一种基于跨文化适应的层次化语码混合增广方法
本发明涉及文化适应和预训练模型在多模态多语言数据集上的应用,尤其涉及跨文化设定下提升模型表现的技术方法。
背景技术:
1、人类语言和图像与他们的文化交织在一起,共同进化、并相互影响。不同的国家往往有不同的文化。近年来,虽然很多方法提高了模型的跨语言和跨模态能力,但往往都忽略了跨文化能力。提高模型在不同文化上的迁移能力很重要,这可以帮助模型利用高资源语言和文化数据来理解低资源语言和文化。
2、近年来,跨语言和跨模态在计算机视觉(cv)和自然语言处理(nlp)社区都取得了长足的进步。例如,xlm引入了三个语言建模目标:因果语言建模、掩码语言建模和翻译语言建模,并且在跨语言任务上的表现明显优于之前的最新技术。uc2提出了masked region-to-token建模和视觉翻译语言建模预训练任务,学习了结合语言和视觉的上下文感知表示。虽然这些方法提高了模型的跨语言和跨模态能力,但它们忽略了跨文化能力。提高模型对不同文化的感知和迁移能力很重要,有效的跨文化方法可以提高模型利用高资源语言和文化理解低资源语言和文化的能力。事实上,在过去的几年里,也有一些相关工作提到或关注了文化话题。例如,通过利用twitter和不同文化中使用的特定时间问候语(例如“早上好”)来研究part-of-day名词的语义,或者调查美国和印度之间关于跨文化常见仪式的文化差异例如出生、婚姻和葬礼。也有一些相关工作使用来自非西方文化的数据扩展了现有的视觉问答和推理数据集。然而,他们大多关注文化差异的影响或构建基准来测试模型的跨文化能力,而不是提升它们。主要是因为提高跨文化能力比较困难:(1)标注跨文化数据的成本很高,因为很少有标注者熟悉不同国家的两种文化。(2)降低资源语言本身是稀缺的,其中的文化概念更是低频。于是就有了一个新颖而重要的问题:如何提高模型的跨文化能力?本专利采用了无需标注的文化适应的方法,并结合语码混合策略将跨文化问题简化为跨语言问题,从而有效提升模型能力。
技术实现思路
1、本发明目的是解决现有技术中存在的问题,并提供一种基于跨文化适应的层次化语码混合增广算法。
2、本发明具体采用的技术方案如下:
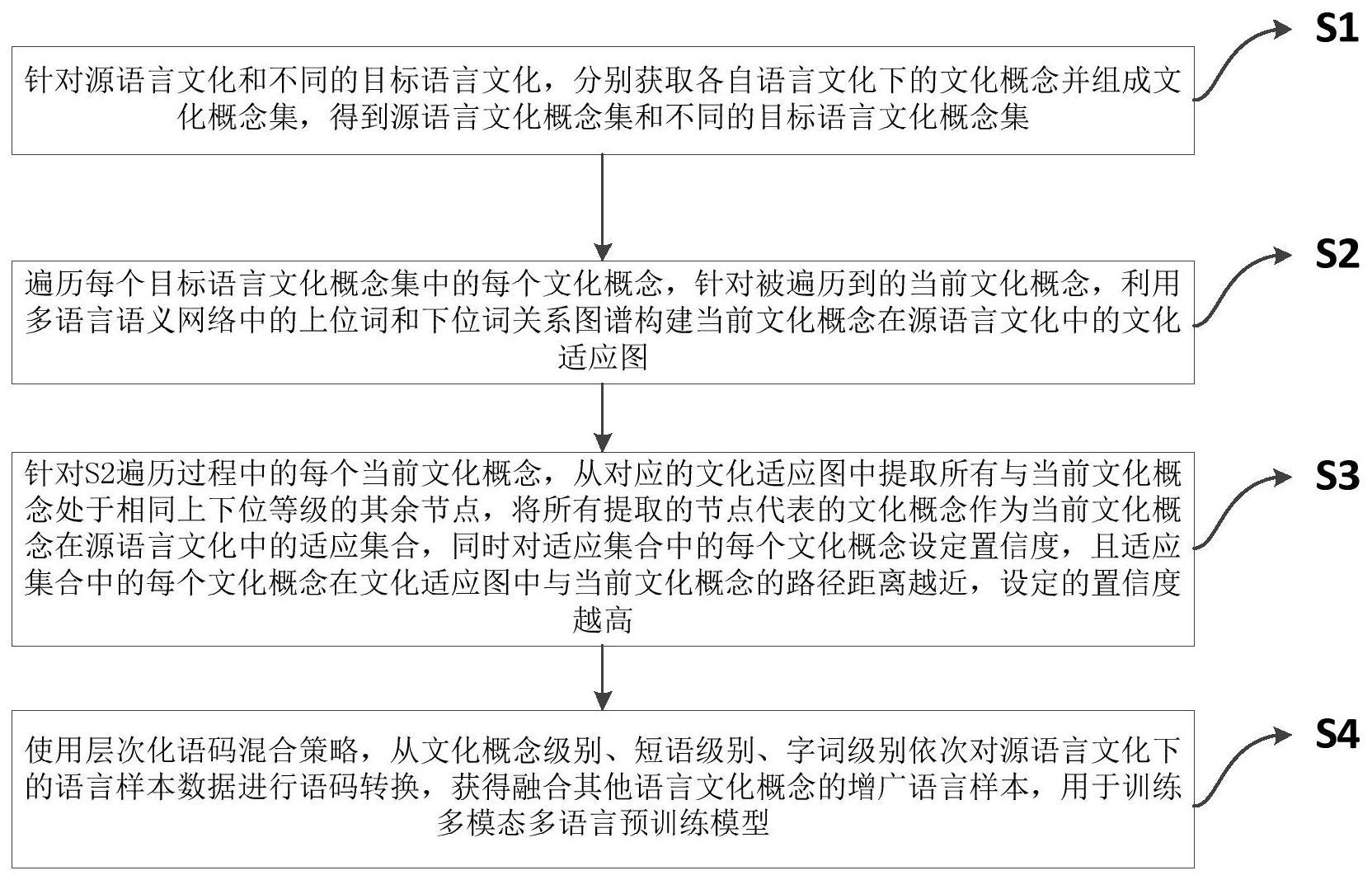
3、第一方面,本发明提供了一种基于跨文化适应的层次化语码混合增广方法,其用于对源语言文化下的语言样本数据进行增广,所述方法步骤如下:
4、s1:针对所有待增广的目标语言文化,分别获取各自语言文化下的文化概念并组成文化概念集;
