处理数据表的方法及系统与流程
本发明总体说来涉及数据处理领域,更具体地讲,涉及一种处理数据表的方法及系统。
背景技术:
1、随着各行业海量数据的出现,需要在越来越多的场景下对数据进行各种处理,例如,数据表拼接、特征提取等处理。
2、神经网络虽然在图像、语音、文本等输入较为标准的领域比较通用,但对于数据集多样、数据表较多的场景下的机器学习问题依然没有通用的方案,通常需要人工手动进行多表拼接、特征提取,然后再基于提取的特征使用神经网络进行机器学习模型训练或机器学习模型预测。
技术实现思路
1、本发明的示例性实施例在于提供一种处理数据表的方法及系统,其能够使用特定结构的神经网络来实现数据表拼接及特征提取。
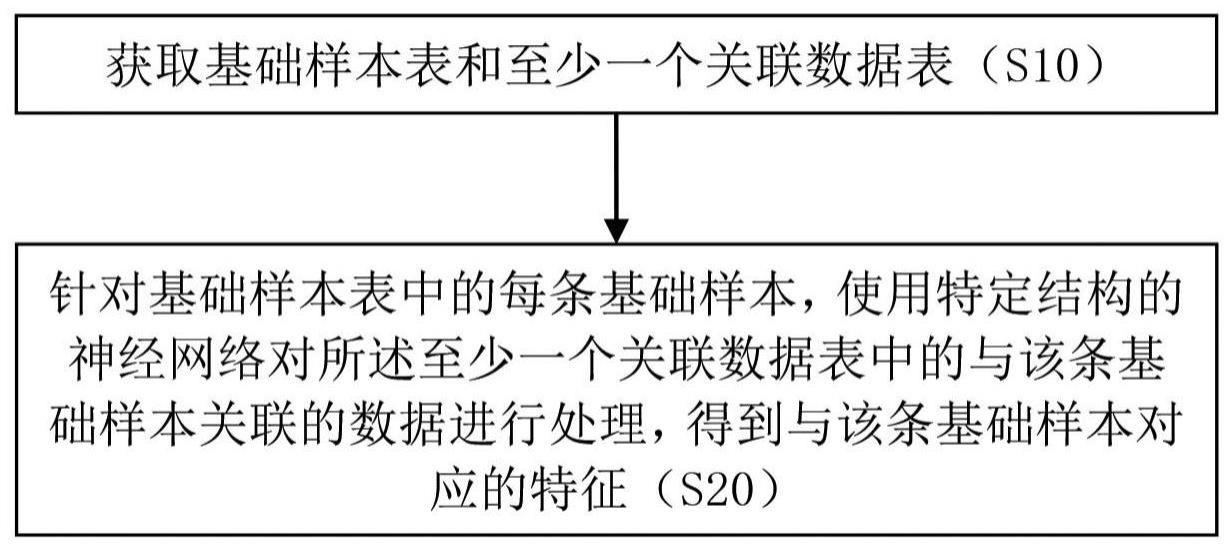
2、根据本发明的示例性实施例,提供一种处理数据表的方法,包括:获取基础样本表和至少一个关联数据表;针对基础样本表中的每条基础样本,使用特定结构的神经网络对所述至少一个关联数据表中的与该条基础样本关联的数据进行处理,得到与该条基础样本对应的特征。
3、可选地,所述至少一个关联数据表包括:至少一个静态表和/或至少一个流水表。
4、可选地,基础样本表中的字段包括:至少一个主体id字段、时间字段和标签字段;所述至少一个静态表的主键是主体id字段;所述至少一个流水表的主键是主体id字段和时间字段。
5、可选地,所述特定结构的神经网络包括:多个隐藏层、第一拼接层、第二拼接层和融合层,其中,针对基础样本表中的每条基础样本,使用特定结构的神经网络对所述至少一个关联数据表中的与该条基础样本关联的数据进行处理,得到与该条基础样本对应的特征的步骤包括:针对基础样本表中的每条基础样本,将每个静态表中与该条基础样本对应的数据记录中属于每种字段类型的字段的字段值,输入到所述多个隐藏层之中与该字段类型对应的隐藏层,其中,与所述至少一个静态表中的各个字段类型一一对应的隐藏层的输出作为第一拼接层的输入;针对基础样本表中的每条基础样本,将每个流水表中与该条基础样本对应的数据记录中属于每种字段类型的字段的字段值,输入到所述多个隐藏层之中与该字段类型对应的隐藏层,其中,与所述至少一个流水表中的各个字段类型一一对应的隐藏层的输出经由第二拼接层作为所述多个隐藏层中的特定隐藏层的输入;将所述融合层输出的向量作为:与基础样本表中的每条基础样本对应的特征,其中,第一拼接层的输出和所述特定隐藏层的输出作为所述融合层的输入,其中,所述特定隐藏层的输入为向量序列,且输出为固定维度的向量。
6、可选地,与所述至少一个静态表中的类别型字段对应的隐藏层为:第一嵌入层,其中,第一嵌入层的输出为嵌入向量;与所述至少一个静态表中的时间字段对应的隐藏层为:做差层,其中,所述做差层用于将静态表中的时间字段的字段值与基础样本表中的时间字段的字段值做差;与所述至少一个流水表中的类别型字段对应的隐藏层为:第二嵌入层,其中,第二嵌入层的输出为嵌入向量。
7、可选地,与所述至少一个静态表中的数值型字段对应的隐藏层为:第一全连接层;与所述至少一个流水表中的数值型字段对应的隐藏层为:第二全连接层。
