一种应用于机器翻译的强化学习训练方法与流程
本发明涉及一种机器翻译技术,具体为一种强化学习训练方法,可以使得所训练的机器翻译性能有所提升。
背景技术:
1、神经网络机器翻译通常采用编码器-解码器结构,实现对变长输入句子的建模。编码器实现对源语言句子的"理解",形成一个特定维度的浮点数向量,之后解码器根据此向量逐字生成目标语言的翻译结果。在神经网络机器翻译发展初期,广泛采用循环神经网络(rnn,recurrent neural network)作为编码器和解码器的网络结构。该网络擅长对自然语言建模,以长短期记忆网络lstm(long short-term memory networks)和门控循环单元网络gru(gated recurrent unit networks)为代表的rnn网络通过门控机制“记住”句子中比较重要的单词,让“记忆”保存比较长的时间。2017年,有两篇工作相继提出了采用卷积神经网络(cnn,convolutional neural network)和自注意力网络(transformer)作为编码器和解码器结构,它们不但在翻译效果上大幅超越了基于rnn的神经网络,还通过训练时的并行化实现了训练效率的提升。目前业界机器翻译主流框架采用自注意力网络(transformer),该网络不仅应用于机器翻译,在自监督学习等领域也有突出的表现。
2、早期的编码器-解码器框架,就是使用卷积神经网络编码源语言序列,循环神经网络转换模型中间向量为目标语言。其中注意力机制在神经机器翻译中的成功应用,将机器翻译带上了一个新的高度。注意力机制模仿了人类翻译的过程,模型在解码时,并不像循环神经网络那样,将所有单词视同一律,而是为不同单词赋予不同的权重,与当前时刻翻译的词相关性高的词,将获得较高的注意力权重,可以看出,注意力机制的引入,缓解了循环神经网络的不足。
3、虽然现在已有的神经机器翻译模型已经在训练速度和性能方面达到一个显著的提升,但是仍存在很多问题。最明显也是最令人关注的两个问题分别是训练和解码目标不一致和暴露偏执问题。针对该问题,已有研究人员通过使用强化学习算法开发对应机器翻译模型训练范式,能够有效的避免这两个问题。
4、虽然现在已经存在着一些针对机器翻译的强化学习训练方法,比如mrt训练,但是他们存在以下不足:
5、1)使用reinforce算法来进行训练。其算法已经在游戏领域中被证明训练较为不稳定,模型收敛速度慢;
6、2)没有针对机器翻译的高维表示做出调整。现有的方法都是直接把对应的强化学习算法直接套用在机器翻译训练过程里面。但实际上,机器翻译中的表示维度要和其他任务场景中的表示维度要高的很多,因此要针对该问题做出特定的处理;
7、3)训练的结果随机性较强。由于现有的一些方法都是基于采样算法(含有随机过程)来进行训练机器翻译模型,导致其训练结果随机性较强。
技术实现思路
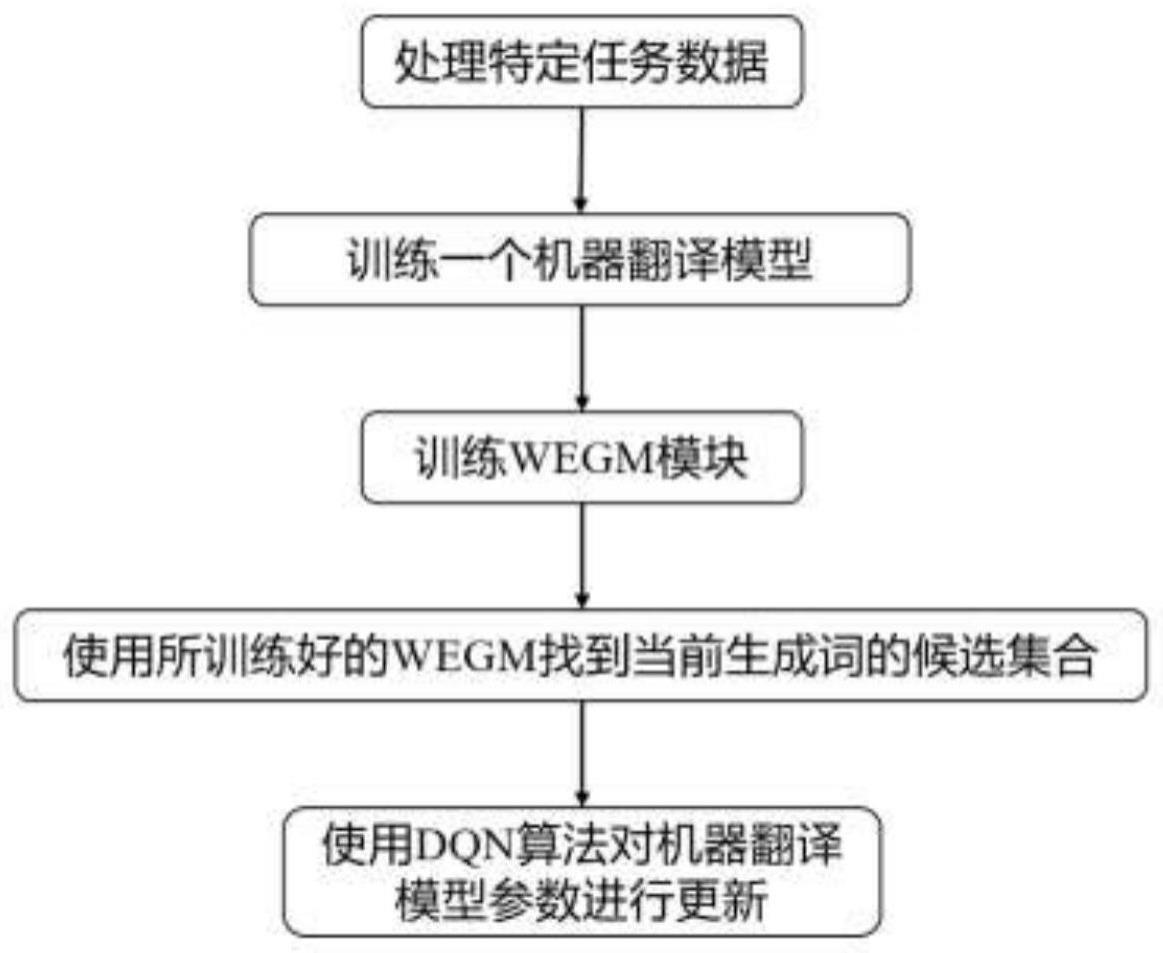
1、针对现有机器翻译模型中强化学习训练时候基于算法薄弱、高维灾难和随机性较强的问题,导致机器翻译在强化学习训练范式下难以获得进一步的性能提升等不足,本发明要解决的问题是提供应用于机器翻译的强化学习训练方法,通过wegm模块可以预测对应生成词的词嵌入表示,进一步使用k近邻算法来搜索候选词,再进行强化学习训练,以获得更好的性能,在强化学习的训练过程中能够使得机器翻译模型学习的更加充分,性能获得进一步提升。
2、本发明提供一种应用于机器翻译的强化学习训练方法,包括以下步骤:
