一种两方联邦学习中进行隐私保护的方法、系统及终端与流程
本技术涉及隐私数据保护,特别是涉及一种两方联邦学习中进行隐私保护的方法、系统及终端。
背景技术:
1、随着智能终端设备的快速普及,大量个人信息数据被各种网络平台所采集,因此,对于个人隐私数据的保密越来越受到关注,如何进行隐私保护,是个重要的技术问题。
2、目前对个人信息进行隐私保护的方法,通常是采用服务端和客户端的方式,基于非交互零知识证明的同态加密系统对联邦学习的保密性进行增强。具体地,在本地客户端对模型参数进行加密处理,然后发送到服务端,由服务端对加密后的模型参数进行聚合,接着再对聚合后的数据解密,最后再计算得到新的全局模型。比如:所有客户端持有公钥和私钥,服务端只持有公钥,每次随机选择一部分客户端参与训练,本地客户端将加密后的数据发送给服务端后,服务端对加密后的模型参数进行聚合,聚合后的全局私密参数直接发送到客户端,由客户端对加密的全局私密参数进行解密。
3、然而,目前对个人信息进行隐私保护的方法,主要是采用服务端和客户端的方式,这种应用场景下通常包括多个用户参与,且存在服务器。实际中还有很多只有两个参与者,且两者直接进行通讯,不经过服务器的情景,现有技术中的方法就不适用于这种两个参与者的情况,也就是两方联邦学习的情景。因此,亟需提供一种两方联邦学习中进行隐私保护的方法。
技术实现思路
1、本技术提供了一种两方联邦学习中进行隐私保护的方法、系统及终端,以解决现有技术中的采用服务端和客户端的方式不适用于两方联邦学习的问题。
2、为了解决上述技术问题,本技术实施例公开了如下技术方案:
3、一种两方联邦学习中进行隐私保护的方法,所述方法包括:
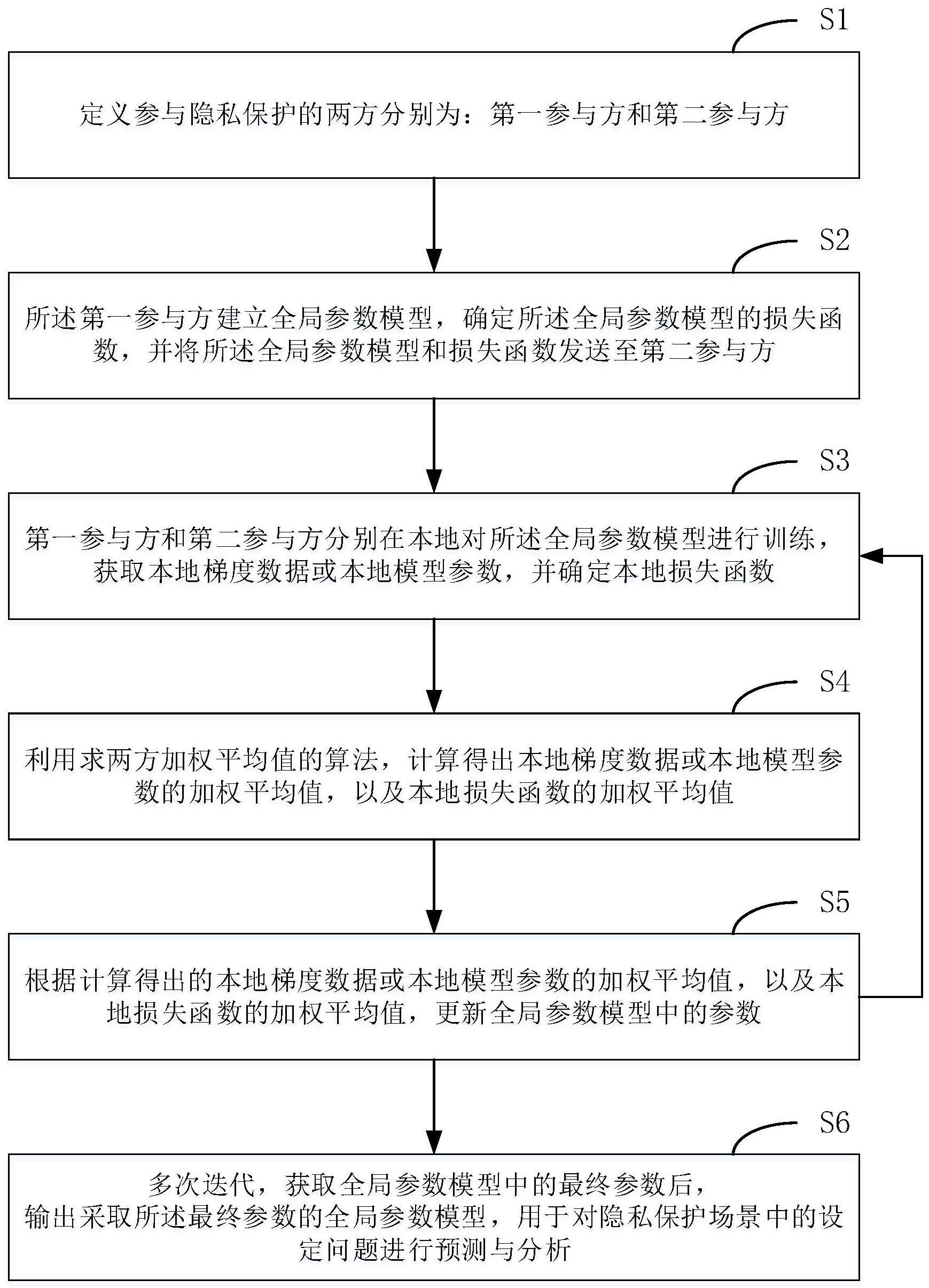
4、s1:定义参与隐私保护的两方分别为:第一参与方和第二参与方,隐私数据包括:第一参与方数据个数、第二参与方数据个数以及联邦学习参数,所述联邦学习参数为本地梯度数据或本地模型参数;
5、s2:所述第一参与方建立全局参数模型,确定所述全局参数模型的损失函数,并将所述全局参数模型和损失函数发送至第二参与方;
6、s3:第一参与方和第二参与方分别在本地对所述全局参数模型进行训练,获取本地梯度数据或本地模型参数,并确定本地损失函数;
7、s4:利用求两方加权平均值的算法,计算得出本地梯度数据或本地模型参数的加权平均值,以及本地损失函数的加权平均值;
8、s5:根据计算得出的本地梯度数据或本地模型参数的加权平均值,以及本地损失函数的加权平均值,更新全局参数模型中的参数;
9、根据更新后的参数,重复执行以上步骤s3-s5,直到达到设定的迭代停止条件为止,并获取全局参数模型中的最终参数;
10、s6:输出采取所述最终参数的全局参数模型,用于对隐私保护场景中的设定问题进行预测与分析。
11、可选地,所述设定的迭代停止条件为:迭代次数达到预设迭代次数,或者,全局损失函数收敛。
12、可选地,所述利用求两方加权平均值的算法,计算得出本地梯度数据或本地模型参数的加权平均值,以及本地损失函数的加权平均值,包括:
13、定义第一参与方有n1个数据,第二参与方有n2个数据,每个数据均有多个分量,当计算本地梯度数据的加权平均值时,多个分量为本地梯度数据和本地损失函数,当计算本地模型参数的加权平均值时,多个分量为本地模型参数和本地损失函数;
