一种基于动态范围的深度强化学习塑造奖励方法
本发明涉及深度强化学习中稀疏奖励环境问题,特别是一种基于动态范围的深度强化学习塑造奖励方法。
背景技术:
1、强化学习提供了一个强大的框架,能够通过对当前环境的观察进行交互去完成特定的任务。在强化学习中,智能体在与环境进行交互之后就会得到奖励,奖励根据环境的反馈所得。在当前,已经有很多优秀的算法能为我们提供方案去训练出一个好策略,解决了大部分的问题,但是,也需要考虑环境规模过大以及不合适的奖励函数都会严重影响强化学习算法的性能。对于许多现实世界的问题(如机器人、自动驾驶),难点就在于现实世界的环境规模太大和难以定义一种合适的奖励函数。设计一种合适的奖励函数,往往只能根据是否完成了任务的标准,只有达到任务的标准,才能获得奖励,这是强化学习中所谓的稀疏奖励。
2、在稀疏奖励的背景下,让智能体更快地学会完成给定的目标任务成为了近些年研究的潮流,例如,通过改变对样本采样的概率来提高样本利用率和训练速度;通过设置不同难度梯度的课程来加速学习,类似人类学习的过程,从简单的问题学习到的策略能够迁移到复杂的问题中;还可以在失败的经验中学习有用的信息等等。但是这些方案在面对大规模的稀疏奖励环境时,由于环境状态空间过大,从而导致算法性能表现不足。
技术实现思路
1、发明目的:本发明的目的是提供一种基于动态范围的深度强化学习塑造奖励方法,从而更科学地提升强化学习算法在稀疏奖励环境中的性能,推进对强化学习中稀疏奖励问题的研究。
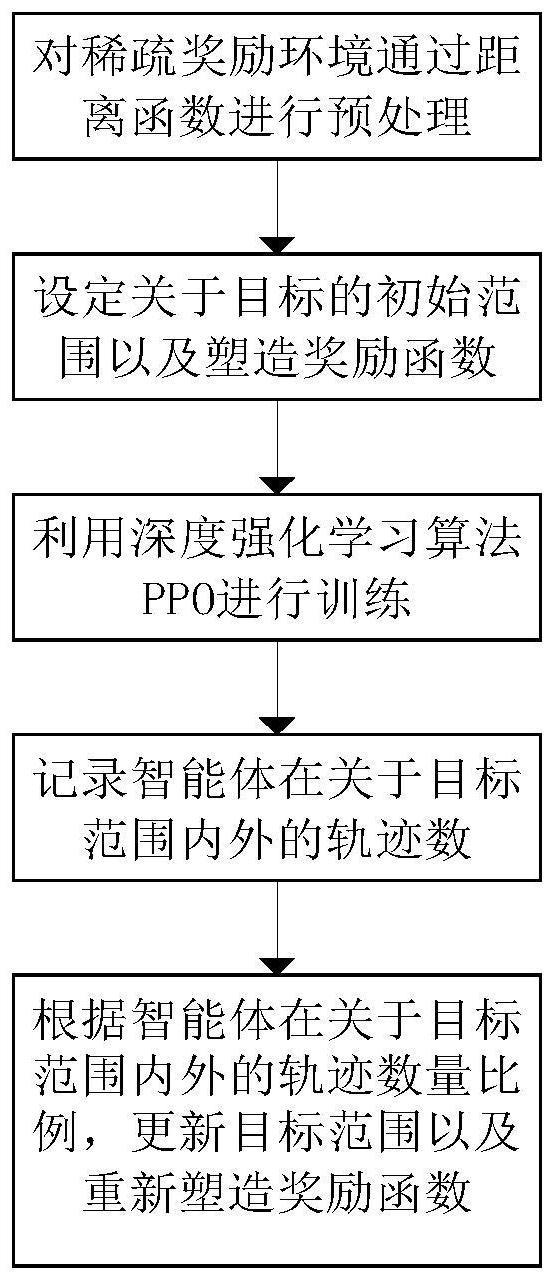
2、技术方案:本发明所述的一种基于动态范围的深度强化学习塑造奖励方法,包括以下步骤:
3、步骤1、对稀疏奖励环境通过距离函数进行预处理。
4、通过距离函数d(x,y)采集强化学习环境中的外部信息,形成对环境的初步勘察,记录环境规模大小,存入txt文件中,形成强化学习环境外部数据集。
5、步骤2、设定关于目标的初始范围以及塑造奖励函数,关于目标的初始范围用δ0表示;塑造奖励函数公式如下:
6、
7、式中,st为智能体的最终状态,g为目标状态。
8、步骤3、利用深度强化学习算法ppo进行训练。
9、步骤3.1、根据智能体与强化学习环境交互设计状态集合和动作集合。
10、步骤3.2、根据每条轨迹中的状态转移矩阵计算各自的奖励值。
11、步骤3.3、将状态集合作为输入,输入到ppo进行训练。
12、步骤4、记录智能体在关于目标范围内外的轨迹数,将在目标范围内的轨迹数记录于uin,在目标范围外的轨迹数记录于uout。
13、步骤5、根据智能体在关于目标范围内外的轨迹数量比例,更新目标范围以及重新塑造奖励函数。
14、步骤5.1、当关于目标范围内外的轨迹数量比例大于参数ρ时,能够实现更新目标范围,从目标范围δ0更新为δ1,并且奖励函数随之变化,公式如下:
15、
16、式中,st为智能体的最终状态,g为目标状态,δ0为目标的初始范围,δ1为第一次更新后的目标范围。
17、步骤5.2、范围及奖励函数更新之后,能够引导智能体向着最新的目标范围前进,记录并收集轨迹数,再通过ppo训练。
18、步骤5.3、当关于新目标范围内外的轨迹数量比例大于参数ρ时,能够实现更新目标范围,从目标范围δ1更新为δ2,并且奖励函数随之变化,公式如下:
19、
20、式中,st为智能体的最终状态,g为目标状态,δ0为目标的初始范围,δ1为第一次更新后的目标范围,δ2为第二次更新后的目标范围。
21、步骤5.4、循序渐进,逐步引导智能体往最新的目标范围前进,待更新后的目标范围非常靠近目标时,并且关于目标范围的奖励函数公式如下:
