一种融合空间运动和表观特征学习的多目标跟踪方法与流程
本发明涉及目标跟踪,更具体的说是涉及一种融合空间运动和表观特征学习的多目标跟踪方法。
背景技术:
1、多目标跟踪是利用计算机视觉技术对视频中的目标进行持续跟踪,通过对输入的视频图像进行处理,得到多个目标,并对目标的外观特征、位置、运动状态等信息进行计算分析,最终得到连续的运动轨迹。在深度学习技术成熟之前,传统的多目标跟踪方法,建立高斯混合模型或隐马尔可夫随机场模型以构建生成外观模型,然后使用基于贝叶斯理论的模型或基于局部/全局数据关联的模型进行持续的目标跟踪。
2、现有方法通过先检测出目标;再预测出目标;计算检测目标与预测目标的交并集;匹配检测目标与预测目标。虽然现有方法整体来说能产生很好的跟踪效果,但是没有考虑长期遮挡使目标丢失的情况,也没有考虑身份标识管理的策略,导致产生过多的身份id的情况,因此现有的多目标追踪方法存在识别效果差,追踪效果差的问题,
3、因此,如何提高多目标追踪的识别效果和追踪效果是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种融合空间运动和表观特征学习的多目标跟踪方法,通过使用基于卷积神经网络的深度学习算法解决多目标跟踪效果差的问题,实现轨迹输出更加精确。
2、为了实现上述目的,本发明采用如下技术方案:
3、一种融合空间运动和表观特征学习的多目标跟踪方法,包括以下步骤:
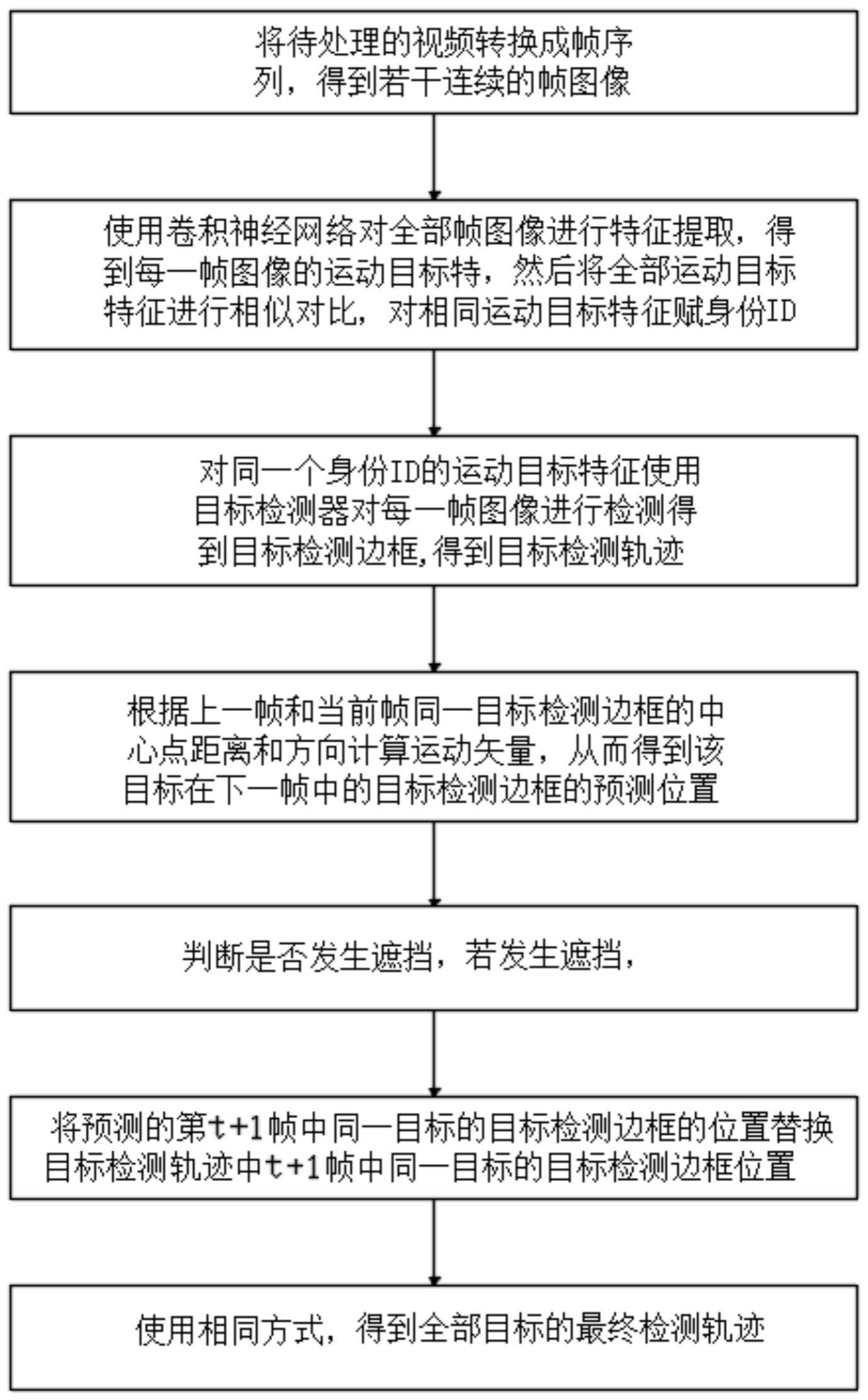
4、s1:获取待处理的视频,并将视频转换成帧序列,得到若干连续的帧图像;
5、s2:使用卷积神经网络对全部帧图像进行特征提取,得到每一帧图像的运动目标特征,将全部运动目标特征进行相似对比,对相同的运动目标特征赋一个相同的身份id,得到所有携带身份id的运动目标特征;
6、s3:使用目标检测器对每一个身份id的运动目标对应的所有帧图像进行检测得到目标检测边框,利用运动目标的身份id与目标检测边框进行目标边框的关联与追踪,得到每一个运动目标在其对应的连续帧图像中的目标检测轨迹,获得全部运动目标的目标检测轨迹;
7、s4:遍历每一个运动目标对应的所有帧图像,对全部运动目标的目标检测轨迹进行校验和调整,获得每个运动目标的最终检测轨迹。
8、优选地s2中,卷积神经网络包括若干多层神经网络,每层神经网络包括若干二维平面,每个平面由若干独立神经元构成;进行特征提取的过程为:
9、s21:输入每一帧图像,通过三个可训练的滤波器和可加偏置进行卷积,卷积后在第一卷积层c1产生三个特征映射图;
10、s22:将特征映射图中每组的四个像素依次进行求和、加权值和加偏置,通过一个s型生长曲线函数得到三个第一采样层s2的特征映射图;
11、s23:三个第一采样层s2层的特征映射图通过滤波到第二卷积层c3,经过卷积产生三个特征映射图;
12、s24:第二卷积层c3的特征映射图中每组的四个像素依次进行求和、加权值和加偏置,通过一个s型生长曲线函数得到三个第二采样层s4的特征映射图;
13、s25:光栅化第二采样层s4的特征映射图的像素值,并连接成一个向量输入到传统的神经网络,输出运动目标特征。
