一种文本分类的方法、装置、电子设备及存储介质与流程
本发明涉及互联网,尤其是涉及一种文本分类的方法、装置、电子设备及存储介质。
背景技术:
1、文本内容安全分类,通常指对一段文本中的每句话进行判断,是否属于预先定义的违规类型中的一种。常用的方案有两种,一是预先收集一批违规类型的敏感词,通过文本中是否包含相应类别的敏感词来判断语句分类;二是通过深度学习的方法,训练一个文本分类模型。常规的深度学习方法,都是直接将语句通过模型编码后加上全连接的预测层,再通过softmax函数,将预测归一到0-1的概率区间。
2、实际分类中,仅仅通过语句本身的信息,不足以判断语句所属的类别,需要结合语句的上下文信息才能判断。因此,仅仅从前一句话的内容进行判断,很容易造成句子类别的误判断,这样导致现有的文字分类方法易出现错误。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种文本分类的方法、装置、电子设备及存储介质以及计算机程序产品,以提高文本分类的准确性及可靠性。
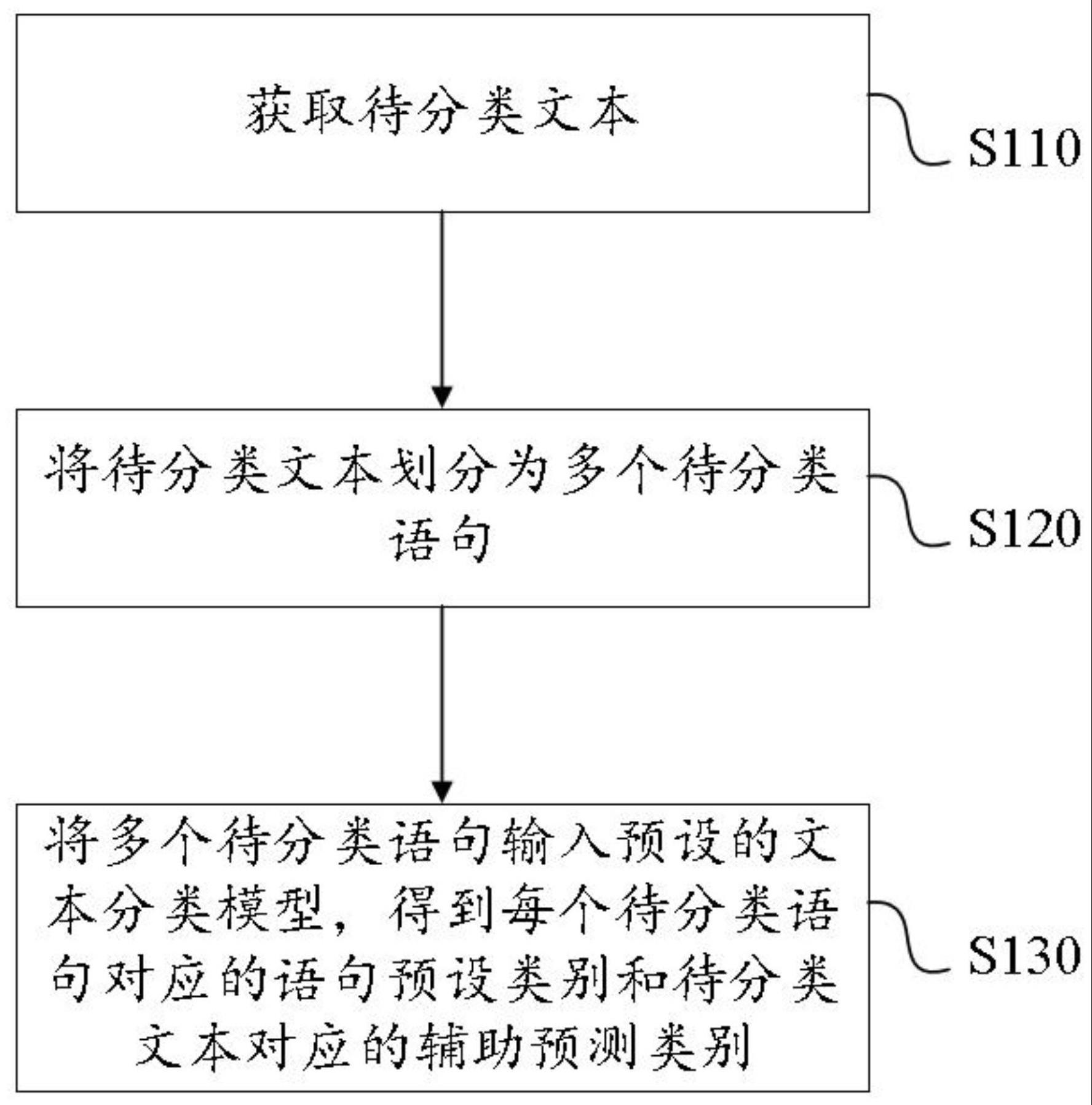
2、第一方面,本发明实施例提供了一种文本分类的方法,该方法包括:
3、获取待分类文本;
4、将所述待分类文本划分为多个待分类语句;
5、将多个所述待分类语句输入预设的文本分类模型,得到每个所述待分类语句对应的语句预测类别和所述待分类文本对应的辅助预测类别;
6、其中,所述辅助预测类别用于表征文本整体篇章类别或者各语句预测类别中的多数类别。
7、做为一种可实施的方式,所述文本分类模型的训练过程如下:
8、获取训练样本集;所述训练样本集中的样本包括标注有语句类别标签,和篇章类别标签的文本;
9、应用所述训练样本集对预设分类模型进行训练,得到所述文本分类模型。
10、做为一种可实施的方式,获取训练样本集的步骤,包括:
11、获取参考文本;所述参考文本包括设定地址段内的网页文本信息;
12、对所述参考文本进行数据清洗和分句处理,得到多个语句;针对每个语句,标注对应的至少一个语句类别标签;
13、针对所述参考文本标注对应的篇章类别标签,得到训练样本集。
14、做为一种可实施的方式,所述语句类别标签至少包括以下之一:正常、广告宣传;所述篇章类别标签至少包括以下之一:玄幻小说、历史小说、电商类、其他。
15、做为一种可实施的方式,所述预设分类模型包括:依次连接的:bert-base模型、单层转换层、两个全连接分类层;应用所述训练样本集对预设分类模型进行训练,得到所述文本分类模型的步骤,包括:
16、将所述训练样本集中的参考文本对应的所有语句输入所述bert-base模型,输出每个语句对应的句向量;