22、
23、式中,st为智能体的最终状态,g为目标状态,δ0为目标的初始范围,δi与δi+1分别为第i次和第i+1次更新后的目标范围,δn为第n次更新后的目标范围。
24、一种计算机存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现上述的一种基于动态范围的深度强化学习塑造奖励方法。
25、一种计算机设备,包括储存器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述的一种基于动态范围的深度强化学习塑造奖励方法。
26、有益效果:与现有技术相比,本发明具有如下优点:
27、1、本发明为强化学习大规模的稀疏奖励环境问题提供了一种新的思路,保留了以往方法的优越性,也引入了新思路的先进性,对于稀疏奖励问题具有重要的参考意义。
28、2、本发明提出的动态范围,对于何时进行更新范围以及重新塑造奖励函数进行了合理的设计,对于稀疏奖励这一经典问题具有重要的研究意义。
29、3、本发明的最终结果是促进强化学习算法性能的大量提升,再结合其它辅助算法,比如hindsight experience replay算法,可以更好的提升深度强化学习算法性能,为解决大规模稀疏奖励环境问题的发展提供了有效的理论基础。
技术特征:
1.一种基于动态范围的深度强化学习塑造奖励方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于动态范围的深度强化学习塑造奖励方法,其特征在于,所述步骤1具体为:通过距离函数d(x,y)采集强化学习环境中的外部信息,形成对环境的初步勘察,记录环境规模大小。
3.根据权利要求1所述的一种基于动态范围的深度强化学习塑造奖励方法,其特征在于,所述步骤2具体为:设定关于目标的初始范围以及塑造奖励函数;关于目标的初始范围用δ0表示,塑造奖励函数公式如下:
4.根据权利要求1所述的一种基于动态范围的深度强化学习塑造奖励方法,其特征在于,所述步骤3具体为:
5.根据权利要求1所述的一种基于动态范围的深度强化学习塑造奖励方法,其特征在于,所述步骤5具体为:
6.一种计算机存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现如权利要求1-5中任一项所述的一种基于动态范围的深度强化学习塑造奖励方法。
7.一种计算机设备,包括储存器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1-5中任一项所述的一种基于动态范围的深度强化学习塑造奖励方法。
技术总结
本发明公开了一种基于动态范围的深度强化学习塑造奖励方法,步骤如下:对稀疏奖励环境通过距离函数进行预处理,设定关于目标的初始范围以及塑造奖励函数,利用深度强化学习算法PPO进行训练,记录智能体在关于目标范围内外的轨迹数,根据智能体在关于目标范围内外的轨迹数量比例,更新目标范围以及重新塑造奖励函数。本发明为强化学习大规模的稀疏奖励环境问题提供了一种新的思路,保留了以往方法的优越性,也引入了新思路的先进性,对于稀疏奖励问题具有重要的参考意义;本发明提出的动态范围,对于何时进行更新范围以及重新塑造奖励函数进行了合理的设计,对于稀疏奖励这一经典问题具有重要的研究意义。
技术研发人员:孔燕,魏俊锋
受保护的技术使用者:南京信息工程大学
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!