基于过滤和文本增强的跨语言摘要数据集构建方法及系统
本发明涉及新一代信息技术人工智能应用中的跨语言数据处理,特别涉及一种基于过滤和文本增强的跨语言摘要数据集构建方法及系统。
背景技术:
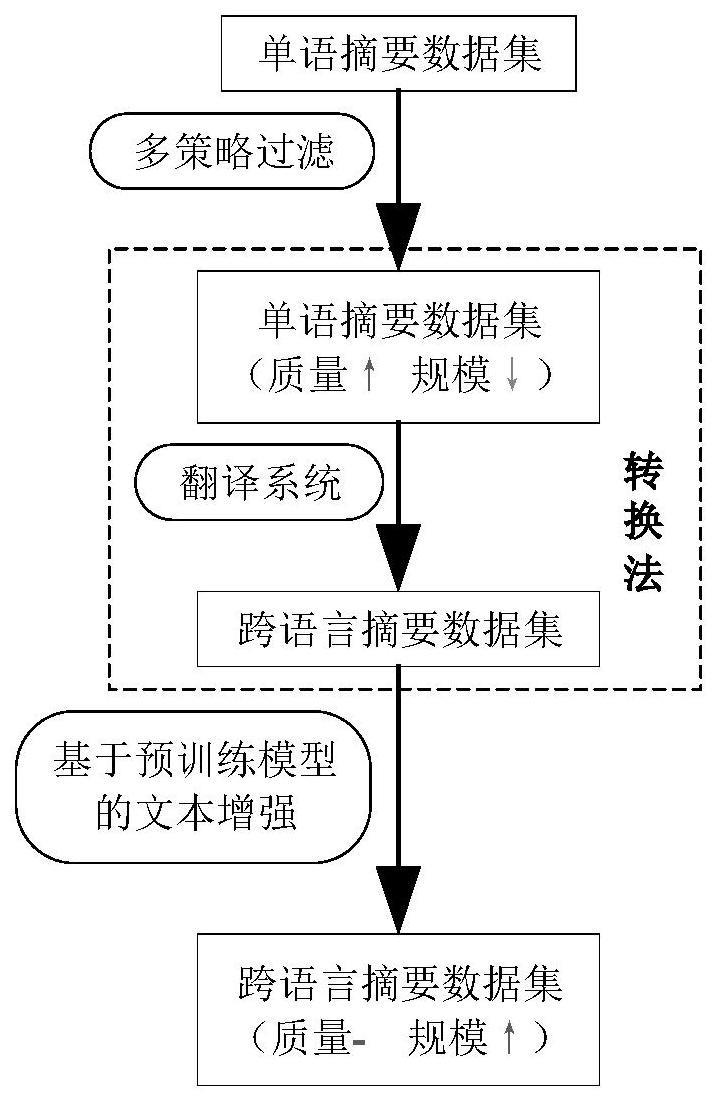
1、跨语言摘要(cross-lingual summarization,cls)指将一种语言的文本转换成另一种语言的摘要,使人们快速有效地从陌生语言的文本中获取信息。其研究方法已从管道方法向端到端方法发展,而端到端方法正引入transformer等深度学习模型。大量工作表明,标注数据的质量和规模直接影响深度学习模型性能。故cls数据集的质量和规模均极为重要。
2、目前,研究者们已通过收集法和转换法构建了一些cls数据集。其中,最具代表性的是采用转换法构建的ncls数据集。收集法所得数据集质量较高,但成本亦高,故规模普遍较小。转换法从其他任务数据集中产生cls数据集,成本低且能保证规模。然而,转换法所得数据集通常包含更多低质量样本,严重影响了相关研究方法的性能。造成此现象的原因有二:一是源数据集的误差。例如ncls数据集的子数据集zh2ensum,该数据来源于lcsts数据集,受限于微博文本特点,其部分摘要对原文的概括性过高。二是转换系统的误差,例如翻译误差等。故,如何以低成本构建质量高且规模大的数据集,是cls研究的一项重要挑战。
技术实现思路
1、为此,本发明提供一种基于过滤和文本增强的跨语言摘要数据集构建方法及系统,解决现有跨语言摘要数据集存在样本质量不一、数据规模低等问题。
2、按照本发明所提供的设计方案,提供一种基于过滤和文本增强的跨语言摘要数据集构建方法,包含:
3、利用过滤策略从字符和语义角度对原始单语摘要数据集进行过滤,并通过翻译系统将过滤后的数据集转换为跨语言摘要数据集;
4、使用自注意力机制和掩码语言模型对跨语言摘要数据集的文本进行动态同义词替换并生成新的文本。
5、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,利用过滤策略从字符和语义角度对原始单语摘要数据集进行过滤,包含:利用无关词统计、关键词统计和语义度量策略分别从字符和语义角度对原始单语摘要数据集进行分析和过滤。
6、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,利用无关词统计策略对原始单语摘要数据集进行分析过滤,包含:
7、首先,将原始单语摘要数据集中未在文本中出现的摘要单词作为无关词,计算摘要中无关词占摘要单词总数的比例;
8、然后,过滤掉比例大于第一预设阈值的样本对。
9、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,利用关键词统计策略对原始单语摘要数据集进行分析过滤,包含:
10、首先,通过word2vec词向量模型从语义角度提取原始单语摘要数据集中文本的关键词,并计算摘要中属于文本关键词的单词占摘要单词总数的比例;
11、然后,过滤掉比例小于第二预设阈值的样本对。
12、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,通过word2vec词向量模型从语义角度提取原始单语摘要数据集中文本的关键词,包含:首先,通过word2vec词向量模型对文本进行编码,并获取单词表示序列;接着,对单词表示序列中全部单词进行聚类,以簇中心为主要关键词,计算其他单词与簇中心的欧式距离;然后,选取距离聚类中心最近的p个单词作为关键词,其中,p为预设整数。
13、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,利用语义度量策略对原始单语摘要数据集进行分析过滤,包含:
14、首先,利用bert词嵌入来获取原始单语摘要数据集中文本和参考摘要的单词表示序列;
15、然后,利用bert-whiteing方法将单词表示序列转化为各向同性,并利用余弦相似度从语义角度衡量参考摘要与原文样本数据相似度,并过滤掉相似度小于第三预设阈值的样本对。
16、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,利用bert-whiteing方法将单词表示序列转化为各向同性,包含:首先,获取文本和参考摘要两者中的单词表示序列的文本表示向量,并将两者的文本表示向量进行统一;接着,对统一后的数据进行白化操作,保留h个主成分,并获取转化后的文本表示向量;然后,依据文本和参考摘要将文本表示向量拆分,以计算两者的相似度。
17、作为本发明基于过滤和文本增强的跨语言摘要数据集构建方法,进一步地,使用自注意力机制和掩码语言模型对跨语言摘要数据集的文本进行动态同义词替换并生成新的文本,包含:
18、首先,使用roberta模型的自注意力并结合上下文信息选择跨语言摘要样本对的文本的单词进行屏蔽,得到屏蔽后的文本序列;
19、接着,利用roberta模型的掩码语言模型预训练任务对屏蔽后的文本序列掩码进行预测,得到新文本;
20、然后,通过将新文本与参考摘要进行组合,生成新的跨语言摘要样本对。
21、进一步地,本发明还提供一种基于过滤和文本增强的跨语言摘要数据集构建系统,包含:数据过滤模块和数据增强模块,其中,
22、数据过滤模块,用于利用过滤策略从字符和语义角度对原始单语摘要数据集进行过滤,并通过翻译系统将过滤后的数据转换为跨语言摘要数据集;
23、数据增强模块,用于使用自注意力机制和掩码语言模型对跨语言摘要数据集进行动态同义词替换并生成新的跨语言摘要文本数据。
24、本发明的有益效果:
25、本发明通过采用多策略过滤去除低质量的单语摘要样本,能够综合、全面地去除低质量的单语摘要样本,极大提升数据集质量,且实现不平行文本的相似性度量;并利用自注意力机制和掩码语言模型来扩充跨语言摘要样本,在保证质量的前提下增大了数据规模,以较低成本获得质量高且规模大的跨语言摘要数据集。
技术特征:
1.一种基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,包含:
2.根据权利要求1所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,利用过滤策略从字符和语义角度对原始单语摘要数据集进行过滤,包含:利用无关词统计、关键词统计和语义度量策略分别从字符和语义角度对原始单语摘要数据集进行分析和过滤。
3.根据权利要求2所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,利用无关词统计策略对原始单语摘要数据集进行分析过滤,包含:
4.根据权利要求2所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,利用关键词统计策略对原始单语摘要数据集进行分析过滤,包含:
5.根据权利要求4所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,通过word2vec词向量模型从语义角度提取原始单语摘要数据集中文本的关键词,包含:首先,通过word2vec词向量模型对文本进行编码,并获取单词表示序列;接着,对单词表示序列中全部单词进行聚类,以簇中心为主要关键词,计算其他单词与簇中心的欧式距离;然后,选取距离聚类中心最近的p个单词作为关键词,其中,p为预设整数。
6.根据权利要求2所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,利用语义度量策略对原始单语摘要数据集进行分析过滤,包含:
7.根据权利要求6所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,利用bert-whiteing方法将单词表示序列转化为各向同性,包含:首先,获取文本和参考摘要两者中的单词表示序列的文本表示向量,并将两者的文本表示向量进行统一;接着,对统一后的数据进行白化操作,保留h个主成分,并获取转化后的文本表示向量;然后,依据文本和参考摘要将文本表示向量拆分,以计算两者的相似度。
8.根据权利要求1所述的基于过滤和文本增强的跨语言摘要数据集构建方法,其特征在于,使用自注意力机制和掩码语言模型对跨语言摘要样本对的文本进行动态同义词替换并生成新的跨语言摘要样本对,包含:
9.一种基于过滤和文本增强的跨语言摘要数据集构建系统,其特征在于,包含:数据过滤模块和数据增强模块,其中,
10.一种电子设备,其特征在于,包括存储器和处理器,所述处理器和所述存储器通过总线完成相互间的通信;所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令能够执行如权利要求1~8任一项所述的方法步骤。
技术总结
本发明涉及跨语言处理领域,特别涉及一种基于过滤和文本增强的跨语言摘要数据集构建方法及系统,通过利用过滤策略从字符和语义角度对原始单语摘要数据集进行过滤,并通过翻译系统将过滤后的数据转换为跨语言摘要数据集;并使用自注意力机制和掩码语言模型对跨语言摘要数据集进行动态同义词替换并生成新的跨语言摘要文本数据。本发明能够综合、全面地去除低质量的单语摘要样本,极大提升数据集质量,且实现不平行文本的相似性度量,且在保证质量的前提下增大了数据规模,能够以较低成本获得质量高且规模大的跨语言摘要数据集。
技术研发人员:席耀一,潘航宇,葛磊,曹蓉,南煜,周会娟,王博,陈宇飞,徐金铭,尤惠彬
受保护的技术使用者:中国人民解放军战略支援部队信息工程大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!