14、通过乘以相同的倍数,第一参与方和第二参与方分别将各自的相关数据转化为整数;
15、由所述第一参与方生成概率公钥加密算法密钥,并发送对应公钥至第二参与方;
16、所述第一参与方将其数据个数以及转化为整数的数据加密后发送至第二参与方;
17、第二参与方将其数据个数以及转化为整数的数据加密,并在密文上对第一参与方和第二参与方的对应数据个数的乘积、对应转化为整数数据的乘积进行随机处理,并将随机处理后的数据发送至第一参与方;
18、所述第一参与方对随机处理后的数据进行解密和近似求商计算后,发送至第二参与方;
19、根据求商结果以及随机处理后数据的对应关系,第二参与方计算得出数据所有分量的近似平均值,并将所述近似平均值发送至第一参与方。
20、可选地,所述第二参与方将其数据个数以及转化为整数的数据加密,并在密文上对第一参与方和第二参与方的对应数据个数的乘积、对应转化为整数数据的乘积进行随机处理,并将随机处理后的数据发送至第一参与方,包括:
21、所述第二参与方将其数据个数以及转化为整数的数据加密,获取密文;
22、在所述密文上分别计算第一参与方数据个数和第二参与方数据个数乘积的随机数次幂,以及,第一参与方转化为整数的数据与第二参与方转化为整数的数据乘积的随机数次幂,获取随机处理后的数据,其中,任一所述随机数包含有多个素因子;
23、将所述随机处理后的数据发送至第一参与方。
24、可选地,在所述密文上分别计算第一参与方数据个数和第二参与方数据个数乘积的随机数次幂,以及,第一参与方转化为整数的数据与第二参与方转化为整数的数据乘积的随机数次幂,获取随机处理后的数据之后,所述方法还包括:
25、对所述随机数的顺序进行混淆。
26、可选地,对所述随机数的大小进行限制,使所述第一参数对随机处理后的数据进行解密所获取的解密后不同的随机处理后数据的大小近似相等。
27、可选地,所述第一参与方对随机处理后的数据进行解密和近似求商计算后,发送至第二参与方,包括:
28、所述第一参与方对随机处理后的数据进行解密;
29、根据概率公钥加密算法的同态性,计算得出第一参与方和第二参与方的对应数据个数之和、对应转化为整数数据之和分别与不同的随机数相乘后的乘积混淆后的结果;
30、根据设定的误差范围,对乘积混淆后的结果进行近似求商;
31、将近似求商的结果发送至第二参与方。
32、可选地,所述根据求商结果以及随机处理后数据的对应关系,第二参与方计算得出数据所有分量的近似平均值,并将所述近似平均值发送至第一参与方,包括:
33、根据第一参与方与第二参与方将相关数据转化为整数时所乘的倍数、计算两方随机处理后数据的任一随机数、以及加密后数据和混淆后的结果,第二参与方利用分量计算公式,计算得出数据所有分量的近似平均值;
34、将所述近似平均值发送至第一参与方。
35、一种两方联邦学习中进行隐私保护的系统,所述系统包括:
36、定义模块,用于定义参与隐私保护的两方分别为:第一参与方和第二参与方,隐私数据包括:第一参与方数据个数、第二参与方数据个数以及联邦学习参数,所述联邦学习参数为本地梯度数据或本地模型参数;
37、全局参数模型建立模块,设置于所述第一参与方,用于建立全局参数模型,确定所述全局参数模型的损失函数,并将所述全局参数模型和损失函数发送至第二参与方;
