一种高速列车虚拟驾驶速度曲线的自动生成方法
本发明涉及交通控制,尤其涉及一种高速列车虚拟驾驶速度曲线的自动生成方法。
背景技术:
1、高铁的自动驾驶技术是其运行控制的关键,在高铁尚未建成之前,对其进行理论研究具有非常重要的前瞻性。而高速列车驾驶数据是自动驾驶研究的基础,针对暂未建成的高铁线路,无法采集到真实的高速列车驾驶数据。
2、目前采集高速列车驾驶数据主要依靠车载传感器或人工记录,在实际操作中存在着数据获取难度大、采集周期长、安全风险高、数据保护难度大等问题,同时采集设备、人力、数据存储和处理、维护以及风险等方面成本较高。此外,实际采集到的列车驾驶数据相对于其他领域的数据来说数量较小,且受自然条件约束,难以获得任意环境下的驾驶数据,导致数据类型较为单一。
3、综上,如何解决实际高速列车数据采集周期长、成本高和数据量有限的问题,并能获取供于高铁列车控制研究的驾驶数据,是目前本领域技术人员急需解决的问题。
技术实现思路
1、针对上述问题,本发明提供一种高速列车虚拟驾驶速度曲线的自动生成方法,无需依靠实际数据,发挥虚拟空间的可拓展性和大数据技术,通过条件筛选从大量虚拟数据中提取一定量优质虚拟数据,为获取暂未建成高铁线路的列车驾驶数据带来新的解法。
2、为了实现上述的技术目的,本发明所采用的技术方案为:
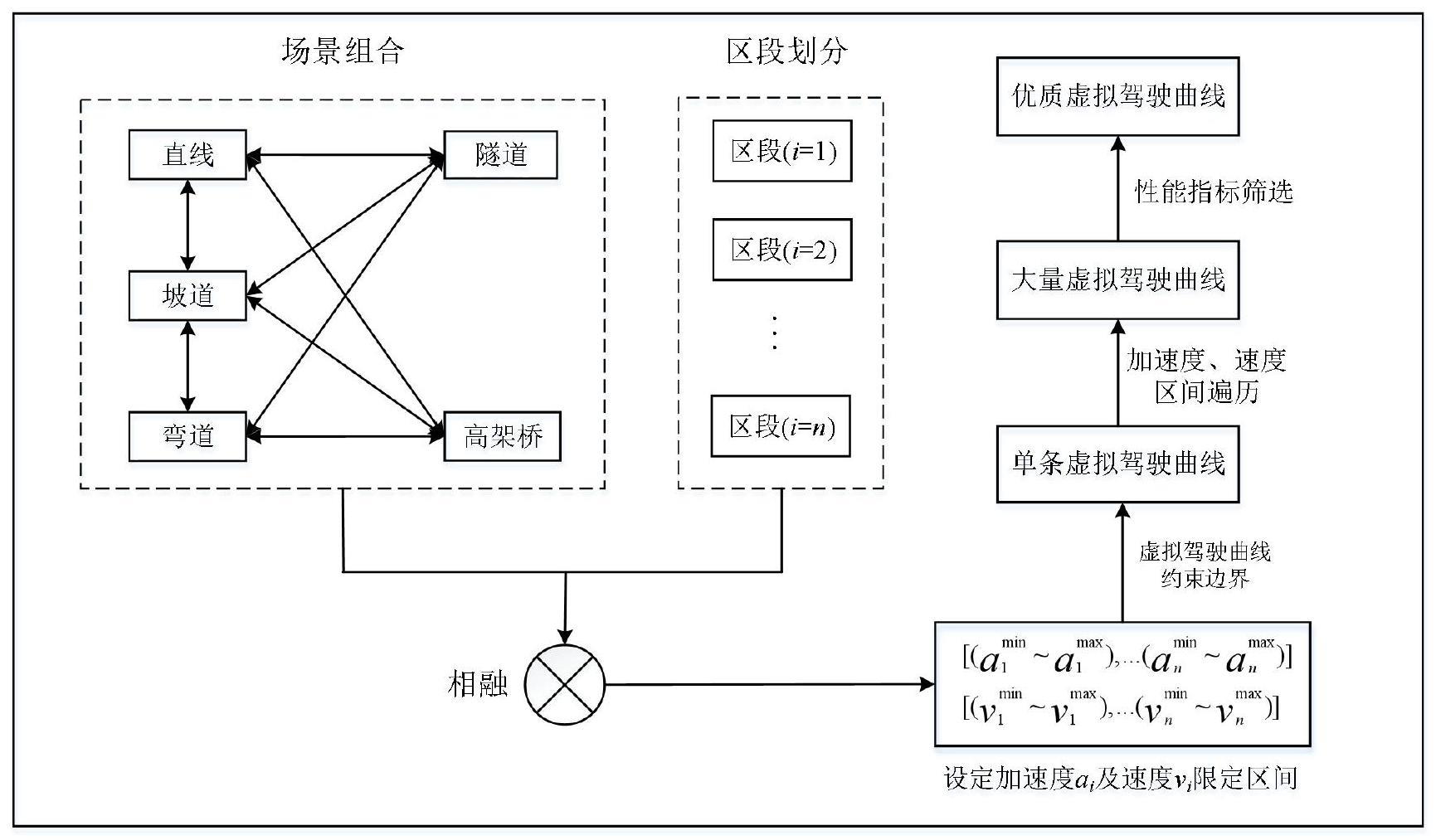
3、一种高速列车虚拟驾驶速度曲线的自动生成方法,包括以下步骤:
4、s1:在虚拟空间中搭建高铁虚拟线路特征模型;
5、s2:搭建高速列车驾驶模型,并设定模型的约束条件,确定高速列车虚拟驾驶速度曲线的边界状态,并得到单条虚拟驾驶速度曲线;
6、s3:利用大数据技术生成大量高速列车虚拟驾驶速度曲线;
7、s4:设定高速列车虚拟驾驶速度曲线的评价指标;
8、s5:对所有高速列车虚拟驾驶速度曲线做统计分析,根据性能评价指标筛选出性能优异的虚拟驾驶速度曲线。
9、进一步的,所述高铁虚拟线路特征模型如下:
10、
11、其中,p为高速列车驾驶智能体;λi代表将列车线路划分为i个区段;e为多变量虚拟场景集成体;ε代表影响列车行车的自然因素,包含天气、温度和风力;功能函数integrate()将线路区段、虚拟场景和自然因素进行集成;分别表示直道场景、弯道场景、坡道场景、隧道场景和高架桥场景依次分布于线路第i个区段时的集合;merge()将si,ci,ri,ti,vi进行多元场景融合。
12、进一步的,s2中将高铁虚拟线路划分为若干个子区段,对每个区段设定相应的速度和加速度限制区间,根据动力学原理确定虚拟驾驶速度曲线的两个边界状态,生成单条列车驾驶曲线。
13、进一步的,s2中单条列车驾驶曲线的具体生成方法,包括以下步骤:
14、s21:列车从初始点pbegin出发,在i=1区段以加速度a1做匀变速运动,其中在第j时刻列车匀变速运动的路程表示为
15、s22:经过变速时间秒后达到当段饱和速度v1,其中在第j时刻列车匀速运动的路程表示为此时loc1为该条列车驾驶曲线在i=1区段的变速截止点;
16、s23:接着列车以v1匀速行驶至区段分界点p1,该阶段匀速运行时间为
17、s24:在后续i≤n区段中循环s21-s23;
18、当列车到达近站点pnear时,列车以加速度an做匀变速运动,其中最终列车瞬时速度为0,即到达终点站pend,列车全程运行时间为其中ttotal为列车虚拟驾驶曲线运行总时长;表示第i区段列车变速运行时间;表示第i区段列车匀速行驶运行时间。
