基于混合注意解耦重识别网络的行人重识别方法及设备
本发明涉及计算机视觉,具体涉及一种基于混合注意解耦重识别网络的行人重识别方法及设备。
背景技术:
1、行人重识别是一项具有挑战性的任务,它旨在从非重叠的相机捕获的图库中重新识别给定的查询图像。近年来,该方向在有监督方法上取得了巨大的进步,并被广泛用于图像应用,包括刑事调查、多摄像头跟踪和公共安全。然而,这些在一个数据集上训练的重识别模型经常受到领域偏移的影响,在应用于成像条件与训练数据不同的目标应用场景时表现出明显的性能下降。尽管手动收集和注释目标域训练样本可以缓解领域转移的问题,但这是非常昂贵和耗时的。
2、无监督领域自适应技术可以通过将从有标签的源域学到的知识转移到无标签的目标域,来缩小领域间的差距。一些重识别模型使用基于生成对抗网络的无监督图像到图像的转换来研究这个问题。有标签的源域样本被转换成目标样式,并在没有目标数据标签的情况下用于训练目标重识别模型。然而,这种方法的重识别性能在很大程度上取决于图像生成的质量,当相机成像角度或行人姿态变化较大时,会受到很大影响。
3、目前,主流方法采用基于伪标签的方法。相比较于基于生成对抗网络的方法,基于伪标签的方法能够直接通过生成伪标签来训练目标域模型。这些方法通过一个三步来适应性地调整跨域特征分布:(1)使用有标签的源域训练样本学习行人重识别模型;(2)对目标域训练样本进行聚类,通过从源域训练的重识别模型提取的特征,从而产生伪标签;(3)通过具有伪标签的目标域数据和真实标签的源域样本混合的内存库优化模型。然而,大多数的伪标签方法为了减少错误伪标签的影响而忽略了类的边界样本,这不可避免地牺牲了类内的语义多样性。尽管有些方法采用基于困难样本内存库的方法可以用来发现样本之间的关系和描述类内样本的多样性,但它们容易增加产生不正确的伪标签的风险。
4、基于此,类内多样性和伪标签的准确性是相互矛盾的。增加类内多样性可能会使错误伪标签增加,而增加高置信度的伪标签训练样本可能会影响类内多样性。在跨域行人重识别过程中,如何平衡类内多样性和伪标签的准确性是一个具有挑战性的问题。因此研究一种能够提高行人重识别特征辨别力,且能够学习类内语义多样性的方法,对于行人重识别任务意义重大。
技术实现思路
1、针对上述现有技术存在的不足,本发明提出了一种基于混合注意解耦重识别网络的行人重识别方法。其目的在于解决行人重识别中无法充分学习类内的语义多样性、无法提取具有辨别性的特征表达的问题,以增强领域不变的行人特征的辨别能力,从而形成可靠的类别边界和学习类内语义多样性。
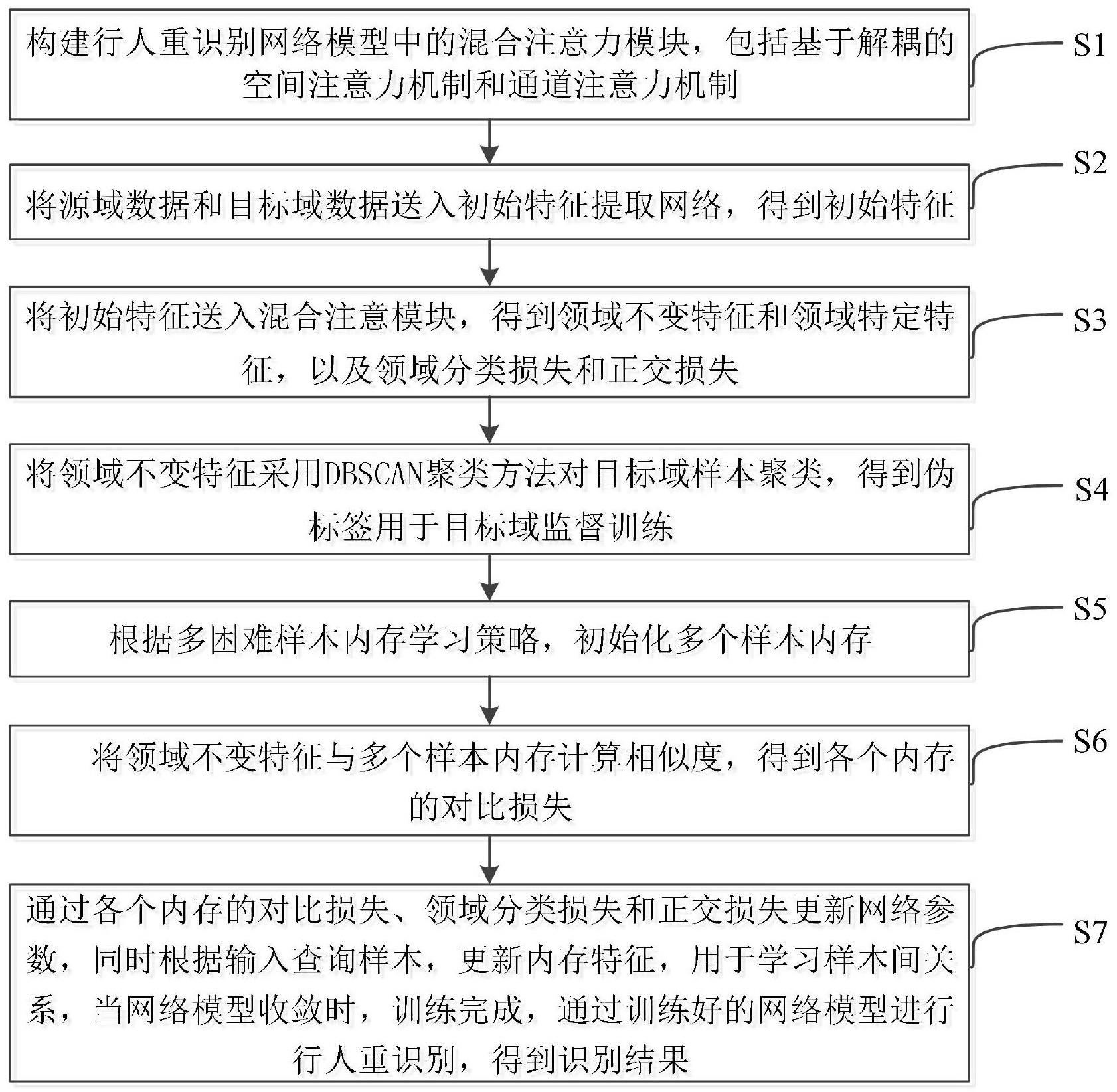
2、为了实现上述目的,本发明提供了一种基于混合注意解耦重识别网络的行人重识别方法,应用于无监督领域自适应的行人重识别中,所述方法包括:
3、构建行人重识别网络模型中的混合注意力模块,包括基于解耦的空间注意力机制和通道注意力机制;
4、将源域数据ds和目标域数据dt送入初始特征提取网络,得到初始特征f;
5、将初始特征送入混合注意模块,得到领域不变特征fdi和领域特定特征fds,以及领域分类损失和正交损失;
6、将领域不变特征fdi采用dbscan聚类方法对目标域样本聚类,得到伪标签用于目标域监督训练;
7、根据多困难样本内存学习策略,初始化多个样本内存;
8、将领域不变特征fdi与多个样本内存计算相似度,得到各个内存的对比损失;
9、通过各个内存的对比损失、领域分类损失和正交损失更新网络参数,同时根据输入查询样本,更新内存特征,用于学习样本间关系,当网络模型收敛时,训练完成,通过训练好的网络模型进行行人重识别,得到识别结果。
10、进一步地,所述构建行人重识别网络模型中的混合注意力模块,包括:
11、构建一个由基于解耦的空间注意力机制和通道注意力机制组成的混合注意力模块;
12、该混合注意力模块用于提取领域不变特征,用于后续识别分类任务。
13、进一步地,所述将源域数据ds和目标域数据dt送入初始特征提取网络,得到初始特征,包括:
14、将具有五个阶段的resnet-50网络作为初始特征提取网络,第五阶段的卷积步长由2变为1,且resnet-50网络已在imagenet上预训练;
15、将源域数据和目标域数据送入预训练后的resnet-50网络,得到初始特征。
16、进一步地,所述将初始特征送入混合注意模块,得到领域不变特征fdi和领域特定特征fds,以及领域分类损失和正交损失,包括:
17、将初始特征送入混合注意模块,首先初始特征经过解耦模块后,得到领域不变权重wi和领域特定权重ws;
18、根据向量正交原则,采用正交损失使得领域不变权重wi和领域特定权重ws相互正交,从而使得领域不变特征和领域特定特征相互独立,正交损失li为:
19、
20、
21、其中和是领域不变权重wi和领域特定权重ws经过平均池化的结果,|| ||2表示l2正则化,| |表示绝对值操作,i[i,j]表示位置(i,j)上的数值属于的数值,b表示每个小批次的样本数量,c表示通道数;
22、根据领域不变权重wi和领域特定权重ws得到领域不变特征fdi和领域特定特征fds,其公式为:
23、wi=edm(f),ws=1-wi
24、
25、其中表示元素相乘,edm为解耦模块;
26、利用领域特定特征fds计算领域分类损失,使得fds包含更多领域特定特征信息,领域分类损失ldom为:
27、ldom=-[dllogp+(1-dl)log(1-p)]
28、p=edc(fds)
29、其中dl是领域标签,源域的领域标签为0,目标域的领域标签为1;edc为领域分类模块,p为领域分类概率。