14、其中,c1层是是一个卷积层,由6个特征图构成,特征图中每个神经元与5*5的邻域滤波器相连,c1有156个可训练参数,(每个滤波器包括5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数);s2层是一个下采样层,有6个14*14的特征图,特征图中的每个单元与c1层中相对应特征图的2*2邻域相连接,s2层有12个(6*(1+1)=12)可训练参数;c3层是一个卷积层,它同样通过5x5的卷积核去卷积层s2,然后得到的特征图就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征图;s4层是一个下采样层,由16个5*5大小的特征图构成,特征图中的每个单元与c3中相应特征图的2*2邻域相连接,跟c1和s2之间的连接一样。
15、上述技术方案的技术效果为,特征映射结构采用影响函数核小的s型生长曲线函数作为卷积网络的激活函数,使得特征映射具有位移不变性,此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。
16、下采样层s2的作用是,当在一帧图像中出现两个运动的物体,两个运动的物体结构颜色以及位置不同,在该帧图像后的若干帧中均出现该两个物体,则该同一运动物体的运动目标特征相同,只是该运动目标特征在该帧图像后的若干帧中位置发生变化,则对两个运动的物体的运动目标特征赋身份id,给定一个身份编号。
17、优选地,卷积层c1和卷积层c3为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,该局部特征被提取后,同时获得局部特征与其他特征间的位置关系;采样层s2和采样层s4是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。
18、优选地,卷积神经网络中的特征提取层都连接一个计算层,通过计算层求局部平均,并进行二次提取。卷积神经网络中的每一个作为特征提取层的卷积层都紧跟着一个用来求局部平均与二次提取的计算层。
19、上述技术方案的技术效果为,通过使用卷积神经网络能够精确提取出每一帧图像的运动目标特征,同时提取速率快,提取精度高。
20、优选地,s3中的目标检测器使用dpm目标检测器,先计算梯度方向直方图,然后用svm训练得到运动目标的梯度模型,使用梯度模型完成目标分类,实现模型和目标匹配,得到目标检测边框。
21、上述技术方案的技术效果为,dpm目标检测器在特征层面对经典的hog目标检测器特征进行了扩展,也使用了滑动窗口方法,基于svm进行分类,其核心思想是将待检测目标拆分成一系列部件,把检测一个复杂目标的问题转换成检测多个简单部件的问题。例如,将检测汽车转换成分别检测窗子、车体和车轮这几个部件,使得输出的目标检测边框更加贴合运动目标。
22、优选地,s4的具体过程为:
23、s41:选取当前帧图像,根据上一帧图像和当前帧图像中同一目标检测边框的中心点距离和方向计算运动矢量,从而得到该运动目标在下一帧中的预测目标检测边框;
