能体的第一动作的发生概率时,可以尽可能地遵循以下约束条件:令智能体的第一动作的发生概率与智能体的第一动作的真实发生概率之间的差异位于预置的范围内,其中,智能体的第一动作的真实发生概率可从离线数据集中提取。
5、得到智能体的第一动作的发生概率后,可基于智能体的第一动作的发生概率,对待训练模型进行训练,直至满足模型训练条件,从而得到生成流模型。
6、从上述方法可以看出:当需要对待训练模型进行训练时,可先从预置的离线数据集中获取智能体的第一信息,第一信息用于指示智能体处于目标状态。然后,可将第一信息输入至待训练模型,以通过待训练模型对第一信息进行处理,从而得到智能体的第一动作的发生概率,第一动作用于令智能体从目标状态进入目标状态的下一状态。最后,可基于智能体的第一动作的发生概率以及第一动作的真实发生概率,对待训练模型进行训练,从而得到生成流模型,第一动作的真实发生概率来源于所述离线数据集。前述过程中,智能体的第一动作的发生概率可以称为待训练模型针对目标状态的预测动作策略,智能体的第一动作的真实发生概率可以称为离线数据库中针对目标状态的真实动作策略,这样可以令针对目标状态的预测动作策略尽可能地贴合针对目标状态的真实动作策略,而针对目标状态的真实动作策略决定了智能体从目标状态进入目标状态的下一状态的真实概率,故待训练模型不仅可以尽可能多地学习到目标状态的各个下一状态,且学习到的状态足够符合智能体所在的实际环境(因为离线数据集中的数据,均是基于智能体所在的实际环境提前设置的),那么,以离线训练模式训练得到的生成流模型,可以具备更优秀的性能。
7、在一种可能实现的方式中,基于第一动作的发生概率,对待训练模型进行训练,得到生成流模型包括:基于离线数据集,对智能体的第二动作的发生概率进行修正,得到第二动作的修正后的发生概率,第二动作用于令智能体从目标状态的前一状态进入目标状态;基于离线数据集,对目标状态对应的奖励值进行修正,得到目标状态对应的修正后的奖励值;基于第一动作的发生概率,第二动作的修正后的发生概率以及与目标状态对应的修正后的奖励值,对待训练模型进行训练,得到生成流模型。前述实现方式中,得到智能体的第一动作的发生概率后,还可获取智能体的第二动作的发生概率,智能体的第二动作用于令智能体从目标状态的前一状态进入目标状态。需要说明的是,由于待训练模型已经完成了针对目标状态的前一状态的动作预测,故可直接获取智能体的第二动作的发生概率。那么,可利用离线数据集中的一些数据,对智能体的第二动作的发生概率进行修正,从而得到智能体的第二动作的修正后的发生概率。得到智能体的第一动作的发生概率后,还可从离线数据集中获取目标状态对象的奖励值,并利用离线数据集中的一些数据对目标状态对应的奖励值进行修正,得到目标状态对应的修正后的奖励值。得到智能体的第二动作的修正后的发生概率以及目标状态对应的修正后的奖励值后,可对智能体的第一动作的发生概率,智能体的第二动作的修正后的发生概率以及与目标状态对应的修正后的奖励值,对待训练模型进行训练,从而得到生成流模型。
8、在一种可能实现的方式中,离线数据集包括m个第一候选信息以及m个第二候选信息,第i个第一候选信息用于指示智能体处于第i个候选状态,第i个第二候选信息用于指示智能体处于第i个候选状态的前一状态,m个第一候选信息包括第一信息,m个第二候选信息包含第二信息,第二信息用于指示智能体处于目标状态的前一状态,m个候选状态包含目标状态,m≥1;基于离线数据集,对智能体的第二动作的发生概率进行修正,得到第二动作的修正后的发生概率包括:基于第一信息、第二信息、m个第一候选信息以及m个第二候选信息,对智能体的第二动作的发生概率进行修正,得到第二动作的修正后的发生概率。前述实现方式中,离线数据集包含m个数据组,第1个数据组包含第1个第一候选信息、第1个第二候选信息、第1个第三候选信息、第1个候选状态对应的奖励值以及第1个真实动作策略。以此类推,第m个数据组包含第m个第一候选信息、第m个第二候选信息、第m个第三候选信息、第m个候选状态对应的奖励值以及第m个真实动作策略。