17、将每个所述语句对应的句向量输入所述单层转换层,输出每个句向量对应的叠加有随机初始化权重的转换句向量;
18、将每个所述转换句向量输入所述两个全连接分类层,并进行归一化处理,输出每个语句对应的预测语句类别、以及所述参考文本对应的预测篇章类别;
19、根据每个语句分别对应的预测语句类别以及语句类别标签、所述参考文本分别对应的预测篇章类别以及篇章类别标签,计算总预测损失值;
20、根据所述总预测损失值进行反向传播,计算模型中参数梯度并更新,得到文本分类模型。
21、做为一种可实施的方式,根据每个语句分别对应的预测语句类别以及语句类别标签、所述参考文本分别对应的预测篇章类别以及篇章类别标签,计算总预测损失值的步骤,包括:
22、根据每个语句分别对应的预测语句类别以及语句类别标签,计算第一交叉熵损失;
23、根据所述参考文本分别对应的预测篇章类别以及篇章类别标签,计算第二交叉熵损失;
24、将所述第一交叉熵损失和所述第二交叉熵损失进行加权求和,得到总预测损失值。
25、做为一种可实施的方式,所述各语句预测类别中的多数类别为基于各类别对应的数量,确定出的数量最大的类别。
26、本申请第二方面提供一种文本检测装置,该装置包括:
27、获取模块,用于获取待分类文本;
28、划分模块,用于将所述待分类文本划分为多个待分类语句;
29、输入模块,用于将多个所述待分类语句输入预设的文本分类模型,得到每个所述待分类语句对应的语句预测类别和待分类文本对应的辅助预测类别;
30、其中,所述辅助预测类别用于表征文本整体篇章类别或者各语句预测类别中的多数类别。
31、本申请第三方面提供一种电子设备,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实现上述的方法。
32、本申请第四方面提供一种存储介质,存储介质存储有机器可执行指令,所述机器可执行指令在被处理器调用和执行时,机器可执行指令促使处理器实现上述的方法。
33、本发明实施例带来了以下有益效果:本发明提供了一种文本分类的方法、装置、电子设备以及存储介质,该方法包括:获取待分类文本;将所述待分类文本划分为多个待分类语句;将多个所述待分类语句输入预设的文本分类模型,得到每个所述待分类语句对应的语句预测类别和所述待分类文本对应的辅助预测类别;其中,所述辅助预测类别用于表征文本整体篇章类别或者各语句预测类别中的多数类别。
34、本申请提供的文本分类的方法将待分类文本中的全部语句作为预设的文本分类模型的输入,综合每一个待分类语句的语义得到每个待分类语句对应的语句预测类别,并且结合全部的待分类语句组成的整体篇章得到对应的辅助预测类别,这样可以有效地提高文本分类的准确性和可靠性。