30、进一步地,所述将领域不变特征fdi采用dbscan聚类方法对目标域样本聚类,得到伪标签用于目标域监督训练,包括:
31、在每轮训练前,使用dbscan进行聚类,对于dbscan中的参数,k-距离中的参数k被设置为30,最小邻居数n被设置为4,对于dukemtmc-reid和market-1501数据集,样本对之间的距离阈值被设置为0.6,对于msmt17数据集,距离阈值为0.7;
32、每轮训练时,目标域中数据的伪标签采用上一轮模型优化后的结果。
33、进一步地,所述根据多困难样本内存学习策略,初始化多个样本内存,包括:
34、多困难内存学习策略由可靠样本内存和多个困难样本内存组成;
35、可靠样本内存和多个困难样本内存采用相同的初始化策略,在每轮训练开始时进行初始化,且都初始化为该类所有实例图像的平均特征,将内存中的每类特征视为样本原型。
36、进一步地,所述将领域不变特征fdi与多个样本内存计算相似度,得到各个内存的对比损失,包括:
37、在可靠样本内存中,通过拉进正样本之间的距离,推远负样本之间的距离,来进行对比学习,在领域内部计算对比损失,可靠样本内存中对比损失如下:
38、
39、
40、其中,表示来自源域样本的对比损失,表示来自目标域样本的对比损失,ns和nt分别表示源域和目标域的类别数,qs和qt分别表示来自源域和目标域的查询样本,c+是内存库中与查询相同标签的正原型,和表示该查询样本对应的负原型样本,τ为超参数,设置为0.05;
41、在困难样本内存中,采用两个困难样本内存,通过在每个困难样本内存内部计算相似度,采用与可靠样本内存一致的学习策略,得到困难样本内存中对比损失为:
42、
43、其中,表示第n个困难样本内存的损失函数,q为来自目标域的查询样本,h+表示内存库中与查询样本相同的伪标签的困难正原型,hi表示该查询样本对应的负原型样本。
44、进一步地,所述通过各个内存的对比损失、领域分类损失和正交损失更新网络参数,同时根据输入查询样本,更新内存特征,用于学习样本间关系,当网络模型收敛时,训练完成,通过训练好的网络模型进行行人重识别,得到识别结果,包括:
45、行人重识别网络模型的整体框架损失包括:可靠样本内存对比损失、多个困难样本内存对比损失、正交损失和领域分类损失,每个小批次中有n个源域查询和n个目标域查询总体损失函数如下:
46、
47、这里和分别为可靠样本内存中的来自源域和目标域的训练损失,为来自困难样本内存的损失,n为困难样本内存的数量,li为正交损失,ldom为领域分类损失,μ和θ为超参数,μ被设置为0.5,θ被设置为4。
48、除了通过所述总体损失函数优化网络模型参数外,还通过查询样本来更新内存原型;