那么,可从m个数据组中选择其中一个,将该数据组中的第一候选信息称为第一信息,将该数据组中的第一候选信息所指示的候选状态称为目标状态,将该数据组中的的第二候选信息称为第二信息。由此可见,第一信息用于指示智能体处于目标状态,第二信息用于指示智能体处于目标状态的前一状态,且智能体的第一动作的真实发生概率是已知的(来源于相应的真实动作策略)。如此一来,可从离线数据库中提取m个第一候选信息以及m个第二候选信息,并对第一信息、第二信息、m个第一候选信息以及m个第二候选信息进行计算,得到针对目标状态的新转换值。然后,利用针对目标状态的新转换值对智能体的第二动作的发生概率进行修正,从而得到第二动作的修正后的发生概率。
9、在一种可能实现的方式中,离线数据集还包括m个候选状态对应的奖励值,基于离线数据集,对目标状态对应的奖励值进行修正,得到目标状态对应的修正后的奖励值包括:基于第一信息、m个第一候选信息以及m个候选状态对应的奖励值,对目标状态对应的奖励值进行修正,得到目标状态对应的修正后的奖励值。前述实现方式中,还可从离线数据库中提取m个第一候选信息以及m个候选状态对应的奖励值,并对第一信息、m个第一候选信息以及m个候选状态对应的奖励值进行计算,从而得到目标状态对应的修正后的奖励值。
10、在一种可能实现的方式中,第一信息为智能体处于目标状态时所采集的信息,信息包含以下至少一项:图像、视频、音频或文本。
11、本技术实施例的第二方面提供了一种动作预测方法,该方法通过第一方面或第一方面中任意一种可能实现的方式中的生成流模型实现,该方法包括:获取智能体的信息,信息用于指示智能体处于目标状态;通过待训练模型对信息进行处理,得到智能体的动作的发生概率,动作用于令智能体从目标状态进入目标状态的下一状态。
12、从上述方法可以看出:当智能体当前处于目标状态时,为了预测令自身进入从目标状态进入目标状态的下一状态的动作,智能体可先采集用于指示智能体处于目标状态的信息。得到自身的信息后,智能体可将自身的信息输入至设于生成流模型中,以通过生成流模型对自身的信息进行处理,从而得到智能体的一个或多个动作的发生概率。那么,智能体可在一个或多个动作中,选择发生概率最大的动作,并执行该动作,以进入目标状态的某一个下一状态。前述过程中,由于智能体内置有生成流模型,可基于完成动作预测和动作执行,从而准确完成自身在不同状态之间的转换。
13、本技术实施例的第三方面提供了一种动作预测方法,该方法包括:获取智能体的信息,信息用于指示智能体处于目标状态;通过待训练模型对信息进行处理,得到智能体的动作的发生概率,动作用于令智能体从目标状态进入目标状态的下一状态。基于动作的发生概率基于预置动作的发生概率,确定待执行的动作。
14、从上述方法可以看出:当智能体当前处于目标状态时,为了预测令自身进入从目标状态进入目标状态的下一状态的动作,智能体可先采集用于指示智能体处于目标状态的信息。得到自身的信息后,智能体可将自身的信息输入至设于生成流模型中,以通过生成流模型对自身的信息进行处理,从而得到智能体的一个或多个动作的发生概率。那么,智能体可在一个或多个动作中,选择发生概率最大的动作,并执行该动作,以进入目标状态的某一个下一状态。前述过程中,由于智能体内置有生成流模型,可基于完成动作预测和动作执行,从而准确完成自身在不同状态之间的转换。
15、在一种可能实现的方式中,动作的发生概率基于预置动作的发生概率,确定待执行的动作包括:在动作以及预置动作中,将发生概率最大的动作确定为待执行的动作。
16、本技术实施例的第四方面提供了一种模型训练装置,该装置包括:获取模块,用于从预置的离线数据集中,获取智能体的第一信息,第一信息用于指示智能体处于目标状态;处理模块,用于通过待训练模型对第一信息进行处理,得到智能体的第一动作的发生概率,第一动作用于令智能体从目标状态进入目标状态的下一状态;训练模块,用于基于第一动作的发生概率,对待训练模型进行训练,得到生成流模型,真实发生概率来源于离线数据集。
