基于领域知识库的专业文档智能辅助阅读方法
本发明属于计算机自然语言处理,具体涉及专业文档智能辅助阅读方法。
背景技术:
1、阅读较为专业或不熟悉领域的文字内容,往往需要了解相关背景知识,特别是专业术语的含义,才能够较为顺利地开展阅读,并且理解所阅读的内容。阅读传统纸质文字内容和书籍时,当遇到不了解的专业术语,人们往往需要通过各种方法查询相关的知识。在线阅读电子内容时,则可以利用计算机帮助实时获得辅助阅读的相关知识。
2、知识图谱是采用语义检索技术从多种信息源收集与某一主题相关的实体或概念,以及他们之间的关联所形成的网络图。图中的结点对应实体或概念,图中的弧对应于实体或概念之间的关联关系。借助知识图谱技术,通过深化现实世界中每个实体以及他们之间相互关系的理解,可以提高搜索精度和优化搜索结果,还可以提供语义分析、关联分析、知识搜索和智能推荐等知识服务。在构建领域知识图谱基础上,可以从文字内容中自动识别领域术语,并与知识图谱中存储的知识进行语义关联,进而在阅读过程中实时地提供术语解释、知识导航和智能搜索等功能,降低读者的阅读难度,提高读者的阅读效率、体验和乐趣。
技术实现思路
1、本发明的目的在于提出一种可降低阅读难度,提高阅读效率、体验和乐趣的专业文档智能辅助阅读方法。
2、本发明提出的专业文档智能辅助阅读方法,是基于领域知识库技术的,通过构建领域本体知识库,借助本体知识库中所存储的以语义相关联知识,为读者阅读专业文档智能提供和补充背景知识。包括运用计算机对读者正在阅读电子文档中所出现的专业术语和概念进行实时注解,并且以语义方式组织相关背景知识,从而实现相关知识之间的语义关联和导航,例如提供语义分析、关联分析、知识搜索和智能推荐等;从而知识辅助阅读专业化程度较高的文字内容,除低读者的阅读难度,并且提高读者的阅读效率、体验和乐趣。
3、本发明提出的基于领域知识库的专业文档智能辅助阅读方法,具体步骤包括:领域本体知识库的构建、领域本体知识库的使用、语义关联与智能问答。
4、步骤(1)领域本体知识库的构建:
5、分为按信息抽取、知识融合和知识加工三个阶段构建领域本体知识库,即知识图谱。构建过程包括以下步骤:
6、(1.1)信息抽取,从数据源中提取出实体、属性以及实体之间的相互关系;根据数据源中的数据构建词典和关系数据库;采用基于spanbert结构深度神经网络和软词表的方式对抽取获得的实体进行筛选,解决未知实体较多的问题;