8、可选地,将每个流水表中与该条基础样本对应的数据记录中属于每种字段类型的字段的字段值,输入到所述多个隐藏层之中与该字段类型对应的隐藏层的步骤包括:针对基础样本表中的每条基础样本,针对每个流水表将该流水表之中至少一个主体id字段的字段值与该条基础样本的相同的数据记录按照其时间字段值进行排序,并从排序后的数据记录中确定时间字段值在该条基础样本的时间字段值之前的n条数据记录;针对该流水表中的每个类别型字段,按照所述n条数据记录的排序,将所述n条数据记录中该类别型字段的字段值排序为对应的时间序列,并将得到的时间序列输入到第二嵌入层;针对该流水表中的每个数值型字段,按照所述n条数据记录的排序,将所述n条数据记录中该数值型字段的字段值排序为对应的时间序列,并将得到的时间序列输入到第二全连接层。
9、可选地,所述特定隐藏层为由长短期记忆网络lstm构成的隐藏层。
10、可选地,所述特定结构的神经网络还包括:第三全连接层和输出层,其中,所述融合层的输出经由第三全连接层作为输出层的输入,其中,输出层用于输出预测的结果。
11、可选地,基础样本表中的主体id字段包括用户id字段,标签字段指示信用卡申请评分;所述至少一个静态表包括以下项之中的至少一项:用户信息表、资产表、人行征信信息表;所述至少一个流水表包括:银行交易流水表。
12、可选地,基础样本表中的主体id字段包括用户id字段和商品id字段,标签字段指示用户是否会购买该商品;所述至少一个静态表包括以下项之中的至少一项:用户信息表和商品信息表;所述至少一个流水表包括:互联网用户行为记录表。
13、根据本发明的另一示例性实施例,提供一种处理数据表的系统,包括:数据表获取装置,适于获取基础样本表和至少一个关联数据表;数据表处理装置,适于针对基础样本表中的每条基础样本,使用特定结构的神经网络对所述至少一个关联数据表中的与该条基础样本关联的数据进行处理,得到与该条基础样本对应的特征。
14、可选地,所述至少一个关联数据表包括:至少一个静态表和/或至少一个流水表。
15、可选地,基础样本表中的字段包括:至少一个主体id字段、时间字段和标签字段;所述至少一个静态表的主键是主体id字段;所述至少一个流水表的主键是主体id字段和时间字段。
16、可选地,所述特定结构的神经网络包括:多个隐藏层、第一拼接层、第二拼接层和融合层,其中,数据表处理装置适于针对基础样本表中的每条基础样本,将每个静态表中与该条基础样本对应的数据记录中属于每种字段类型的字段的字段值,输入到所述多个隐藏层之中与该字段类型对应的隐藏层,其中,与所述至少一个静态表中的各个字段类型一一对应的隐藏层的输出作为第一拼接层的输入;数据表处理装置适于针对基础样本表中的每条基础样本,将每个流水表中与该条基础样本对应的数据记录中属于每种字段类型的字段的字段值,输入到所述多个隐藏层之中与该字段类型对应的隐藏层,其中,与所述至少一个流水表中的各个字段类型一一对应的隐藏层的输出经由第二拼接层作为所述多个隐藏层中的特定隐藏层的输入;数据表处理装置适于将所述融合层输出的向量作为:与基础样本表中的每条基础样本对应的特征,其中,第一拼接层的输出和所述特定隐藏层的输出作为所述融合层的输入,其中,所述特定隐藏层的输入为向量序列,且输出为固定维度的向量。