5、s2:遍历文化概念集中的每个文化概念,针对被遍历到的当前文化概念,利用多语言语义网络中的上位词和下位词关系图谱构建当前文化概念在源语言文化中的文化适应图;
6、s3、针对s2遍历过程中的每个当前文化概念,从对应的文化适应图中提取所有与当前文化概念处于相同上下位等级的其余节点,将所有提取的节点代表的文化概念作为当前文化概念在源语言文化中的适应集合,同时对适应集合中的每个文化概念设定置信度,且适应集合中的每个文化概念在文化适应图中与当前文化概念的路径距离越近,设定的置信度越高;
7、s4、使用层次化语码混合策略,从文化概念级别、短语级别、字词级别依次对源语言文化下的语言样本数据进行语码转换,获得融合其他语言文化概念的增广语言样本,用于训练多模态多语言预训练模型。
8、作为优选,所述s1中,源语言文化为英文文化,目标语言文化为不同国家或地区的其他语言文化。
9、作为优选,所述s1中,语言样本数据为视觉推理任务数据集,数据集中的每个样本包含一对图像、用于描述这对图像的文本语句以及表示该文本语句是否正确描述这一对图片的标签;在使用层次化语码混合策略进行语码转换时,转换的对象是样本中描述这对图像的文本语句。
10、作为优选,所述s2中,对于每个被遍历到的当前文化概念构建文化适应图的具体步骤如下:
11、s21:对于被遍历到的当前文化概念,根据这个当前文化概念所属的目标语言文化,在多语言语义网络中的上位词和下位词关系图谱中查询其在所属的目标语言文化中的多阶上位词;
12、s22:针对s21中查询到的每一阶上位词,继续在关系图谱中查询该上位词在源语言文化中的同义词,然后查询每个同义词在源语言文化中的所有下位词;
13、s23:将被遍历到的当前文化概念以及在s21和s22中查询到的所有上位词、下位词和同义词作为图的节点,并将所有节点按照相互之间的词阶关系连接起来,组成当前文化概念在源语言文化中的文化适应图。
14、作为优选,所述s21中,所述多阶上位词为三阶上位词。
15、作为优选,所述s2中,多语言语义网络采用conceptnet和wordnet,其中conceptnet中“/r/isa”被用来查询上位词,"/r/synonym“被用来查询同义词,而wordnet中“hyponyms()”被用来查询下位词。
16、作为优选,所述s4中,每一次通过层次化语码混合策略进行语码转换获得一个增广语言样本的步骤如下:
