一种考虑由物品口碑因素导致一致性偏差的推荐方法
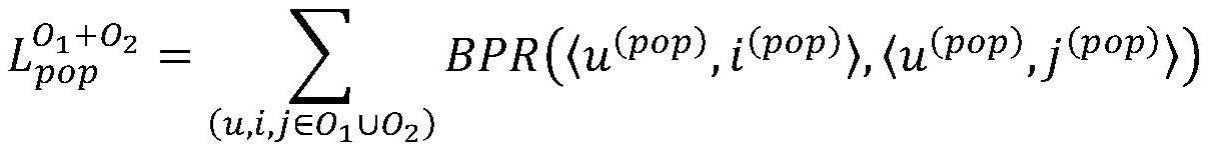
本发明属于人工智能,具体涉及一种考虑由物品口碑因素导致一致性偏差的推荐方法。
背景技术:
1、推荐系统能够在用户没有明确需求的情况下,从用户的历史交互数据中挖掘用户偏好,为每个用户提供个性、精准、快速的内容筛选和推送,被认为是缓解信息过载的最有效方法。当前大多数研究旨在发明一些机器学习模型来不断拟合用户行为历史数据,但是由于用户在与推荐系统的交互过程中,可能会受到某些因素的影响,从而做出不符合自己本意的行为,导致推荐系统收集的反馈数据就会存在各种偏差。如果直接利用存在偏差的数据来训练模型,可能会使得模型无法完全准确挖掘出用户的偏好,以至于无法推荐给用户合适的符合要求的物品,从而降低推荐效果,影响用户体验。
2、推荐系统中的一致性偏差是指,用户受到大众或者朋友的影响,会倾向于给出与他人类似的反馈行为,即使这并不符合自己的本意。例如,用户可能仅仅因为许多其它用户点击了某个物品而点击该物品,事实上,这些交互主要是由用户的一致性驱动的,而不是由用户真正的兴趣驱动。一致性描述了用户倾向于跟随他人做出相似交互行为的一种现象,是用户做出决策考虑的一个关键因素。同时,不同的用户对不同的物品的一致性也有所不同。也有研究表明,披露物品评分会影响个人的决策以及他们对物品的质量和价值的看法,评级系统并不是简单的汇总个人意见,而是创造一个以系统方式影响后续评级的环境。现实生活中,随着信息的爆炸式增长,我们的决策也越来越依赖于他人提供的综合意见。例如,我们倾向于在网上查看电影的评分和评论后,再选择观看某一部电影。同时,我们也会在点评网站上查看各种餐馆的评价后,再决定是否选择某家餐馆,这些都是一致性的表现。
3、为了证明推荐系统中一致性偏差的存在,有研究通过对豆瓣数据集中的电影评分进行分析,证明了在线评级网站中一致性偏差的存在,评级分布与用户收到的公众意见明显相关。而为了缓解一致性偏差,有些研究均考虑通过建模社会因素对用户行为产生的影响,进而引入特定参数来调节一致性偏差。也有研究利用因果推理来解决一致性偏差,每个用户的一致性偏差是基于因果图通过数据学习到的一种嵌入,最终保证了算法的可解释性和健壮性。
4、目前推荐系统中关于一致性偏差的解决方案,主要使用统一的标量偏差项来表示一致性偏差,然而同一个用户对于不同的物品的一致性偏差并不相同,不同的用户对同一个物品的一致性偏差也并不相同。因此,仅仅使用统一的标量偏差项会忽略一致性偏差的多样性。为了解决这个问题,有的研究提出了一种基于因果嵌入来解耦兴趣和一致性偏差的推荐框架,并且为了捕捉一致性偏差的多样性,他们不再使用简单的标量人气值,而是单独学习一致性偏差嵌入。
5、物品人气和物品口碑都是物品不同维度特征的两个独立方面,而它们的提前披露则是导致一致性偏差的主要原因。具体来说,物品口碑代表的是物品的质量和性价比,是用户与物品在互动之后才产生的反馈。而物品人气代表物品的受欢迎程度,则反映了商品在一定时期内对用户的吸引力程度。用户与物品的历史互动次数通常用于表示物品受欢迎程度,也就是物品人气,而物品的评分通常用于表示物品口碑。随着时间的推移,该物品的受欢迎程度可能会发生大幅度的变化,而该物品的口碑通常更稳定。
6、用户在与物品进行交互过程中,不仅会受到物品人气的影响,选择点击热度较高的物品,也会受到先前其它用户评分的影响,选择评分较高的物品,由此可见,由物品口碑和物品人气两种因素都可以导致一致性偏差的存在。因此,为了更加准确和全面的捕捉一致性偏差嵌入,进而提升推荐算法的准确率,由物品口碑和物品人气两种因素导致的一致性偏差都理应被考虑和捕捉。