38、模型训练模块,设置于第一参与方和第二参与方,用于第一参与方和第二参与方分别在本地对所述全局参数模型进行训练,获取本地梯度数据或本地模型参数,并确定本地损失函数;
39、加权平均计算模块,用于利用求两方加权平均值的算法,计算得出本地梯度数据或本地模型参数的加权平均值,以及本地损失函数的加权平均值;
40、参数更新模块,用于根据计算得出的本地梯度数据或本地模型参数的加权平均值,以及本地损失函数的加权平均值,更新全局参数模型中的参数;
41、迭代模块,用于根据更新后的参数,重复依次启动模型训练模块、加权平均计算模块以及参数更新模块,直到达到设定的迭代停止条件为止,并获取全局参数模型中的最终参数;
42、输出模块,用于输出采取所述最终参数的全局参数模型,用于对隐私保护场景中的设定问题进行预测与分析。
43、一种终端,所述终端包括:处理器以及与所述处理器通信连接的存储器,其中,
44、所述存储器中存储有可被所述处理器执行的指令,所述指令被所述处理器执行,以使所述处理器能够执行如上任意一项所述的两方联邦学习中进行隐私保护的方法。
45、本技术的实施例提供的技术方案可以包括以下有益效果:
46、本技术提供一种两方联邦学习中进行隐私保护的方法,该方法首先定义参与隐私保护的两方分别为:第一参与方和第二参与方,其次第一参与方建立用于设定问题的全局参数模型,确定该模型的损失函数,并把全局参数模型和损失函数发送至第二参与方,两方分别在本地对全局参数模型进行训练,获取到本地梯度数据或本地模型参数,并确定本地损失函数,然后利用求两方加权平均值的算法,计算得出本地梯度数据或本地模型参数的加权平均值,以及本地损失函数的加权平均值,并利用这些加权平均值更新全局参数模型中的参数,并进行多次迭代直到确定最终参数,并输出采用最终参数的全局参数模型,利用该模型进行问题预测与分析。本实施例针对两方联邦学习的场景,提供一种隐私保护的方法,利用求两方加权平均值的算法,计算得出联邦学习参数的加权平均值以及损失函数的加权平均值,该求两方加权平均值的算法能够在数据拥有多个分量的情况下,更加安全地计算两方的加权平均值,从而有效提高隐私数据的保密性。而且该方法基于两方联邦学习而设定,能够解决现有技术中采用服务端和客户端的方式不适用于两方联邦学习的问题。
47、本技术还提供一种两方联邦学习中进行隐私保护的系统,该系统主要包括:定义模块、全局参数模型建立模块、模型训练模块、加权平均计算模块、参数更新模块、迭代模块以及输出模块。该系统针对两方联邦学习而设置,通过全局参数模型建立模块,建立用于隐私保护的模型,通过模型训练模块、加权平均计算模块、参数更新模块、迭代模块的设置,获取到用于全局参数模型的最终参数,将该最终参数用于对设定问题进行预测和分析,从而有效解决现有技术汇总采用服务端和客户端的方式不适用于两方联邦学习的问题。
48、通过加权平均计算模块的设置,本系统利用求两方加权平均值的算法,计算得出联邦学习参数的加权平均值以及损失函数的加权平均值,该求两方加权平均值的算法能够在数据拥有多个分量的情况下,更加安全地计算两方的加权平均值,从而有效提高隐私数据的保密性。
49、本技术还提供一种终端,该终端也具有如上两方联邦学习中进行隐私保护的方法和系统相应的技术效果,在此不再赘述。
50、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!