基于深度学习和知识库的智能对联生成方法与流程
本发明涉及机器学习,特别是一种基于深度学习和知识库的智能对联生成方法。
背景技术:
1、随着人工智能的迅猛发展,深度学习(dl,deep learning,简称dl)在自然语言处理领域(natural language processing,简称为nlp)中取得了长足的发展。近年来人工智能和数据库的有机结合,促使知识库系统也取得了长足的发展。
2、现在市场上比较成熟的“自动对联系统”有微软亚洲研究院自然语言计算组研发的计算机自动对联系统,和手机端的“对联赏析”app。现有的对联技术在上下联的语义配合方面存在着一些问题,对联的长度被限制在了10字以内,且不可以含有标点。而且对联系统是纯基于数据库的系统或者是纯基于模型的系统,缺少将两者有机融合的对联系统。现有技术训练对联模型的方法存在如下三个问题:
3、(1)对联数据数据规模问题,对联数据数据规模相比于网络文本、论坛文本、汉语现代文文本数据规模来说算小数据。前者的数据量级别在几十万级别,而后者的数据量级可以轻松达到百万级别和千万级别。
4、(2)现有对联训练数据通常采用的是文本对齐方式训练对联模型(例如将文本固定成12个字,文本过长则截断、文本过短则填充占用字符使得文本对齐到12个字),这就造成了模型学习对联特征的时候,学习的数据是有偏差的,部分数据是不全的,部分数据是有噪声的。
5、(3)基于验证集训练过程仍未能避免模型同时在训练集和验证集都陷入局部最优的情况。
6、综合来看,目前针对智能对联方法的研究不多,市面上的产品采用的技术属于早期nlp研究的技术,已建立的模型对于多级自动表征学习存在不充分、欠拟合和过拟合等问题,处理时常常依赖于手动制作特征,且生成的对联受字数限制,生成的对联质量不佳的问题。
技术实现思路
1、为解决现有技术中存在的问题,本发明的目的是提供一种基于深度学习和知识库的智能对联生成方法,本发明达到了人机对对联的实时智能交互。
2、为实现上述目的,本发明采用的技术方案是:一种基于深度学习和知识库的智能对联生成方法,包括以下步骤:
3、步骤1、训练seq2seq神经网络模型;
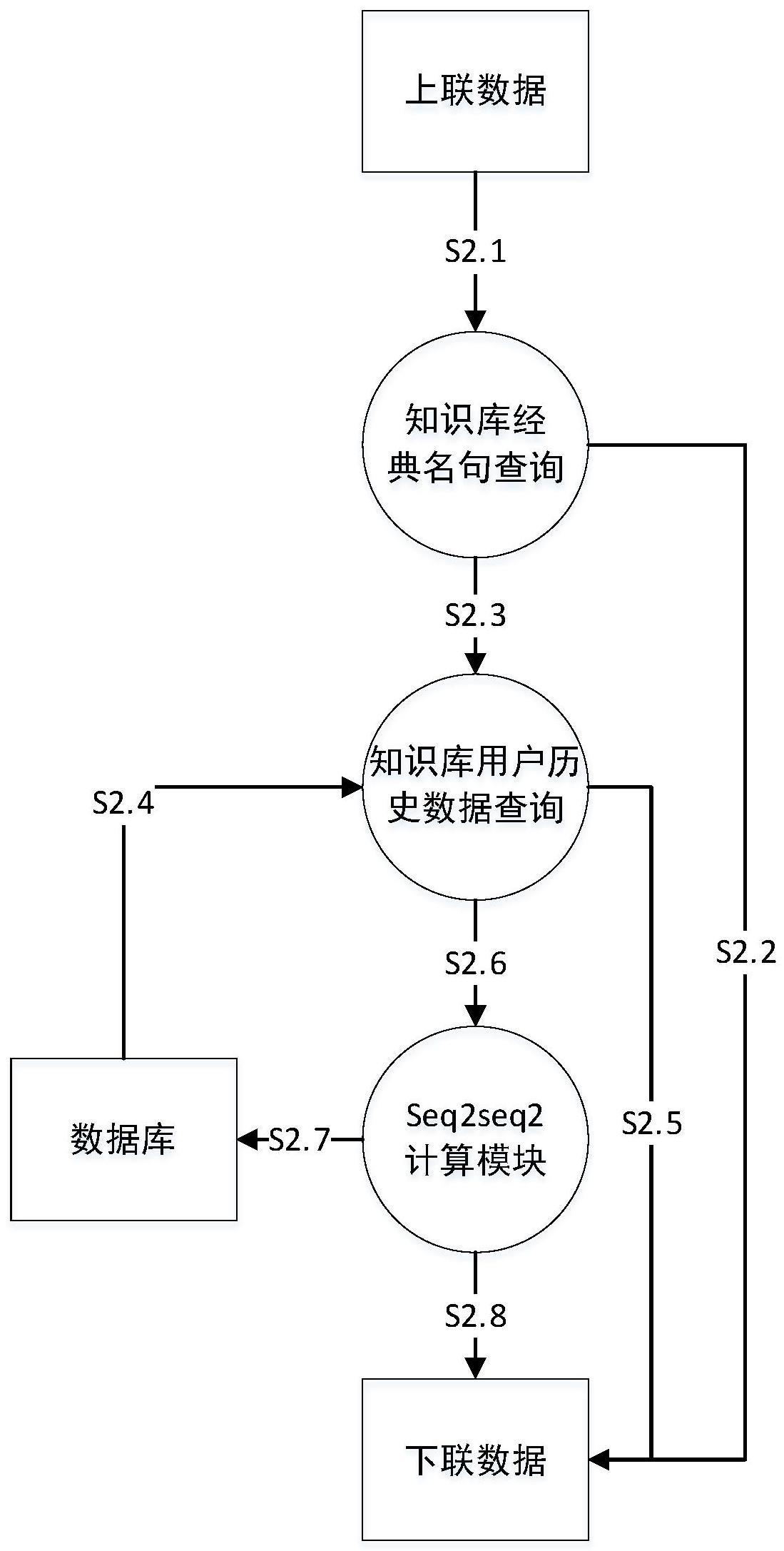
4、步骤2、当用户输入上联数据后,首先从知识库中查询用户输入的上联数据是否为经典古诗词名句,若是则从知识库输出经典古诗词名句对应的下联,若不是则进入知识库用户历史数据中进行查询;
5、步骤3、在知识库用户历史数据中查询用户是否曾经输入步骤1中的非经典古诗词名句的上联数据,若是则从知识库用户历史数据直接返回下联,若不是则将上联数据作为输入代入所述seq2seq神经网络模型进行前向处理计算得到下联数据;
6、步骤4、保存seq2seq神经网络模型计算得到下联到数据库中作为知识库用户历史数据;并反馈seq2seq神经网络模型计算得到下联到前端页面进行显示。
7、作为本发明的进一步改进,步骤1中训练seq2seq神经网络模型具体包括以下步骤:
8、步骤1.1、对同义词替换的对联数据进行增广,具体包括:
9、(1)在训练集d中随机选择一对曾经未选择的对联d;
10、(2)对对联d进行分词,选出对联d中的名词、动词、形容词构成集合e;
11、(3)在集合e中随机选择k个词语在原始对联的对应位置上进行同义词替换;
12、(4)将新生成的对联d’加入集合d’;