7、(1.2)知识融合,对信息抽取阶段所获得的知识进行处理,将从网上获取的外部知识库和根据信息抽取阶段所构建的关系数据库中的数据进行转换,并导入到领域本体库,实现对知识整合;通过计算实体之间的余弦相似度的方法来消除矛盾和歧义;
8、(1.3)知识加工,采用人工编辑对经过融合的知识进行加工;然后对编辑所获得的知识使用fudandnn-nlp工具进行知识推理,通过知识发现完善和补充知识;通过知识加工确保知识库的质量;
9、(1.4)构建完成领域本体知识库后,根据上述三个阶段迭代更新领域本体知识库。
10、步骤(2)在领域本体知识库的使用:
11、(2.1)利用所构建的领域本体知识库,对各类领域实体、关系、属性利用多维索引技术构建领域概念的索引;
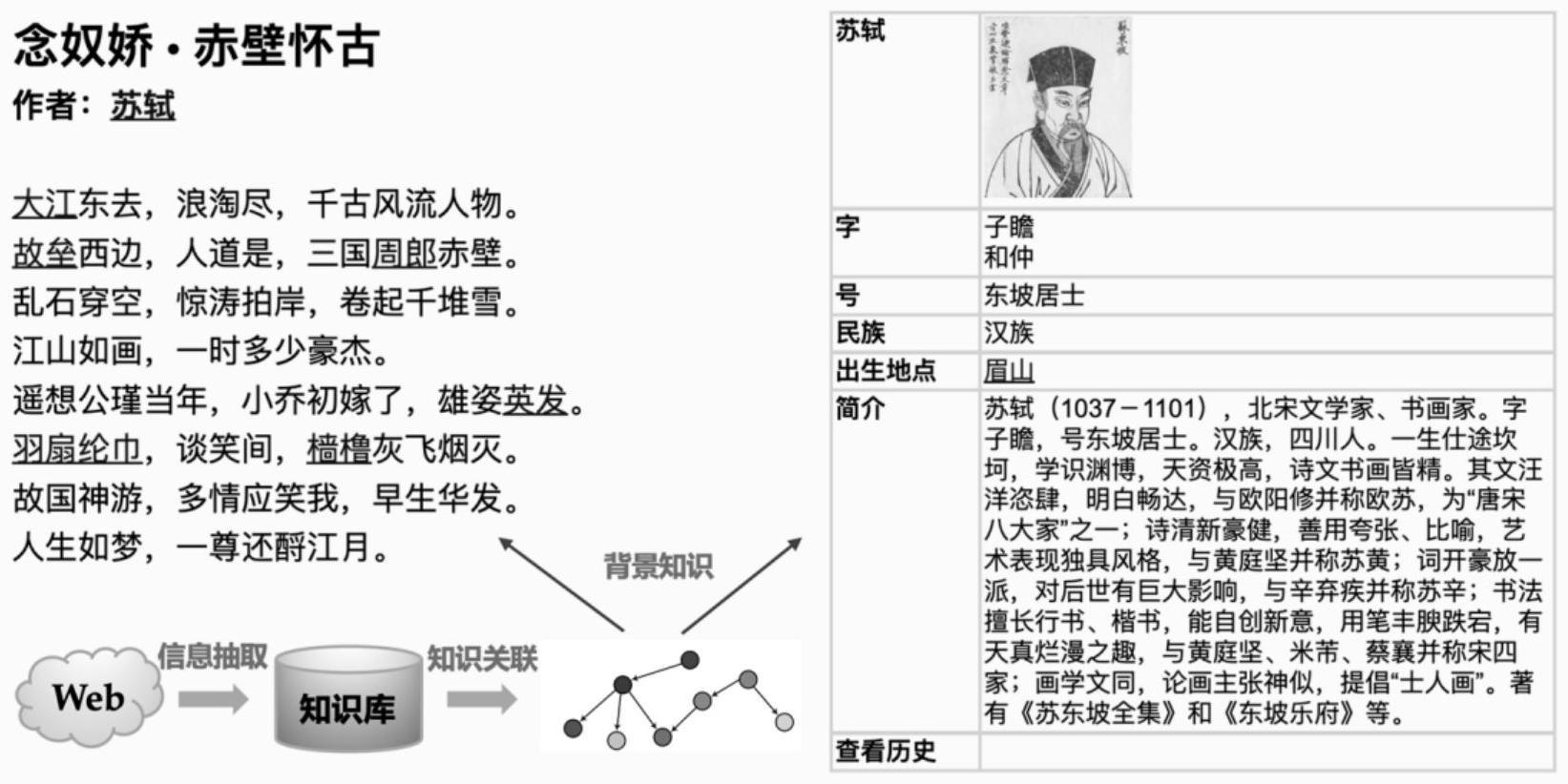
12、(2.2)根据领域本体知识库所提供的知识搭建一个阅读智能辅助平台,为每一个概念生成html局部页面,具体包含简要解释和相关属性值与图片,其中,使用div标签,称之为概念的说明框;
13、(2.3)利用上步所构建的领域概念的索引和阅读智能辅助平台,同时结合命名识别工具fudandnn-nlp从电子文档中识别出领域概念,概念的相关知识通过以阅读智能辅助平台页面中隐式链接的方式关联到概念的说明框。
14、步骤(3)语义关联与智能问答;
15、在阅读智能辅助平台中的阅读界面还提供智能检索功能,并且能够利用本体知识库所存储的知识进行智能问答;语义关联和智能问答的把步骤如下:
16、(3.1)调用现有语音识别工具对语音进行识别,转换成文字表示的句子(如果以文字方式进行交互,此步可略);
17、(3.2)对上一步得到的句子使用fudandnn-nlp工具进行基础预处理,包括语言规范化、敏感词检测、自定义词汇识别、命名识别、中文分词、词性分析;
18、(3.3)判断预处理后的句子是否处于上下文相关问答或多轮对话中,如果是,则进行下一步处理;如果之前没有上下文信息或者当前语句不属于已开展的上下文相关问答和多轮对话,则进入后续处理;
19、(3.4)对于上一步经过判断后的句子,对寒暄和常见问题进行优先匹配,匹配过程考虑发音相似性;如果存在匹配的回答,直接产生回答;如果不存在匹配则进入后续的处理;
20、(3.5)使用fudandnn-nlp工具中的句子分类模型对句子进行分类,识别用户意图,并且根据意图识别结果进行语义分析;