49、针对困难样本内存原型的更新,每个困难样本内存库中的原型由困难查询特征更新,这些特征在小批量中共享相同的伪标签,同时在相似度排序组合中具有较低的相似度,通过使用argsort函数对相似度从小到大进行排序,按照以下方式选择查询特征:
50、
51、其中,k是每个小批量中属于同一伪标签集群的实例特征的数量,ri是可靠样本内存库中第i个查询样本的正原型,为每个小批量中属于第i个伪标签集群的实例特征中的第k个查询样本,这里和ri属于同一伪标签;用可靠样本内存库中的正原型来代表聚类中心点,计算查询特征与可靠样本内存库中的正原型之间的相似度,进而获得相似度排列组合;
52、困难样本内存原型更新策略为:
53、
54、其中,表示第n个困难样本内存库中第i个查询的困难正原型,表示相似度排列组合index中第n个查询样本,α是动量系数;
55、在可靠样本内存更新过程中,使用目标域中的可靠样本来更新可靠样本内存原型,通过使用相似度排列组合来确定查询样本和可靠样本记忆库中相应的正面原型之间的相似度,识别出相似度较低的困难样本,并在随后的可靠记忆更新中进行剔除;源域的所有样本都被标记为可靠的,适合立即使用,可靠样本内存原型更新策略为:
56、
57、公式中ci表示第i个查询样本的正原型样本,在源域中,表示小批量中第i个查询的实例样本的平均值;在目标域中,表示去除困难样本后第i个查询的平均值;
58、随着反向传播优化更新网络模型参数和内存原型更新,从而使网络获得更具辨别力的特征,同时充分学习数据类内多样性,当网络模型收敛时,训练完成,通过训练好的网络模型进行行人重识别,得到识别结果。
59、此外,为了实现上述目的,本发明还提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现所述的行人重识别方法的步骤。
60、此外,为了实现上述目的,本发明还提供了一种存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现所述的行人重识别方法的步骤。
61、本发明针对无监督领域自适应行人重识别中无法充分学习类内的语义多样性、无法提取具有辨别性的特征表达的问题进行考虑,提出了一种基于混合注意解耦重识别网络的行人重识别方法,以增强领域不变的行人特征的辨别能力,从而形成可靠的类别边界和学习类内语义多样性。通过设计混合注意模块可以从空间和通道的角度,以注意力权重解耦的方式加强领域不变的特征表达,这迫使网络自动利用有利于跨领域重识别的图像区域和属性线索。此外,基于增强的领域不变特征表达,提出了一种多困难样本内存学习策略,以提高目标域样本的类内多样性。本发明通过更新可靠样本内存库和多个困难样本内存库来优化特征学习过程,通过考虑同一类别内各个样本之间的关系,可以用来捕获显著的类内语义变化,同时能够对伪标签的准确性产生积极影响。
- 还没有人留言评论。精彩留言会获得点赞!