13、(5)重复(1)-(4)直到集合d’数据量满足训练要求;
14、(6)将训练集d和集合d’进行合并输出新的训练集train;
15、(7)对验证集v重复(1)-(6)的操作,得到新的验证集valiad;
16、步骤1.2、生成基于不定长动态的batch数据,具体包括:
17、1)读取所有的训练样本train,并通过分词器转为id数组;
18、2)定义变量a,用于保存不同字数对的样本个数;
19、3)定义变量b,用于保存不同字数对样本个数的分布概率;
20、4)根据变量a和变量b,进行随机选对联长度,然后随机选对联样本,以生成字数都一样的一个batch数据c;
21、5)定义变量d,取batch和c长度中最小值;
22、6)从c中随机挑选d个样本,为数据集e作为返回;
23、步骤1.3、对基于动态交叉验证的模型验证进行训练,具体包括:
24、①在每一次模型迭代中,从验证集valiad中随机选择m个对联;
25、②将m个对联划分成n个子集,每个子集样本数量为m/n个;
26、③对每一个子集模型都进行预测并得到每个子集合上正确率和损失值;
27、④对n个子集的正确率和损失值计算平均值;
28、⑤当平均正确率大于设定的正确率阈值或者平均损失值在一定迭代次数后不再下降时候则表明模型已训练充分,模型可以退出训练循环;
29、步骤1.4、输出模型文件并将模型发布成服务。
30、作为本发明的进一步改进,在步骤1.4中,若模型是用tensorflow训练则输出.h5文件,若模型是用pytorch训练则输出.pt文件。
31、本发明的有益效果是:
32、1、本发明采用了了同义词替换的对联数据增广、基于不定长动态batch数据生成、基于动态交叉验证的模型验证;使得模型能够在海量数据情况下,完美的学习到对联特征,并避免模型陷入局部最优,进而使得模型更智能;
33、2、本发明的模型训练相比于传统方法模型生成文本质量更高、所需数据量更少、所需迭代次数更少。
技术特征:
1.一种基于深度学习和知识库的智能对联生成方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于深度学习和知识库的智能对联生成方法,其特征在于,步骤1中训练seq2seq神经网络模型具体包括以下步骤:
3.根据权利要求2所述的基于深度学习和知识库的智能对联生成方法,其特征在于,在步骤1.4中,若模型是用tensorflow训练则输出.h5文件,若模型是用pytorch训练则输出.pt文件。
技术总结
本发明公开了一种基于深度学习和知识库的智能对联生成方法,包括:训练Seq2seq神经网络模型;当用户输入上联数据后,首先从知识库中查询用户输入的上联数据是否为经典古诗词名句,若是则从知识库输出经典古诗词名句对应的下联,若不是则进入知识库用户历史数据中进行查询;在知识库用户历史数据中查询用户是否曾经输入非经典古诗词名句的上联数据,若是则从知识库用户历史数据直接返回下联,若不是则将上联数据作为输入代入seq2seq神经网络模型进行前向处理计算得到下联数据;本发明达到了人机对对联的实时智能交互。
技术研发人员:黎宇,梁斌,张闪闪
受保护的技术使用者:四川九州电子科技股份有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!