技术实现思路
1、基于上述问题,本发明目的是提供一种考虑由物品口碑因素导致一致性偏差的推荐方法,该方法基于现有因果嵌入模型dice进行设计。考虑在原有框架因果图基础上加入物品口碑因素,对基于因果嵌入的解决一致性偏差的推荐框架进行补充完善和优化。在计算出各个物品的口碑值的基础上,通过本发明设计的负样本策略将正负样本按照1:n的比例进行组合成训练样本,然后根据点击背后的驱动因素不同将训练样本分成四个数据子集,最后通过数据子集的不同组合来训练用户兴趣、物品人气、物品口碑等三种不同的嵌入,最后根据嵌入来产生推荐结果。在考虑由物品口碑因素导致一致性偏差之后,本发明方法不仅能成功学习到由物品口碑导致的一致性偏差嵌入,而且也能拥有更高的推荐准确率和较高的可解释性。
2、本发明提供的一种考虑由物品口碑因素导致一致性偏差的推荐方法,包括如下步骤:
3、步骤1:计算movielens-10m数据集中物品的人气值和口碑值;
4、在本发明的设计思路中,主要是通过使用不同的数据子集的组合来训练不同的嵌入来学习得到三种因果嵌入,而数据子集则是根据正负样本人气值和口碑值的大小关系来划分的。本发明使用movielens-10m数据集,因此,需要先计算数据集中物品的人气值和口碑值,人气值和口碑值的计算包括以下步骤:
5、步骤1.1:对movielens-10m数据集中的数据进行预处理;
6、本发明使用movielens-10m数据集,但是并不需要数据集中的全部信息,并且数据集中也并不包含本发明所需要的人气值和口碑值等信息,所以首先需要进行数据预处理。具体实现包括以下步骤:
7、步骤1.1.1:随机抽取movielens-10m数据集中的m个数据,形成新的数据集q,并按照一定的格式进行存储;
8、movielens-10m数据集中包含三个文件:movies.dat、ratings.dat、tags.dat,主要选用rating.dat文件,其中包含了72000个用户对于10000部电影的评级数据,本文随机抽取了37962个用户对4819个物品的交互记录,以并(用户id,物品id,评分值,是否交互)的格式并另存为.npz文件;
9、步骤1.1.2:将数据集q分为训练集q1和测试集q2,并分别进行存储;
10、为了便于进行后续模型的训练、验证和测试,将步骤1.1.1中生成的.npz格式的数据集按照6:4的比例随机划分为训练集和测试集,并另存两个.npz文件;
11、步骤1.2:计算训练集q1中每个物品的人气值,将计算得到的人气值形成一个一维数组;
12、为了能够学习到由物品人气值导致的一致性偏差的因果嵌入,需要利用步骤1.1.2中生成的训练集数据文件对4819个物品的人气值进行计算。对于物品i,其人气值pi的计算公式如下:
13、
14、其中,u代表某个用户,u代表整个用户集合,ml代表用户和物品的二进制交互矩阵。
15、最后对4819个物品通过计算得到一个长度为4819的ndarray数组,并另存为.npy文件;
16、步骤1.3:计算训练集q1中每个物品的口碑值,将计算得到的口碑值形成一个一维数组;
17、为了能够学习到由物品口碑值导致的一致性偏差的因果嵌入,需要利用步骤1.1.2中生成的训练集数据文件对4819个物品的口碑值进行计算。对于物品i,其口碑值ri的计算公式如下:
18、
19、其中,u代表某个用户,u代表整个用户集合,n则代表用户的个数,mr代表用户和物品的二进制交互矩阵。
20、最后对4819个物品通过计算得到一个长度为4819的ndarray数组,并另存为.npy文件;
21、步骤2:考虑由物品口碑导致的一致性偏差,构建面向一致性偏差问题的因果嵌入推荐模型,包括:
22、步骤2.1:生成训练样本,包括如下步骤:
23、步骤2.1.1:对于步骤1.1.2中的训练集文件,文件中的每一行记录均可生成一个训练样本,从该训练集文件中取出记录的用户id,物品id分别作为训练样本中的用户和正样本;
24、步骤2.1.2:为步骤2.1.1中的用户和正样本进行负样本采样,生成n个负样本;
25、步骤2.1.3:将步骤2.1.1中的一个用户和一个正样本和步骤2.1.2中的n个负样本组合成训练样本;
26、步骤2.1.4:将步骤2.1.3中生成的训练样本进行分类,分以下四种情况,如果训练样本中正样本的人气和口碑均高于负样本的人气和口碑,则将该训练样本归类为o1集合;如果训练样本中正样本的人气高于负样本,且正样本的口碑低于负样本,则将该训练样本归类为o2集合;如果训练样本中正样本的人气低于负样本,且正样本的口碑高于负样本,则将该训练样本归类为o3集合;如果训练样本中正样本的人气和口碑均低于负样本的人气和口碑,则将该训练样本归类为o4集合;
27、步骤2.1.5:将步骤2.1.4生成的四类训练样本集合作为模型的输入进行模型训练;
28、步骤2.2:构建考虑物品口碑导致的一致性偏差问题的因果嵌入推荐模型;包括如下步骤:
29、步骤2.2.1:设计因果嵌入特征提取网络,所述特征提取网络用于提取和学习用户兴趣、物品人气和物品口碑三种因果嵌入,模型的设计如图2所示,具体实现步骤如下所示:
30、步骤2.2.1.1:构建物品人气建模的损失函数:
31、从步骤2.1.5中生成的数据子集o1,o2,o3,o4的策略可以看出,四类训练样本都包含正样本和负样本的物品人气大小关系,因此均可以用来训练和挖掘物品和用户的人气特征。使用bpr损失函数来最大化正样本与负样本之间的得分,因此,物品人气建模的损失函数如下所示:
32、
33、
34、其中,u代表用户,i代表正样本,j代表正样本,u(pop)、i(pop)、j(pop)分别代表用户、正样本、负样本的人气嵌入,表示物品人气建模在数据子集o1和数据子集o2上的损失函数,表示物品人气建模在数据子集o3和数据子集o4上的损失函数,bpr()表示bayesian personalized ranking损失函数,可以使得正样本和负样本之间的差值尽可能大。
35、步骤2.2.1.2:构建物品口碑建模的损失函数:
36、从步骤2.1.5中生成的数据子集o1,o2,o3,o4的策略可以看出,四类训练样本都包含正样本和负样本的物品口碑大小关系,因此均可以用来挖掘物品口碑特征。因此,物品口碑建模的损失函数如下所示:
37、
38、
39、其中,u代表用户,i代表正样本,j代表正样本,u(rep)、i(rep)、j(rep)分别代表用户、正样本、负样本的口碑嵌入,表示物品口碑建模在数据子集o1和数据子集o3上的损失函数,表示物品口碑建模在数据子集o2和数据子集o4上的损失函数。
40、步骤2.2.1.3:构建用户兴趣建模的损失函数
41、从步骤2.1.5中生成的数据子集01,02,03,04的策略可以看出,只有第四类训练样本可以推导出正样本和负样本的用户兴趣大小关系,因此使用数据子集o4可以用来训练用户兴趣嵌入。因此,用户兴趣建模的损失函数如下所示:
42、
43、其中,u代表用户,i代表正样本,j代表正样本,u(int)、i(int)、j(int)分别代表用户、正样本、负样本的兴趣嵌入。
44、步骤2.3:构建预测点击任务的损失函数
45、将用户的人气嵌入u(pop)、口碑嵌入u(rep)和兴趣嵌入u(int)直接拼接作为用户的特征表示u′,将物品的人气嵌入i(pop)、口碑嵌入i(rep)和兴趣嵌入i(int)直接连接作为物品的特征表示i′。预测点击任务的损失函数如下所示:
46、
47、式中,<u′,i′>表示用户特征和正样本特征之间的内积,<u′,j′>表示用户特征和负样本特征之间的内积;其中u′=u(int)||u(pop)||u(rep),i′=i(int)||i(pop)||i(rep),j′=j(int)||j(pop)||j(rep);
48、步骤2.4:构建独立性监督任务的损失函数
49、使用e(int)、e(pop)、e(rep)分别表示所有用户和物品的兴趣嵌入、人气嵌入和口碑嵌入,为了保证物品人气、物品口碑和用户兴趣三种因果嵌入之间两两独立性,本文采用距离相关系数dcor来计算两个特征之间的相关程度,因此,独立性监督任务的损失函数如下:
50、
51、式中,dcor(e(int),e(pop))表示兴趣嵌入和人气嵌入之间的距离相关系数,dcor(e(int),e(rep))表示兴趣嵌入和口碑嵌入之间的距离相关系数,dcor(e(pop),e(rep))表示人气嵌入和口碑嵌入之间的距离相关系数;
52、步骤2.5:构建总体损失函数l;
53、使用多任务学习方法将五个不同任务的损失函数结合在一起共同训练,总体损失函数l为:
54、
55、其中,α为学习因果嵌入任务的权重,β为独立性监督任务的权重。
56、步骤3:使用训练样本对构建的因果嵌入推荐模型进行训练;
57、此步骤使用pytorch来构建步骤2.2中设计的模型结构,使用步骤2.1生成的训练样本来进行训练,具体的训练过程包括以下几个子步骤:
58、步骤3.1:初始化网络参数;
59、网络训练初始化包括以下内容:三种因果嵌入的维度为64,负样本数目设置为6,学习因果嵌入任务的权重预训练α为0.8,独立性监督任务的权重β为0.8;
60、步骤3.2:设置迭代次数,对模型进行迭代训练,将训练得到的嵌入保存至.pth文件;
61、迭代次数设置为500次,设置早停机制,当推荐模型的性能在最新的10次迭代过程中不再提升时,将终止模型的训练,将训练得到的嵌入保存至.pth文件,至此训练结束;
62、步骤4:利用测试集作为训练后的模型输入,输出预测结果。
63、将步骤1.1.2中生成的测试集q2作为模型的输入进行预测,主要包括以下步骤:
64、步骤4.1:对测试集中的某个用户,获取推荐列表;包括:
65、步骤4.1.1:根据步骤3.2得到的关于用户的三种嵌入.pth文件得到该用户的嵌入;
66、步骤4.1.2:根据步骤3.2得到的关于物品的三种嵌入.pth文件得到所有物品的嵌入;
67、步骤4.1.3:将步骤4.1.1得到的用户嵌入和步骤4.1.2得到的物品嵌入输入以下公式,得到匹配得分,取匹配得分最高的前k个物品作为推荐列表(k={20,50});
68、score(u,i)=<u′,i′>
69、式中,score(u,i)表示用户u对物品i的匹配得分,<u′,i′>表示用户特征u′与物品特征i′之间的内积。
70、本发明的有益效果是:
71、本发明提出了一种考虑由物品口碑因素导致一致性偏差的推荐方法,将一致性偏差划分为与人气相关的一致性偏差和与口碑相关的一致性偏差,并通过负样本划分策略将训练数据集合按照交互行为潜藏的驱动因素划分为不同原因的四组训练子集合,然后通过四组训练数据子集合的不同组合来训练三个因果嵌入从而得到细化的因果特征,以实现三种因果嵌入的独立学习,从而解耦了用户兴趣、物品人气、物品口碑三种因果嵌入,最后通过将用户和物品之间的推荐得分细化为用户兴趣得分、物品口碑得分和热度得分,为用户产生推荐结果,使得模型很容易根据相应的得分来解释用户点击物品的具体因素,提升了一定可解释性的同时,也对推荐的准确率有所提高。
- 还没有人留言评论。精彩留言会获得点赞!