17、从上述装置可以看出:当需要对待训练模型进行训练时,可先从预置的离线数据集中获取智能体的第一信息,第一信息用于指示智能体处于目标状态。然后,可将第一信息输入至待训练模型,以通过待训练模型对第一信息进行处理,从而得到智能体的第一动作的发生概率,第一动作用于令智能体从目标状态进入目标状态的下一状态。最后,可基于智能体的第一动作的发生概率以及第一动作的真实发生概率,对待训练模型进行训练,从而得到生成流模型,第一动作的真实发生概率来源于所述离线数据集。前述过程中,智能体的第一动作的发生概率可以称为待训练模型针对目标状态的预测动作策略,智能体的第一动作的真实发生概率可以称为离线数据库中针对目标状态的真实动作策略,这样可以令针对目标状态的预测动作策略尽可能地贴合针对目标状态的真实动作策略,而针对目标状态的真实动作策略决定了智能体从目标状态进入目标状态的下一状态的真实概率,故待训练模型不仅可以尽可能多地学习到目标状态的各个下一状态,且学习到的状态足够符合智能体所在的实际环境(因为离线数据集中的数据,均是基于智能体所在的实际环境提前设置的),那么,以离线训练模式训练得到的生成流模型,可以具备更优秀的性能。
18、在一种可能实现的方式中,训练模块,用于基于第一动作的发生概率,对待训练模型进行训练,以使得第一动作的发生概率与第一动作的真实发生概率之间的差异位于预置的范围内,得到生成流模型。
19、在一种可能实现的方式中,训练模块,用于:基于离线数据集,对智能体的第二动作的发生概率进行修正,得到第二动作的修正后的发生概率,第二动作用于令智能体从目标状态的前一状态进入目标状态;基于离线数据集,对目标状态对应的奖励值进行修正,得到目标状态对应的修正后的奖励值;基于第一动作的发生概率,第二动作的修正后的发生概率以及与目标状态对应的奖励值,对待训练模型进行训练,得到生成流模型。
20、在一种可能实现的方式中,离线数据集包括m个第一候选信息以及m个第二候选信息,第i个第一候选信息用于指示智能体处于第i个候选状态,第i个第二候选信息用于指示智能体处于第i个候选状态的前一状态,m个第一候选信息包括第一信息,m个第二候选信息包含第二信息,第二信息用于指示智能体处于目标状态的前一状态,m个候选状态包含目标状态,m≥1;训练模块,用于基于第一信息、第二信息、m个第一候选信息以及m个第二候选信息,对智能体的第二动作的发生概率进行修正,得到第二动作的修正后的发生概率。
21、在一种可能实现的方式中,离线数据集还包括m个候选状态对应的奖励值,训练模块,用于基于第一信息、m个第一候选信息以及m个候选状态对应的奖励值,对目标状态对应的奖励值进行修正,得到目标状态对应的修正后的奖励值。
22、在一种可能实现的方式中,第一信息为智能体处于目标状态时所采集的信息,信息包含以下至少一项:图像、视频、音频或文本。
23、本技术实施例的第五方面提供了一种动作预测装置,该装置包含第三方面或第三方面中任意一种可能实现的方式中的生成流模型,该装置包括:获取模块,用于获取智能体的信息,信息用于指示智能体处于目标状态;处理模块,用于通过待训练模型对信息进行处理,得到智能体的动作的发生概率,动作用于令智能体从目标状态进入目标状态的下一状态。
24、从上述装置可以看出:当智能体当前处于目标状态时,为了预测令自身进入从目标状态进入目标状态的下一状态的动作,智能体可先采集用于指示智能体处于目标状态的信息。得到自身的信息后,智能体可将自身的信息输入至设于生成流模型中,以通过生成流模型对自身的信息进行处理,从而得到智能体的一个或多个动作的发生概率。那么,智能体可在一个或多个动作中,选择发生概率最大的动作,并执行该动作,以进入目标状态的某一个下一状态。前述过程中,由于智能体内置有生成流模型,可基于完成动作预测和动作执行,从而准确完成自身在不同状态之间的转换。
25、本技术实施例的第六方面提供了一种动作预测装置,该装置包括:获取模块,用于获取智能体的信息,信息用于指示智能体处于目标状态;处理模块,用于通过待训练模型对信息进行处理,得到智能体的动作的发生概率,动作用于令智能体从目标状态进入目标状态的下一状态;确定模块,用于基于动作的发生概率基于预置动作的发生概率,确定待执行的动作。