24、s42:将上一帧图像中同一运动目标的目标检测边框用细线框标出,将当前帧图像中的同一运动目标的目标检测边框用粗线框标出,结合这两帧图像中同一运动目标的目标检测边框信息,预测下一帧图像中同一运动目标的目标检测边框的位置,得到预测目标检测边框;
25、s43:利用预测目标检测边框和同一运动目标的目标检测轨迹中下一帧图像中的目标检测边框大小进行位置重合计算,判断是否发生遮挡;若目标检测边框的大小和位置均相同则不发生遮挡,否则判断发生遮挡;若发生遮挡,用预测的下一帧图像中同一运动目标的预测目标检测边框的位置替换目标检测轨迹中下一帧图像中同一运动目标的目标检测边框的位置;如果未发生遮挡,则下一帧中的目标检测边框不进行调整;
26、s44:如果存在下一帧图像,则将下一帧图像作为当前图像,并返回s41,否则遍历结束,输出全部运动目标的最终检测轨迹。
27、上述技术方案的技术效果为,在实际检测过程中,运动目标可能出现遮挡,被遮挡的运动目标只有部分运动目标特征出现在帧图像上,进而被遮挡的运动目标特征被检测到的目标检测边框小于实际运动目标特征在实际场景中的位置,若直接使用目标检测边框作为最终检测结果,造成检测结果不精确,使用预测的下一帧图像中同一运动目标的目标检测边框的位置替换目标检测轨迹中下一帧图像中同一运动目标的目标检测边框位置,最终输出更加精确的运动目标的最终检测轨迹。
28、优选地,s4中根据上一帧图像和当前帧图像中同一运动目标的目标检测边框的位置变化,使用微分的方法,以匀速直线运动方式预测下一帧图像的目标检测边框的目标位置,形成目标运动向量和目标预测位置处的目标检测边框,得到下一帧图像中同一运动目标的预测目标检测边框的位置。
29、上述技术方案的技术效果为,通过使用微分的方法,以匀速直线运动方式预测目标位置,提高运动目标特征的预测位置的精度。
30、经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种融合空间运动和表观特征学习的多目标跟踪方法,视频帧序列与独立图像最大的差异即视频帧是连续的,通过应用视频帧序列的连续性,将前一帧特征作为后一帧的特征参考,即第t-1帧中该目标检测框用细线框标出,第t帧中的检测框则用粗线框表示,结合这两帧中该目标的检测框信息,预测第t+1帧中该目标位置,针对目标未出现的情况有目标物离开画面、目标物被遮挡等情况,因此进行目标遮挡判断,通过预测目标的运动轨迹,提前判断是否会出现遮挡,并在遮挡前保存相对完整的目标特征和运动矢量,为遮挡结束后的身份分配提供更可靠的依据,实现输出多个目标的运动轨迹。另外也有新出现在画面中的目标物,这部分可以作为检测特征部分进行提取,可以大大减少检测特征提取对检测器性能的需求,提高追踪效率。本发明中采用卷积神经网络模型检测当前帧中的行人,通过目标检测器进行初步追踪,结合特征向量对初步追踪的结果进行校验,对没有通过校验的轨迹进行再处理,寻找更适合的检测结果,最后得到相对较优的匹配结果,对于目标间遮挡的问题,本发明提出的算法通过预测目标的运动轨迹,提前判断是否会出现遮挡,并在遮挡前保存相对完整的目标特征和运动矢量,为遮挡结束后的身份分配提供更可靠的依据,实现输出多个目标的运动轨迹。
- 还没有人留言评论。精彩留言会获得点赞!