35、本发明的其他特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
36、为使本发明的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
技术特征:
1.一种文本分类的方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述文本分类模型的训练过程如下:
3.根据权利要求2所述的方法,其特征在于,获取训练样本集的步骤,包括:
4.根据权利要求3所述的方法,其特征在于,所述语句类别标签至少包括以下之一:正常、广告宣传;所述篇章类别标签至少包括以下之一:玄幻小说、历史小说、、电商类、其他。
5.根据权利要求2所述的方法,其特征在于,所述预设分类模型包括:依次连接的:bert-base模型、单层转换层、两个全连接分类层;应用所述训练样本集对预设分类模型进行训练,得到所述文本分类模型的步骤,包括:
6.根据权利要求5所述的方法,其特征在于,根据每个语句分别对应的预测语句类别以及语句类别标签、所述参考文本分别对应的预测篇章类别以及篇章类别标签,计算总预测损失值的步骤,包括:
7.根据权利要求1所述的方法,其特征在于,所述各语句预测类别中的多数类别为基于各类别对应的数量,确定出的数量最大的类别。
8.一种文本检测装置,其特征在于,所述装置包括:
9.一种电子设备,其特征在于,包括处理器和存储器,所述存储器存储有能够被所述处理器执行的机器可执行指令,所述处理器执行所述机器可执行指令以实现权利要求1至7任一项所述的方法。
10.一种存储介质,其特征在于,所述存储介质存储有机器可执行指令,所述机器可执行指令在被处理器调用和执行时,机器可执行指令促使处理器实现权利要求1至7任一项所述的方法。
技术总结
本发明涉及互联网技术领域,尤其提供了一种文本分类的方法、装置、电子设备及存储介质,该方法包括:获取待分类文本;将所述待分类文本划分为多个待分类语句;将多个所述待分类语句输入预设的文本分类模型,得到每个所述待分类语句对应的语句预测类别和所述待分类文本对应的辅助预测类别;其中,所述辅助预测类别用于表征文本整体篇章类别或者各语句预测类别中的多数类别。本申请提供的文本分类的方法将待分类文本中的全部语句作为预设的文本分类模型的输入,综合每一个待分类语句的语义得到每个待分类语句对应的语句预测类别,并且结合全部的待分类语句组成的整体篇章得到对应的辅助预测类别,这样可以有效地提高文本分类的准确性和可靠性。
技术研发人员:张乐平,李文举,侯磊,李海峰
受保护的技术使用者:北京匠数科技有限公司
技术研发日:
技术公布日:2024/1/11
- 还没有人留言评论。精彩留言会获得点赞!