17、s41:从所有的目标语言文化中随机采样一种目标语言文化l,然后从文化概念集中采样目标语言文化l中的一个文化概念c1,再从文化概念c1在源语言文化中的适应集合ca中采样一个文化概念c2,且从适应集合ca中采样文化概念c2时集合内每个文化概念被采样到的概率与其置信度正相关;
18、s42:在源语言文化下的语言样本数据中检索包含文化概念c2的语言样本s1,然后对语言样本s1进行文化概念级别的语码混合,将语言样本s1中的文化概念c2替换为s41中采样的文化概念c1,形成语言样本s2;
19、s43:将s42中得到的语言样本s2进行短语级别的语码混合,从语言样本s2中采样源语言文化下的短语,采样一种目标语言文化,将采样到的每个短语替换为该短语在采样的目标语言文化下的同义词,形成语言样本s3;
20、s44:将s43中得到的语言样本s3进行字词级别的语码混合,从语言样本s3中采样源语言文化下的字词,采样一种目标语言文化,将采样到的每个字词替换为该字词在采样的目标语言文化下的同义词,形成本次增广最终得到的增广语言样本s4。
21、作为优选,所述的s43中,进行短语级别的语码混合前,需要从源语言文化的语言样本数据中选择高频短语构建为源语言短语集合,并将该源语言短语集合中的每个短语翻译为其他的目标语言文化从而形成同义词;在进行短语级别的语码混合时,需判断语言样本s2中是否有短语存在于所述源语言短语集合中,若存在,则按照预设的替换概率确定是否要对存在于所述源语言短语集合中的每个短语进行替换,若存在需替换短语,则采样一种目标语言文化并查找需替换短语在这种目标语言文化下的同义词,将每个需替换短语替换为查找到的同义词。
22、作为优选,所述的s44中,进行字词级别的语码混合前,需要从源语言文化的语言样本数据中选择高频字词构建为源语言字词集合,并将该源语言字词集合中的每个字词翻译为其他的目标语言文化从而形成同义词;在进行字词级别的语码混合时,需判断语言样本s2中是否有字词存在于所述源语言字词集合中,若存在,则按照预设的替换概率确定是否要对存在于所述源语言字词集合中的每个字词进行替换,若存在需替换字词,则采样一种目标语言文化并查找需替换字词在这种目标语言文化下的同义词,将每个需替换字词替换为查找到的同义词。
23、第二方面,本发明提供了一种跨文化跨语言模型训练方法,其将多模态多语言预训练模型在包含如第一方面任一所述增广方法获得的增广语言样本的数据集上进行任务训练,从而得到具有更好跨文化跨语言能力的模型
24、作为优选,所述多模态多语言预训练模型为muniter、xuniter、m3p或uc2模型,训练采用的损失函数优选为交叉熵损失。
- 还没有人留言评论。精彩留言会获得点赞!