19、进一步的,,s3中利用大数据技术生成大量高速列车虚拟驾驶速度曲线,具体如下:
20、根据每个驾驶区段上设有相应的加速度限制区间与速度限制区间分别选取分布频率μa,μv划分限制区间,使得在每个区段上加速度a与速度v的选择概率分别为则单个区段存在μa×μv种曲线情况,把每个区段进行累乘,则自动生成条完整的高速列车虚拟驾驶曲线。
21、进一步的,s4中设定的高速列车虚拟驾驶速度曲线的评价指标包括:
22、1)列车驾驶能耗ectrain,表达式如下:
23、
24、
25、式中:ectrain为能耗量kj/(t·km);vavg为第i个运行区段内的平均速度;xi为第i个运行区段的距离;k和c表示与列车相关的预设系数;δxi表示为第i个运行区段长度;tvar为第i个区段运行的变速时间;tuni为第i个区段运行的匀速时间;
26、2)乘客舒适度δcomfort,表达式如下:
27、
28、式中:δ|a|表示第i区段的加速度变化值;
29、3)曲线性能ξcurve
30、先将能耗量ectrain和舒适度δcomfort分别进行归一化处理;归一化表达式如下:
31、
32、式中:x*为归一化后的指标数值,x为归一化前的指标数值,为指标数值的最小值,为指标数值的最大值;
33、接着将列车运行时间内每秒所包含的曲线赋予ectrain和δcomfort各占50%的比例加权评价曲线性能,表达式如下:
34、
35、其中,ξcurve代表量化后具备评估驾驶曲线性能的指标;t=t0,...,tn表示列车运行总时间分布范围;
36、最后在每个运行时间上都能筛选出最优的列车驾驶曲线。
37、进一步的,s5具体步骤如下:
38、对所生成的高速列车虚拟驾驶速度曲线做统计分析,确定列车运行时间所覆盖的范围为时间跨度为δtnumber,统计每一秒时间长度内包含的曲线数量,进而得到δtnumber组列车虚拟驾驶速度曲线,根据曲线性能指标ξcurve综合评估每组曲线性能,从而提取每一秒上性能最佳的一条曲线,最终筛选出δtnumber条高速列车虚拟驾驶速度曲线。
39、优选的,每条高速列车虚拟驾驶速度曲线均以0.1秒的采样间隔进行实时跟踪。
40、在上述基础上,本发明还提供了一种计算机可读的存储介质,所述的存储介质中存储有至少一条指令、至少一段程序、代码集或指令集,所述的至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行实现上述的高速列车虚拟驾驶速度曲线的自动生成方法。
41、采用上述的技术方案,本发明与现有技术相比,其具有的有益效果为:
42、1)与现有技术相比,本发明的高速列车大量虚拟驾驶速度曲线的自动生成方法基于alphazero思想,无需依靠真实数据,自定义虚拟路线,设定区段约束条件,利用大数据技术自动生成大量的高铁虚拟驾驶速度曲线,为获取暂未建成高铁线路的高速列车驾驶数据提供一种通用、低成本和高效率的方式;
43、2)本发明生成大量高速列车虚拟驾驶速度曲线,通过设定评估指标筛选出一定量性能优异的曲线,这种优中选优的方式有助于提高虚拟曲线的性能。
44、3)每条高速列车虚拟驾驶速度曲线均以0.1秒的采样间隔进行实时跟踪,有助于提高曲线精确性。
- 还没有人留言评论。精彩留言会获得点赞!