21、(3.6)对于需要使用知识库或外部资源的应用,则调用知识库或外部资源查询接口,获取查询结果;
22、(3.7)通过调用外部资源执行查询,返回查询结果,产生答句;
23、(3.8)如果语义分析或者外部资源调用失败,对大规模问答库检索产生合适的答句;
24、(3.9)根据所生成的答句;
25、(3.10)调用现有语音合成功能,产生语音回答(如果以文字方式进行交互,此步可略)。
26、根据上述专业文档智能辅助阅读方法,本发明还包括基于领域知识库的专业文档智能辅助阅读系统。该系统包括三个模块:领域本体知识库的构建模块、领域本体知识库使用模块、语义关联与智能问答模块。三个模块分别执行本发明三个步骤的操作内容。
27、本发明特点在于:
28、(1)实时高效地在阅读电子文档时提供和补充背景知识,有效降低读者的阅读难度,并且提升读者的阅读效率、体验和乐趣;
29、(2)以语义关联的方式组织领域知识,实现领域知识的语义导航,帮助读者快速和系统地了解相关的信息和知识;
30、(3)阅读界面集成能以自然语言交互方式进行智能检索和知识库问答。以解决用户问题为目标,利用领域知识通过智能推理来引导对话的顺利展开,具备问题答案的解释能力。
31、本发明可为读者实时和便捷地提供阅读所需的背景或专业知识,大幅降低阅读的难度,提高读者的阅读体验和乐趣。对比没有智能阅读辅助系统的情况,读者的阅读效率和效果都有明显的提升。
32、自然语言处理:计算机科学领域与人工智能领域中的一个重要分支,研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理并不是一般地研究自然语言,而在于研制能有效地实现自然语言通信的计算机系统,特别是其中的软件系统。
33、深度学习:深度学习是机器学习的一种,采用多层神经网络从输入中捕捉高层语义特征,进而进行分类、回归、生成等任务。常常以监督式学习的形式,用带有标签的资料集来做训练。深度学习的方法可以直接处理高维度、复杂的原始输入资料,相较之前的传统方法较少的依赖人为的特征工程从输入资料中提取特征。
34、知识图谱:采用语义检索技术从多种信息源收集与某一主题相关的实体或概念,以及他们之间的关联所形成的网络图。图中的结点对应实体或概念,图中的弧对应实体或概念之间的关联关系。
- 还没有人留言评论。精彩留言会获得点赞!