17、可选地,与所述至少一个静态表中的类别型字段对应的隐藏层为:第一嵌入层,其中,第一嵌入层的输出为嵌入向量;与所述至少一个静态表中的时间字段对应的隐藏层为:做差层,其中,所述做差层用于将静态表中的时间字段的字段值与基础样本表中的时间字段的字段值做差;与所述至少一个流水表中的类别型字段对应的隐藏层为:第二嵌入层,其中,第二嵌入层的输出为嵌入向量。
18、可选地,与所述至少一个静态表中的数值型字段对应的隐藏层为:第一全连接层;与所述至少一个流水表中的数值型字段对应的隐藏层为:第二全连接层。
19、可选地,数据表处理装置适于针对基础样本表中的每条基础样本,针对每个流水表将该流水表之中至少一个主体id字段的字段值与该条基础样本的相同的数据记录按照其时间字段值进行排序,并从排序后的数据记录中确定时间字段值在该条基础样本的时间字段值之前的n条数据记录;针对该流水表中的每个类别型字段,按照所述n条数据记录的排序,将所述n条数据记录中该类别型字段的字段值排序为对应的时间序列,并将得到的时间序列输入到第二嵌入层;并针对该流水表中的每个数值型字段,按照所述n条数据记录的排序,将所述n条数据记录中该数值型字段的字段值排序为对应的时间序列,并将得到的时间序列输入到第二全连接层。
20、可选地,所述特定隐藏层为由长短期记忆网络lstm构成的隐藏层。
21、可选地,所述特定结构的神经网络还包括:第三全连接层和输出层,其中,所述融合层的输出经由第三全连接层作为输出层的输入,其中,输出层用于输出预测的结果。
22、可选地,基础样本表中的主体id字段包括用户id字段,标签字段指示信用卡申请评分;所述至少一个静态表包括以下项之中的至少一项:用户信息表、资产表、人行征信信息表;所述至少一个流水表包括:银行交易流水表。
23、可选地,基础样本表中的主体id字段包括用户id字段和商品id字段,标签字段指示用户是否会购买该商品;所述至少一个静态表包括以下项之中的至少一项:用户信息表和商品信息表;所述至少一个流水表包括:互联网用户行为记录表。
24、根据本发明的另一示例性实施例,提供一种包括至少一个计算装置和至少一个存储指令的存储装置的系统,其中,所述指令在被所述至少一个计算装置运行时,促使所述至少一个计算装置执行如上所述的处理数据表的方法。
25、根据本发明的另一示例性实施例,提供一种存储指令的计算机可读存储介质,其中,当所述指令被至少一个计算装置运行时,促使所述至少一个计算装置执行如上所述的处理数据表的方法。
26、根据本发明示例性实施例的处理数据表的方法及系统,通过使用特定结构的神经网络来实现数据表拼接及特征提取。进一步地,通过将数据表拼接及特征提取步骤融入到神经网络的结构中,能够实现基于指定的数据表通过神经网络自动生成机器学习模型或进行机器学习模型预测。
27、将在接下来的描述中部分阐述本发明总体构思另外的方面和/或优点,还有一部分通过描述将是清楚的,或者可以经过本发明总体构思的实施而得知。
- 还没有人留言评论。精彩留言会获得点赞!