3、1)使用双语语料训练基于自注意力机制的神经机器翻译模型,使其达到收敛状态;
4、2)在机器翻译模型顶层加入额外的词嵌入生成模块,用来预测当前步中所要生成词的词嵌入;
5、3)基于kl散度来训练词嵌入生成模块,其对应的目标表示为标准nmt经过argmax函数计算出来的词,并对应在词嵌入层里面的编码表示;
6、4)继续训练该机器翻译模型,基于训练好的词嵌入生成模块来预测当前步中的生成词的词向量;
7、5)使用生成的词向量在机器翻译模型的词嵌入层中使用k近邻算法来获取所有候选生成词,并使用强化学习算法计算每个候选生成词的价值,最终根据所计算的价值来选定对应最后生成词,并更新模型参数。
8、步骤1)中,使用所拥有的双语语料训练教师模型表示为:
9、teachermodel=modeltrain(s,t)
10、其中modeltrain为模型训练函数,表示训练一个机器翻译模型,其所训练的机器翻译模型已经达到收敛状态,继续训练已经无法达到性能上的提升。
11、步骤2)具体为:
12、设双语语料中的源语集合为s=(s0,s1,s2,……,sm),目标语集合为t=(t0,t1,t2,……,tm),并在模型的最顶层加入一个前馈神经网络,其输出是一个对应的表示,对应当前位置生成词的词嵌入向量,该前馈神经网络作为词嵌入生成模块。
13、基于kl散度来训练词嵌入生成模块的参数,具体为:
14、301)输入当前源语和目标语,在t时刻机器翻译模型的解码器最后一层输出的隐含层表示为lt;
15、302)使用机器翻译模型中解码器最后一层输出的隐含层表示lt作为词嵌入生成模块的输入,获得对应生成词的词嵌入:
16、
17、其中wegm(·)为词嵌入生成函数;
18、303)根据机器翻译原始预测的概率分布获得基于argmax的预测词,并在模型的词嵌入层查询对应的词嵌入向量:
19、wt=argmax(p(wt|w<t,s))
20、
21、其中p(·|·)表示当前词预测的概率分布,emb(·)表示机器翻译模型的词嵌入层,wt表示当前t时刻生成词,w<t表示t时刻前面生成所有词;
22、304)基于kl散度计算当前词嵌入生成模块的损失:
23、
24、其中,为参考译文中对应位置词的编码;
25、305)根据所计算得到的当前词嵌入生成模块的损失进行反向梯度传播,来更新词嵌入生成模块中的参数,得到对应生成词的词嵌入编码表示。
26、步骤5)是使用步骤4)预测的词嵌入向量进行搜索对应候选生成词,具体如下:
27、501)使用k领近算法根据词嵌入生成模块预测的词向量搜索出候选词;
28、502)使用强化学习中基于值估计算法计算候选词的q值,并进行排序,选择q值最大的候选词作为当前生成词;
29、503)根据所选择的当前生成词所对应的概率构建强化学习损失值:
30、
31、其中表示根据q值选择的当前生成词,p(·)表示当前生成词预测的概率,q(·)表示价值函数。
32、根据所计算出来的lrl进行反向计算模型参数梯度,更新机器翻译模型参数,实现强化学习训练。
33、本发明具有以下有益效果及优点:
34、1.相比于之前方法使用的reinforcer算法,本发明使用过了dqn算法,在训练方面上更加具有稳定性;
35、2.针对机器翻译存在的高维灾难问题,本算法提出了wegm模块,可以预测当前生成词的词嵌入向量,并根据所预测的嵌入向量来搜索候选词集合,使得显著降低候选词规模;
36、3.本发明并没有使用采样算法,因此相对于之前的方法,本发明所训练获得的结果更加具有稳定性。
- 还没有人留言评论。精彩留言会获得点赞!