26、从上述装置可以看出:当智能体当前处于目标状态时,为了预测令自身进入从目标状态进入目标状态的下一状态的动作,智能体可先采集用于指示智能体处于目标状态的信息。得到自身的信息后,智能体可将自身的信息输入至设于生成流模型中,以通过生成流模型对自身的信息进行处理,从而得到智能体的一个或多个动作的发生概率。那么,智能体可在一个或多个动作中,选择发生概率最大的动作,并执行该动作,以进入目标状态的某一个下一状态。前述过程中,由于智能体内置有生成流模型,可基于完成动作预测和动作执行,从而准确完成自身在不同状态之间的转换。
27、在一种可能实现的方式中,动作的发生概率基于预置动作的发生概率,确定待执行的动作包括:在动作以及预置动作中,将发生概率最大的动作确定为待执行的动作。
28、本技术实施例的第七方面提供了一种模型训练装置,该装置包括存储器和处理器;存储器存储有代码,处理器被配置为执行代码,当代码被执行时,模型训练装置执行如第一方面或第一方面中任意一种可能的实现方式所述的方法。
29、本技术实施例的第八方面提供了一种动作预测装置,该装置包括存储器和处理器;存储器存储有代码,处理器被配置为执行代码,当代码被执行时,动作预测装置执行如第二方面、第三方面或第三方面中任意一种可能的实现方式所述的方法。
30、本技术实施例的第九方面提供了一种电路系统,该电路系统包括处理电路,该处理电路配置为执行如第一方面、第一方面中的任意一种可能的实现方式、第二方面、第三方面或第三方面中任意一种可能的实现方式所述的方法。
31、本技术实施例的第十方面提供了一种芯片系统,该芯片系统包括处理器,用于调用存储器中存储的计算机程序或计算机指令,以使得该处理器执行如第一方面、第一方面中的任意一种可能的实现方式、第二方面、第三方面或第三方面中任意一种可能的实现方式所述的方法。
32、在一种可能的实现方式中,该处理器通过接口与存储器耦合。
33、在一种可能的实现方式中,该芯片系统还包括存储器,该存储器中存储有计算机程序或计算机指令。
34、本技术实施例的第十一方面提供了一种计算机存储介质,该计算机存储介质存储有计算机程序,该程序在由计算机执行时,使得计算机实施如第一方面、第一方面中的任意一种可能的实现方式、第二方面、第三方面或第三方面中任意一种可能的实现方式所述的方法。
35、本技术实施例的第十二方面提供了一种计算机程序产品,该计算机程序产品存储有指令,该指令在由计算机执行时,使得计算机实施如第一方面、第一方面中的任意一种可能的实现方式、第二方面、第三方面或第三方面中任意一种可能的实现方式所述的方法。
36、本技术实施例中,当需要对待训练模型进行训练时,可先从预置的离线数据集中获取智能体的第一信息,第一信息用于指示智能体处于目标状态。然后,可将第一信息输入至待训练模型,以通过待训练模型对第一信息进行处理,从而得到智能体的第一动作的发生概率,第一动作用于令智能体从目标状态进入目标状态的下一状态。最后,可基于智能体的第一动作的发生概率,对待训练模型进行训练,从而得到生成流模型。前述过程中,待训练模型在获取智能体的第一动作的发生概率时,会令智能体的第一动作的发生概率与智能体的第一动作的真实发生概率之间的差异位于预置的范围内,由于智能体的第一动作的发生概率可以称为待训练模型针对目标状态的预测动作策略,智能体的第一动作的真实发生概率可以称为离线数据库中针对目标状态的真实动作策略,这样可以令针对目标状态的预测动作策略尽可能地贴合针对目标状态的真实动作策略,而针对目标状态的真实动作策略决定了智能体从目标状态进入目标状态的下一状态的真实概率,故待训练模型不仅可以尽可能多地学习到目标状态的各个下一状态,且学习到的状态足够符合智能体所在的实际环境(因为离线数据集中的数据,均是基于智能体所在的实际环境提前设置的),那么,以离线训练模式训练得到的生成流模型,可以具备更优秀的性能。
- 还没有人留言评论。精彩留言会获得点赞!